
Contents
Что такое DataHub Project (data catalog)?
DataHub — это каталог данных — платформа метаданных с открытым исходным кодом для modern data stack, основной задачей которой является помощь сотрудникам в обнаружении нужных данных. Первоначально DataHub был создан в LinkedIn, а затем был открыт с открытым исходным кодом под лицензией Apache 2.0.
- GitHub Stars: 6.2k
- Contributors: 262
Канал в телеграме: DataHub Project

DataHub следует архитектуре, основанной на push-уведомлениях, что означает, что он создан для непрерывного изменения метаданных. Модульная конструкция позволяет масштабировать его по мере роста объема данных в любой организации: от одной базы данных под вашим рабочим столом до нескольких центров обработки данных, расположенных по всему миру.
DataHub имеет встроенную интеграцию с различными системами: Kafka, Airflow, MySQL, SQL Server, Postgres, LDAP, Snowflake, Hive, BigQuery и многими другими. Сообщество постоянно добавляет все больше и больше интеграций.
Прием на основе push-уведомлений может использовать предварительно созданный эмиттер или генерировать пользовательские события с помощью нашей платформы.
Зачем нужен каталог данных?
Вот несколько распространенных вариантов использования и выборка видов метаданных, которые обычно требуются:
- Search and Discovery (Поиск и обнаружение данных): схемы данных, поля, теги, информация об использовании.
- Access Control (Контроль доступа): группы контроля доступа, пользователи, политики.
- Data Lineage (Происхождение данных): выполнение конвейера данынх, запросы, журналы API, схемы API.
- Compliance (Соответствие): Таксономия типов аннотаций конфиденциальности / соответствия данных.
- Data Management (Управление данными): конфигурация источника данных, конфигурация приема, конфигурация хранения, политики очистки данных (например, для GDPR «Право на забвение»), политики экспорта данных (например, для GDPR «Право на доступ»).
- AI Explainability, Reproducibility (Объяснимость ИИ, Воспроизводимость): определение функции, определение модели, выполнение тренировочного прогона, постановка проблемы.
- Data Ops: выполнение конвейера, обработанные разделы данных, статистика данных.
- определения правил качества данных, результаты выполнения правил, статистика данных.
Информация по DataHub
Официальная документация: DataHub Docs
GitHub: datahub-project / datahub DataHub: The Metadata Platform for the Modern Data Stack
Установка DataHub
Быстрый запуск DataHub
Вариантов инсталляций в DataHub огромное количество и все связано в первую очередь с различными вариантами конфигурации среды и кучей компонентов, которые участвуют в работе DataHub.
Минимальные рекомендованные системные требования для установки DataHub:
- 2 CPU,
- 8 ГБ RAM,
- 2 ГБ области подкачки и
- 10 ГБ дискового пространства.
Чтобы развернуть DataHub, необходимо выполнить следующие действия. Проверял на Ubuntu, работает. Официальный туториал, по которому выполнял инсталляцию здесь: DataHub Quickstart Guide.
- Установливаем docker, jq и docker-compose. У меня последние версии стояли.
