Contents
- 1 Что такое data engineering?
- 2 Кто такой инженер данных (data engineer)?
- 3 Основная терминология Data Engineering
- 4 Обзор архитектур данных
- 5 Обзор методологий, принципов и концепций разных типов хранилищ данных
- 5.1 Data Warehouse Design
- 5.1.1 Подход Kimball
- 5.1.2 Подход Inmon
- 5.1.3 Kimball vs Inmod Data Warehouse Architectures
- 5.1.4 Подход DW 2.0 — Bill Inmon
- 5.1.5 Подход Data Vault v2.0
- 5.1.5.1 Hub (Хаб)
- 5.1.5.2 Link (Ссылка)
- 5.1.5.3 Satellite (Сателлит или Спутник)
- 5.1.5.4 Как выглядит хранилище данных Data Vault?
- 5.1.5.5 Архитектура Data Vault
- 5.1.5.6 Staging
- 5.1.5.7 Enterprise Data Warehouse
- 5.1.5.8 Information Delivery
- 5.1.5.9 Data Vault Rules v1.0.8 Cheat Sheet
- 5.1.5.10 Базовые правила построения модели Data Vault
- 5.1.6 Подход Anchor
- 5.1.7 Подборки видео
- 5.2 Принципы построения архитектуры платформы данных
- 5.1 Data Warehouse Design
- 6 Data Warehouse — Корпоративное хранилище данных
- 7 Data Lakes
- 7.1 Введение в Озера данных
- 7.2 Схема при записи (Schema Read) и Схема при чтении (Schema Write)
- 7.3 Жизненный цикл Data Lake
- 7.4 Уровни архитектуры озера данных
- 7.5 Hybrid Data Lake
- 7.6 Data Lakehouse
- 7.7 Плюсы Data Lake
- 7.8 Минусы озера данных
- 7.9 Подборки видео по теме Data Lake & Data Lakehouse
- 7.10 Программные стеки, используемые в озерах данных
- 8 Ключевые отличия DWH и Data Lakes
- 9 ETL, ELT, Data Pipelines, Оркестрация
- 10 Modern Data Stack
- 11 Roadmap to becoming a data engineer in 2021
- 12 Используемые материалы в статье
Что такое data engineering?
Data Engineering (Инженерия данных/Инжиниринг данных/Дата инжиниринг) — это практика проектирования и создания систем, которые собирают, управляют, преобразуют и сохраняют данные в пригодном для использования состоянии, а также предоставляют доступ к данным для различных специалистов по данным (data scientists, business analysts, etc.). Специалисты по работе с данными смогут использовать их в своей работе. Т.е. другими словами Data Engineering помогает сделать данные более полезными и доступными для потребителей данных.
Ресурсы-подборки «Awesome Data Engineering»
- Awesome Data Engineering — A curated list of data engineering tools for software developers
- The Data Engineering Cookbook
- Data Learn: Data Engineering
- The DataOps Vendor Landscape, 2021
- Awesome Data Engineering (books, free resources, courses)
- Data Engineering Book — Oleg Agapov
- Data Engineering Technologies in 2021

Кто такой инженер данных (data engineer)?
Data Engineer (инженер данных) — это специалист, который занимается подготовкой данных для их дальнейшего анализа. Data Engineering также включает разработку платформ и архитектур для обработки данных.
Другими словами, инженер по данным разрабатывает основу для различных операций с данными. Инженер данных отвечает за разработку формата, в котором будут работать специалисты и аналитики данных.
Инженеры по обработке данных должны работать как со структурированными, так и с неструктурированными данными. Следовательно, им нужен опыт работы с базами данных SQL и NoSQL, а также с различными форматами данных и файлов (json, xml, csv и т.д.) и уметь работать с различными API. Data Engineers позволяют специалистам по обработке данных выполнять свои операции с данными.
Инженерам данных приходится иметь дело с большими данными, с которыми они производят многочисленные операции, такие как очистка данных, управление, преобразование, дедупликация данных и т.д.
Основные навыки Data Engineer
- Основы программной инженерии — Agile, DevOps, DataOps, архитектурное проектирование, сервис-ориентированная архитектура, Контейнеризация (Kubernetes, Docker).
- Распределенные системы — сюда входят навыки инженера-программиста и навыки архитектора программного обеспечения.
- Открытые платформы — Apache Spark, Hadoop, возможно, Hive, MapReduce, Kafka и другие.
- SQL — это основной продукт базы данных.
- Программирование — Python стал излюбленным языком для работы с данными. С другой стороны, Java, по-прежнему широко востребованная, потеряла популярность у большинства специалистов по обработке данных и инженеров. Scala — это еще один язык, на котором основаны Apache Spark и Kafka.
- Pandas — библиотека Python для очистки и управления данными.
- Визуализация / информационные панели
- Облачные платформы — AWS, вероятно, является наиболее распространенным набором облачных навыков для инженеров по обработке данных. Сразу за ними следуют Google Cloud Data Engineering и Microsoft Azure.
- Аналитика. Хотя в основном это сфера специалистов по обработке данных, навыки статистического анализа или понимание некоторых различных математических принципов или вероятностных принципов необходимы для того, чтобы иметь возможность правильно манипулировать данными, чтобы они имели форму, доступную для людей, которые выполняют окончательный анализ на этих данных.
- Моделирование данных — знания о моделировании данных сейчас очень важны в том смысле, что инженеру по данным необходимо знать, как они собираются структурировать таблицы, создание партиций данных, где нормализовать и денормализовать данные в хранилище и т.д. И также думать о получении определенных атрибутов.
- Знание решений для баз данных (SQL и NoSQL), инструментов ETL/ELT и различных операционных систем (Linux, Ubuntu), колоночные базы данных.
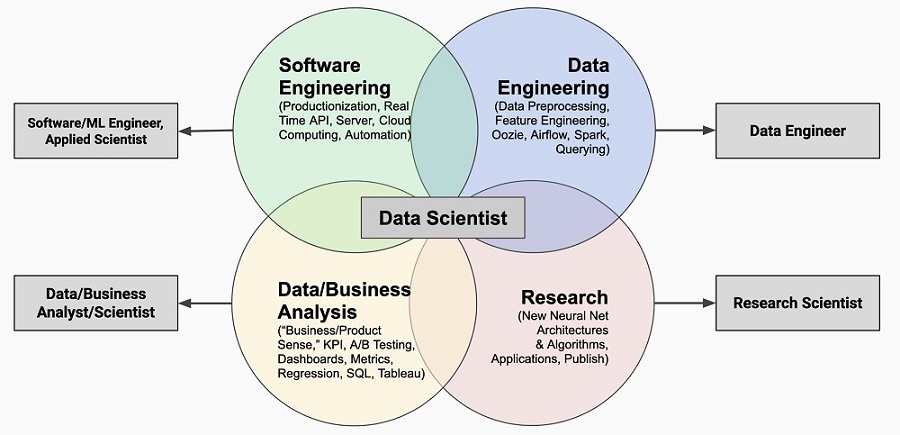
Сравнение трех ролей по работе с данными: Data Scientist vs Data Engineer vs Data Analyst
Data Analyst: человек, который специализируется на осмыслении прошлых и текущих числовых данных, чтобы находить ответы на вопросы бизнеса и помогать руководителям предприятий принимать более обоснованные решения.
Инструментарий: Business Intelligence, Data Storytelling, Анализ тенденций, What-If Analysis, создание визуализаций/отчетности/дашбордов, SQL/ database knowledge
Data Scientist: человек, который специализируется на построении аналитических и прогнозных моделей (на основе данных, полученных от инженеров данных) для интерпретации сложных данных.
Инструментарий: AI/ML, Применение инструментов статистического / машинного обучения для классификации шаблонов, определения силы шаблонов и взаимосвязей, количественная оценка причинно-следственных связей, обучение и оптимизация моделей машинного обучения.
Data Engineer: человек, который специализируется на создании, тестировании, оптимизации и обслуживании экосистем данных, которые позволяют ученым и аналитикам данных выполнять свою работу.