- Запускаем в консоле следующие команды:
|
1 2 3 4 5 6 7 |
sudo python3 -m pip install --upgrade pip wheel setuptools sudo python3 -m pip uninstall datahub acryl-datahub || true # sanity check - ok if it fails sudo python3 -m pip install --upgrade acryl-datahub sudo datahub version # После установки datahub CLI, запускаем команду, которая запустит docker-compose file sudo datahub docker quickstart |
результат:
|
1 2 3 4 5 6 7 8 |
sudo datahub docker quickstart No ~/.datahubenv file found, generating one for you... No Datahub Neo4j volume found, starting with elasticsearch as graph service. To use neo4j as a graph backend, run `datahub docker quickstart --quickstart-compose-file ./docker/quickstart/docker-compose.quickstart.yml` from the root of the datahub repo Fetching docker-compose file https://raw.githubusercontent.com/datahub-project/datahub/master/docker/quickstart/docker-compose-without-neo4j.quickstart.yml from GitHub |
После запустится скачка образов и запуск контейнеров. В конце Вы должны получить следующего типа сообщение:
|
1 2 3 4 |
✔ DataHub is now running Ingest some demo data using `datahub docker ingest-sample-data`, or head to http://localhost:9002 (username: datahub, password: datahub) to play around with the frontend. Need support? Get in touch on Slack: https://slack.datahubproject.io/ |

При заходе по адресу http://localhost:9002/ и авторизации, откроется интерфейс DataHub:
В указанной инсталляции я получил следующие контейнеры:
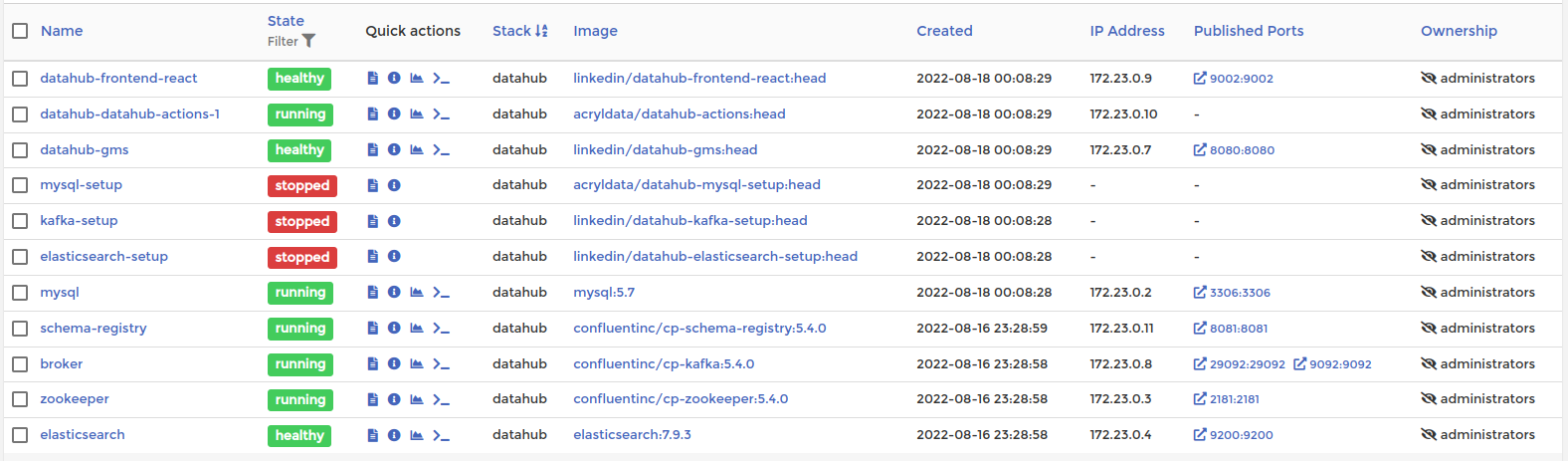
Итого на выходе имеем следующие запущенные контейнеры, необходимые для работы DataHub:
- Контейнер datahub-frontend-react из образа linkedin/datahub-frontend-react:head
- Контейнер datahub-datahub-actions-1 из образа acryldata/datahub-actions:head
- Контейнер datahub-gms из образа linkedin/datahub-gms:head
- Контейнер mysql из образа mysql:5.7
- Контейнер schema-registry из образа confluentinc/cp-schema-registry:5.4.0
- Контейнер broker из образа confluentinc/cp-kafka:5.4.0
- Контейнер zookeeper из образа confluentinc/cp-zookeeper:5.4.0
- Контейнер elasticsearch из образа elasticsearch:7.9.3
Еще один вариант инсталляции quickstart
Почему-то на одном арендованном VPS сервере не запустилась по нормальному инсталляция, как в вышеуказанном примере. При этом по разному пытался извернуться — не помогало. Получал одну из ошибок:
|
1 |
docker-datahub-actions-1 | 2022/11/15 20:55:31 Problem with request: Get "http://datahub-gms:8080/health": dial tcp: lookup datahub-gms on 127.0.0.11:53: server misbehaving. Sleeping 1s |
Помогло несколько дополнительных комманд, которых в официальной документации естестенно не приводится.