Инструментарий: проектирование инфраструктуры больших данных и подготовка ее к анализу, построение сложных запросов для создания «конвейеров данных (data pipelines)», очистка наборов данных, трансформация данных, оптимизация производительности, Data architecture, Data Warehousing & ETL, Hadoop-based Analytics
Чем занимаются инженеры по данным? В первую очередь они сосредоточены на:
- Создание, тестирование и поддержка конвейеров данных и архитектур организации (хранилища данных ,базы данных)
- Управление безопасностью данных, резервное копирование и восстановление, доступ и целостность данных
- Очистка и преобразование данных из различных источников и форматов в пригодное для дальнейшего анализа и использования состояние

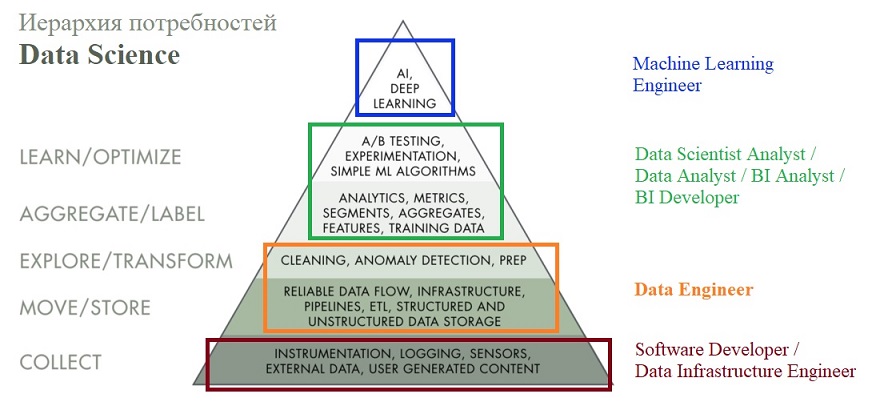
Иерархия потребностей Data Science (Автор Моника Рогати)
Пирамида «Иерархия потребностей науки о данных» прекрасно отражает сложный процесс обработки данных.
Основная терминология Data Engineering
- Data Warehouse (Хранилище данных) — это база данных, оптимизированная для анализа реляционных данных, поступающих из транзакционных систем и бизнес-приложений. Структура данных и схема определены заранее для оптимизации для быстрых запросов SQL, результаты которых обычно используются для оперативной отчетности и анализа. Данные очищаются, обогащаются и трансформируются, чтобы они могли выступать в качестве «единого источника истины», которому пользователи могут доверять.
- Data Mart (Витрина данных) — подмножество хранилища данных, обычно для определенной бизнес-функции (маркетинг, продажи, складские запасы, финансы и т.п.).
- Data Lake (Озеро данных) — это хранилище, в котором хранится огромное количество необработанных данных в собственном формате, включая структурированные, полуструктурированные и неструктурированные данные. Структура данных и требования не определены, пока данные не потребуются. Озера данных обеспечивают большую гибкость, чем более жесткое хранилище данных.
- ETL (extract, transform, load) — три функции базы данных (извлечение, преобразование, загрузка), которые объединены в один инструмент для извлечения данных из одной базы данных и помещения их в другую базу данных.
- ELT (извлечение, загрузка, преобразование) — Вместо преобразования данных перед записью ELT использует целевую систему для выполнения преобразования. Одним из главных достоинств ELT является сокращение времени загрузки по сравнению с моделью ETL. Использование возможностей обработки, встроенных в инфраструктуру хранилищ данных, сокращает время, затрачиваемое данными на передачу, и становится более рентабельным.
- Batch ETL — Пакетная обработка ETL в основном означает, что пользователи собирают и хранят данные в пакетном режиме во время пакетного окна. Это может сэкономить время и повысить эффективность обработки данных, а также помогает организациям и компаниям управлять большими объемами данных и быстро их обрабатывать. В традиционных системах данных программа ETL извлекала пакеты данных из исходной системы, обычно по расписанию, преобразовывала эти данные, а затем загружала их в репозиторий, например, в хранилище данных или базу данных. Это модель «пакетного ETL».