Решение нашел в одном из комментариев на сайте: I ran datahub docker quickstart and it keeps restarting the | Troubleshoot
Запускал следующие команды:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
sudo apt-get update && sudo apt-get install git sudo apt-get install \ ca-certificates \ curl \ gnupg \ lsb-release #------------------------------------- sudo apt-get install openjdk-8-jdk apt install python3.8-venv sudo apt install python3-pip python3 -m venv datahub-env # create the environment source datahub-env/bin/activate # activate the environment # Requires Python 3.6+ python3 -m pip install --upgrade pip wheel setuptools python3 -m pip install --upgrade acryl-datahub datahub version |
После этого процесс запустился и все установилось.
Вставка тестовых данных в DataHub Project
После установки DataHub, появится запись:
|
1 2 3 4 |
✔ DataHub is now running Ingest some demo data using `datahub docker ingest-sample-data`, or head to http://localhost:9002 (username: datahub, password: datahub) to play around with the frontend. Need support? Get in touch on Slack: https://slack.datahubproject.io/ |
Запустим команду:
|
1 |
datahub docker ingest-sample-data |
В случае успеха получите информацию:
|
1 |
Pipeline finished successfully; produced 97 events in 9.91 seconds. |
Install минимальной конфигурации DataHub с помощью docker-compose
todo
Обзор архитектуры DataHub
DataHub — это платформа метаданных 3- го поколения , которая обеспечивает обнаружение данных, совместную работу, управление и сквозную наблюдаемость, созданную для современного стека данных. DataHub использует философию «сначала модель», уделяя особое внимание обеспечению функциональной совместимости между разрозненными инструментами и системами.
На рисунке ниже показана высокоуровневая архитектура DataHub.
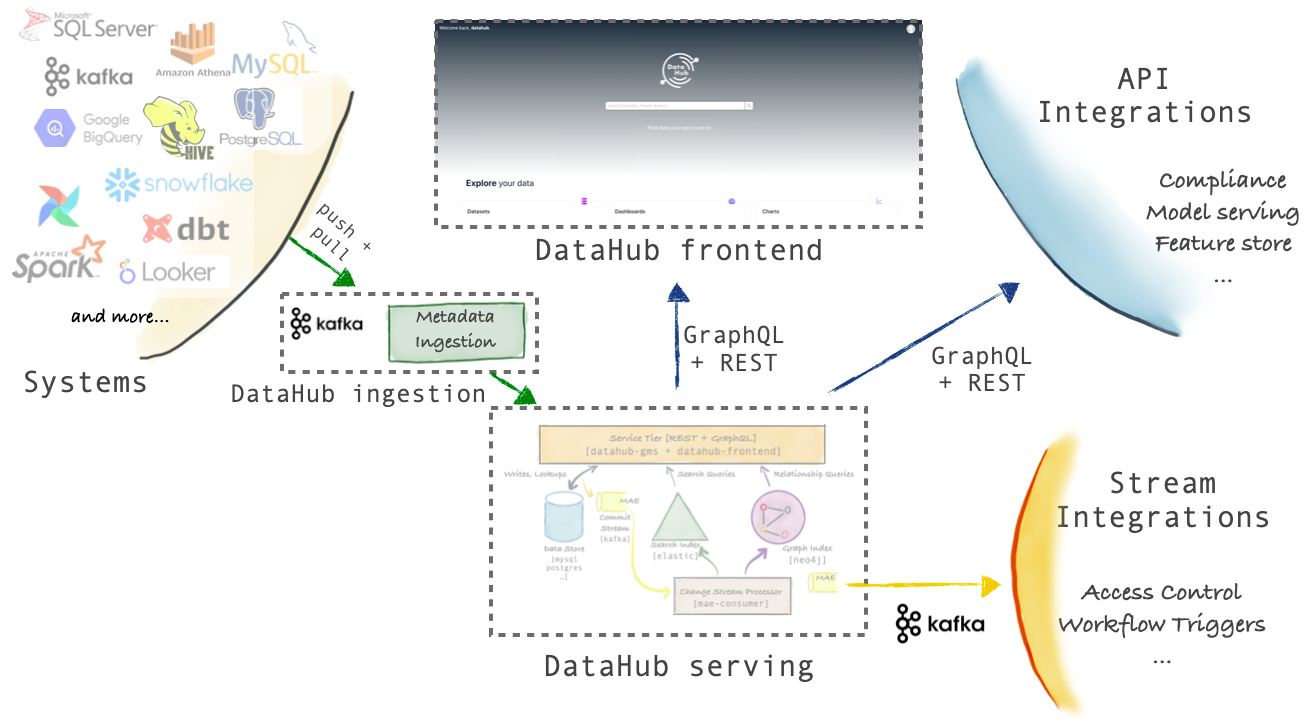
В архитектуре DataHub можно выделить три основных момента.
- Schema-first approach to Metadata Modeling (Схематический подход к моделированию)
Модель метаданных DataHub описывается с помощью языка, не зависящего от сериализации. Поддерживаются как REST, так и GraphQL API. Кроме того, DataHub поддерживает API на основе AVRO поверх Kafka, чтобы сообщать об изменениях метаданных и подписываться на них. Дорожная карта включает в себя веху для поддержки редактирования модели метаданных без кода в ближайшее время, что позволит еще больше упростить использование, сохраняя при этом все преимущества типизированного API. - Stream-based Real-time Metadata Platform (Потоковая платформа)