- Streaming ETL — это обработка и перемещение данных в реальном времени из одного места в другое. Современная обработка данных перешла от устаревшей пакетной обработки данных к работе с потоками данных в реальном времени. Потоковый ETL использует платформу потоковой обработки, которая действует как посредник между источниками данных и их конечным местом назначения в базе данных. Обнаружение мошенничества — один из примеров, когда потоковая передача ETL является гораздо более разумным выбором, чем пакетная обработка.
- Data Pipeline (Конвейер данных) — набор элементов обработки данных, соединенных последовательно, где выход одного элемента является входом следующего. Элементы конвейера часто выполняются параллельно или с временным интервалом. Конвейер может быть пакетным (историческим) или потоковым (в реальном времени).
Цикл: прием данных — обработка данных — хранение данных — анализ данных. - Data enrichment (Обогащение данных) — общий термин, который относится к процессам, используемым для улучшения, уточнения или иного улучшения необработанных данных. Цель обогащения данных — сделать их более ценным активом — получить от них больше ценности, упростить доступ к ним и увеличить их использование — и все это без заметного увеличения затрат или рисков.
- Data Engineering – программирование сбора, хранения, обработки, поиска и визуализации данных. Data Engineering помогает построить стабильные процессы ETL и ELT добычи и подготовки данных для систем аналитики, алгоритмов машинного обучения, Data Science.
- Advanced Analytics (Расширенная аналитика) — Процесс получения более глубокого понимания данных, чем обычно обеспечивается большинством инструментов бизнес-аналитики (BI). Расширенная аналитика может выполняться с использованием сложных инструментов и методов, включая машинное обучение (ML) и искусственный интеллект (AI), интеллектуальный анализ данных / текста, семантический анализ, анализ тональности, сетевой и кластерный анализ, многомерную статистику и многое другое.
- Artificial Intelligence (AI / Искусственный интеллект / ИИ) — это широкий термин, используемый для описания спроектированных систем, которые были обучены выполнять задачу, которая обычно требует человеческого интеллекта.
- Data Mining (Сбор данных) — Процесс поиска закономерностей, корреляций или аномалий в наборах данных для прогнозирования результатов.
- Data Science (Наука о данных / Исследование данных) — это практика, в которой используются научные методы, алгоритмы и системы для анализа структурированных и неструктурированных данных.
- Machine learning (ML) — обычно относится к алгоритмам, созданным для выявления закономерностей в больших данных.
- DataOps — способ управлять все более огромными и сложными данными. Когда у вас есть больше данных, скажем, сотни конвейеров, созданных из сотен различных источников, управлять ими будет намного сложнее. Если вы хотите быстро и эффективно масштабироваться, у вас должен быть согласованный способ сбора, передачи и понимания данных. Вам нужна какая-то структура, и это DataOps.
- Data Catalog (Каталог данных) — Организованная инвентаризация активов данных, основанная на метаданных для помощи в управлении данными.
- Data Lineage (Происхождение данных) — описывает происхождение и изменения данных с течением времени (как данные были преобразованы, что изменилось и почему). Data Lineage помогает пользователям убедиться, что их данные поступают из надежного источника, были правильно преобразованы и загружены в указанное место.
- Data Management (Управление данными) — это практика безопасного и эффективного сбора, хранения и использования данных.
- Data governance (Управление данными) — это общее управление доступностью, актуальностью, удобством использования, целостностью и безопасностью данных на предприятии. Практики управления данными обеспечивают целостный подход к управлению, совершенствованию и использованию информации для повышения общей эффективности управления данными на предприятии. Data Governance — отвечает за проектирование управления данными, при котором происходит консолидация всей документации, всех правил и политик, которые касаются управления данных. Data management — отвечает за исполнительную часть в управлении данных, т.е. претворение в жизнь всего задуманного.
- Data Steward (Управляющий данными) — это роль в организации, которая отвечает за эффективность процессов управления данными для обеспечения соответствия элементов данных — как содержимого, так и метаданных. Обеспечивает эффективный контроль и использование информационных активов в компании. Конечная цель data stewardship процессов — предоставление пользователям надежных данных.
- Column Oriented Database — хранилище данных, в котором значения столбцов таблицы непрерывно хранятся на диске.