Инфраструктура метаданных DataHub ориентирована на потоки, что позволяет передавать изменения в метаданных и отражать их в платформе за считанные секунды. Вы также можете подписаться на изменения, происходящие в метаданных DataHub, что позволит вам создавать системы, управляемые метаданными в реальном времени. Например, вы можете создать систему управления доступом, которая может наблюдать за набором данных, который ранее был общедоступным, добавляя новое поле схемы, содержащее PII, и блокировать этот набор данных для проверки контроля доступа. - Federated Metadata Serving (Обслуживание федеративных метаданных)
DataHub поставляется с единой службой метаданных (gms) как часть репозитория с открытым исходным кодом. Однако он также поддерживает федеративные службы метаданных, которыми могут владеть и управлять разные команды — фактически, именно так LinkedIn управляет DataHub внутри. Федеративные службы взаимодействуют с центральным поисковым индексом и графиком с помощью Kafka, чтобы поддерживать глобальный поиск и обнаружение, при этом обеспечивая несвязанное владение метаданными. Такая архитектура очень удобна для компаний, внедряющих data mesh.
Основные компоненты решения DataHub
Платформа DataHub состоит из компонентов, показанных на следующей схеме:

Metadata Store (Хранилище метаданных)
Хранилище метаданных отвечает за хранение сущностей и аспектов, составляющих график метаданных. Это включает предоставление API для приема метаданных, выборку метаданных по первичному ключу, поиск сущностей и выборку отношений между сущностями. Он состоит из службы Spring Java, на которой размещается набор конечных точек API Rest.li, а также MySQL, Elasticsearch и Kafka для основного хранилища и индексирования.
Metadata Models (Модели метаданных)
Модели метаданных — это схемы, определяющие форму сущностей и аспектов, составляющих график метаданных, а также отношения между ними. Они определяются с помощью PDL, языка моделирования, очень похожего по форме на Protobuf, но сериализуются в JSON. Сущности представляют собой определенный класс ресурсов метаданных, таких как набор данных, информационная панель, конвейер данных и т.д. Каждый экземпляр Entity идентифицируется уникальным идентификатором, называемым urn. Аспекты представляют собой связанные пакеты данных, прикрепленные к экземпляру объекта, такие как его описания, теги и т.д.
Ingestion Framework
Ingestion Framework — это модульная, расширяемая библиотека Python для извлечения метаданных из внешних исходных систем (например, Snowflake, Looker, MySQL, Kafka), преобразования их в модель метаданных DataHub и записи в DataHub либо через Kafka, либо с использованием API-интерфейсов хранилища метаданных Rest. напрямую. DataHub поддерживает широкий список исходных соединителей на выбор, а также множество возможностей, включая извлечение схемы, профилирование таблиц и столбцов, извлечение информации об использовании и многое другое.
GraphQL API
API GraphQL предоставляет строго типизированный, ориентированный на объекты API, который упрощает взаимодействие с объектами, составляющими граф метаданных, включая API для добавления и удаления тегов, владельцев, ссылок и многого другого для объектов метаданных! В частности, этот API используется пользовательским интерфейсом (обсуждается ниже) для обеспечения поиска и обнаружения, управления, наблюдения и многого другого.
User Interface (Пользовательский интерфейс)
DataHub поставляется с пользовательским интерфейсом React, включающим постоянно развивающийся набор функций, которые делают обнаружение, управление и отладку ваших активов данных простыми и приятными.
Компоненты службы Datahub
Архитектура DataHub:

Datahub можно посчитать за 5 сервисов:
- Пользовательский интерфейс Datahub — приложение React.js
- Интерфейс Datahub — Java-приложение с Play Framework
- Datahub GMS — бэкэнд-приложение на Java
- Потребительское приложение Datahub Metadata Change Event (MCE) — потребительское приложение Kafka
- Потребительское приложение Datahub Metadata Audit Event (MAE) — потребительское приложение Kafka
Metadata Ingestion — Вставка метаданных в DataHub с помощью Python
Способы вставки данных в DataHub
DataHub поддерживает интеграцию метаданных как на основе push, так и на основе pull.
Интеграция на основе push позволяет вам выдавать метаданные непосредственно из ваших систем данных при изменении метаданных, в то время как интеграции на основе pull позволяют вам «сканировать» или «принимать» метаданные из систем данных, подключаясь к ним и извлекая метаданные в пакетном или инкрементальном виде.
Поддержка обоих механизмов означает, что вы можете максимально гибко интегрироваться со всеми своими системами.
Примеры push-интеграций включают Airflow, Spark, Great Expectations и Protobuf Schemas. Это позволяет вам получить интеграцию метаданных с малой задержкой от «активных» агентов в вашей экосистеме данных.
Примеры pull-интеграций (на основе вытягивания метаданных) включают BigQuery, Snowflake, Looker, Tableau и многие другие.
Python Emitter
В некоторых случаях может потребоваться создать события метаданных напрямую и использовать программные способы отправки этих метаданных в DataHub. Сценарии использования, как правило, основаны на push-уведомлениях и включают отправку событий метаданных из конвейеров CI/CD, пользовательских оркестраторов и т.д.
Пакет acryl-datahub Python предлагает API-интерфейсы эмиттера REST и Kafka, которые можно легко импортировать и вызывать из собственного кода.
REST Emitter
Эмиттер REST представляет собой тонкую оболочку поверх requests модуля и предлагает блокирующий интерфейс для отправки событий метаданных по HTTP. Используйте его, когда простота и подтверждение сохранения метаданных в хранилище метаданных DataHub важнее, чем пропускная способность передачи метаданных. Также используйте REST Emitter, когда существуют сценарии чтения после записи, например, при записи метаданных и последующем их немедленном считывании.
Установить можно с помощью команды:
|
1 |
pip install -U `acryl-datahub[datahub-rest]` |
Пример REST Emitter
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
import datahub.emitter.mce_builder as builder from datahub.emitter.mcp import MetadataChangeProposalWrapper from datahub.metadata.schema_classes import ChangeTypeClass, DatasetPropertiesClass from datahub.emitter.rest_emitter import DatahubRestEmitter # Create an emitter to DataHub over REST emitter = DatahubRestEmitter(gms_server="http://localhost:8080", extra_headers={}) # Test the connection emitter.test_connection() # Construct a dataset properties object dataset_properties = DatasetPropertiesClass(description="This table stored the canonical User profile", customProperties={ "governance": "ENABLED" }) # Construct a MetadataChangeProposalWrapper object. metadata_event = MetadataChangeProposalWrapper( entityType="dataset", changeType=ChangeTypeClass.UPSERT, entityUrn=builder.make_dataset_urn("bigquery", "my-project.my-dataset.user-table"), aspectName="datasetProperties", aspect=dataset_properties, ) # Emit metadata! This is a blocking call emitter.emit(metadata_event) |
Kafka Emitter
Kafka Emitter представляет собой тонкую оболочку над классом SerializingProducer confluent-kafka и предлагает неблокирующий интерфейс для отправки событий метаданных в DataHub. Используйте его, если хотите отделить производителя метаданных по времени для безотказной работы вашего сервера метаданных концентратора данных, используя Kafka в качестве высокодоступной шины сообщений.
Например, если ваша служба метаданных DataHub не работает из-за плановых или незапланированных простоев, вы все равно можете продолжать собирать метаданные из критически важных систем, отправляя их в Kafka. Также используйте этот эмиттер, когда пропускная способность передачи метаданных важнее, чем подтверждение сохранения метаданных в серверном хранилище DataHub.
Примечание. Эмиттер Kafka использует Avro для сериализации событий метаданных в Kafka. Изменение сериализатора приведет к необрабатываемым событиям, поскольку DataHub в настоящее время ожидает, что события метаданных через Kafka будут сериализованы в Avro.
Установка производится с помощью команды:
|
1 |
pip install -U `acryl-datahub[datahub-kafka]` |
Пример использования Kafka Emitter
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
import datahub.emitter.mce_builder as builder from datahub.emitter.mcp import MetadataChangeProposalWrapper from datahub.metadata.schema_classes import ChangeTypeClass, DatasetPropertiesClass from datahub.emitter.kafka_emitter import DatahubKafkaEmitter, KafkaEmitterConfig # Create an emitter to Kafka kafka_config = { "connection": { "bootstrap": "localhost:9092", "schema_registry_url": "http://localhost:8081", "schema_registry_config": {}, # schema_registry configs passed to underlying schema registry client "producer_config": {}, # extra producer configs passed to underlying kafka producer } } emitter = DatahubKafkaEmitter( KafkaEmitterConfig.parse_obj(kafka_config) ) # Construct a dataset properties object dataset_properties = DatasetPropertiesClass(description="This table stored the canonical User profile", customProperties={ "governance": "ENABLED" }) # Construct a MetadataChangeProposalWrapper object. metadata_event = MetadataChangeProposalWrapper( entityType="dataset", changeType=ChangeTypeClass.UPSERT, entityUrn=builder.make_dataset_urn("bigquery", "my-project.my-dataset.user-table"), aspectName="datasetProperties", aspect=dataset_properties, ) # Emit metadata! This is a non-blocking call emitter.emit( metadata_event, callback=lambda exc, message: print(f"Message sent to topic:{message.topic()}, partition:{message.partition()}, offset:{message.offset()}") if message else print(f"Failed to send with: {exc}") ) #Send all pending events emitter.flush() |
Пример вставки тестовых данных на Python
todo…
Канал в телеграме: DataHub Project
Полезные статьи и источники, использованные для написания этой статьи
- Детальное описание компонентов архитектуры DataHub Deploy Open Source Datahub
- Deploy Open Source Datahub — Part II