- Hadoop / HDFS — Программный фреймворк Apache с открытым исходным кодом для обработки больших данных. HDFS означает распределенную файловую систему Hadoop.
- MapReduce — это компонент фреймворка Hadoop, который используется для доступа к большим данным, хранящимся в файловой системе Hadoop. Метод обработки и программная модель для распределенных вычислений на основе java. Алгоритм MapReduce содержит две важные задачи, а именно Map и Reduce. Карта принимает набор данных и преобразует его в другой набор данных, где отдельные элементы разбиваются на кортежи (пары ключ / значение).
- Data Architecture (Архитектура данных) — это совокупность моделей, правил и стандартов для всех систем данных и взаимодействия между ними. Способ обработки и хранения данных; как данные передаются и используются проектными группами, включая модели данных (концептуальные, логические, физические и размерные). Архитектура данных определяет данные вместе со схемами, интеграцией, преобразованиями, хранением и рабочим процессом, необходимыми для выполнения аналитических требований информационной архитектуры. Надежная архитектура данных — это план, который помогает согласовать данные вашей компании с ее бизнес-стратегиями. Архитектура данных определяет, как данные собираются, интегрируются, улучшаются, хранятся и доставляются деловым людям, которые используют их для своей работы. Он помогает сделать данные доступными, точными и полными, чтобы их можно было использовать для принятия бизнес-решений.
- Master data (Основные данные) — это важные данные/важная информация, которую необходимо поддерживать и совместно использовать согласованным и управляемым образом. Управление мастер-данными — это процесс выявления, сбора, интеграции и обмена мастер-данными. По сути это проверенные, утвержденные и поддерживаемые в надлежащем качестве справочники об объектах бизнеса, которые в последствии используются для построения аналитического ландшафта.
Обзор архитектур данных
Получение ценности из данных включает в себя построение унифицированной архитектуры данных, которая строится совместными усилиями групп инженеров и специалистов по обработке данных. Инжиниринг данных включает в себя создание и обслуживание инфраструктуры данных, ETL/ELT, конвейеров данных, а наука о данных включает преобразование сырых данных во что-то полезное (insights, знания из данных и т.д.).
Разберем несколько примеров схем архитектур данных. Первый пример взят из статьи Modern Unified Data Architecture:

- Variety (Разнообразие): данные поступают в различных форматах, структурах, протоколах и размерах из разрозненных источников данных. Архитектура должна управлять диверсификацией данных, обеспечивая при этом согласованный доступ к данным. Он должен обеспечивать гибкость, а также обеспечивать разумные ограничения для вариантов схемы.
- Velocity (Скорость): архитектура должна управлять быстро меняющимися данными, чтобы генерировать результаты в более короткие сроки, а также медленно меняющимися данными, чтобы генерировать результаты на периодической основе или по требованию. Решение должно эффективно масштабироваться в соответствии со скоростью поступления данных.
- Volume (Объем): архитектура должна обрабатывать объем поступающих данных — малых, больших или пакетных. Он должен эффективно управлять входящими данными, а также историческими данными и предлагать правильные варианты для разных сценариев анализа.
- Visibility (Видимость): Архитектура должна управлять видимостью и доступностью данных, а также деталями их взаимоотношений и происхождения.
- Veracity (Достоверность): это степень точности, полноты и достоверности данных. Данные должны очищаться, дедуплицироваться, обогащаться и проверяться для обеспечения целостности данных, чтобы компании могли доверять данным и проводить анализ на надежных данных.
- Vulnerability (Уязвимость): данные должны быть защищены от несанкционированного доступа, где бы они ни находились. Должно быть известно кем и как используются данные на протяжении всего жизненного цикла данных и во всем потоке данных (data flow).
- Value (Ценность): Конечным результатом архитектуры данных является обеспечение анализа на основе данных для принятия бизнес-решений или создание продуктов на основе данных для роста выручки, повышения качества или снижения расходов и т.п. цели.
Мультимодальная архитектура данных
Эталонная схема архитектуры данных, которую сформировали на основе обсуждения с ведущими практиками по работе с данными (с опорой на используемые в разных компаниях технологические стеки инфраструктуры данных и инструментов по работе с данными).
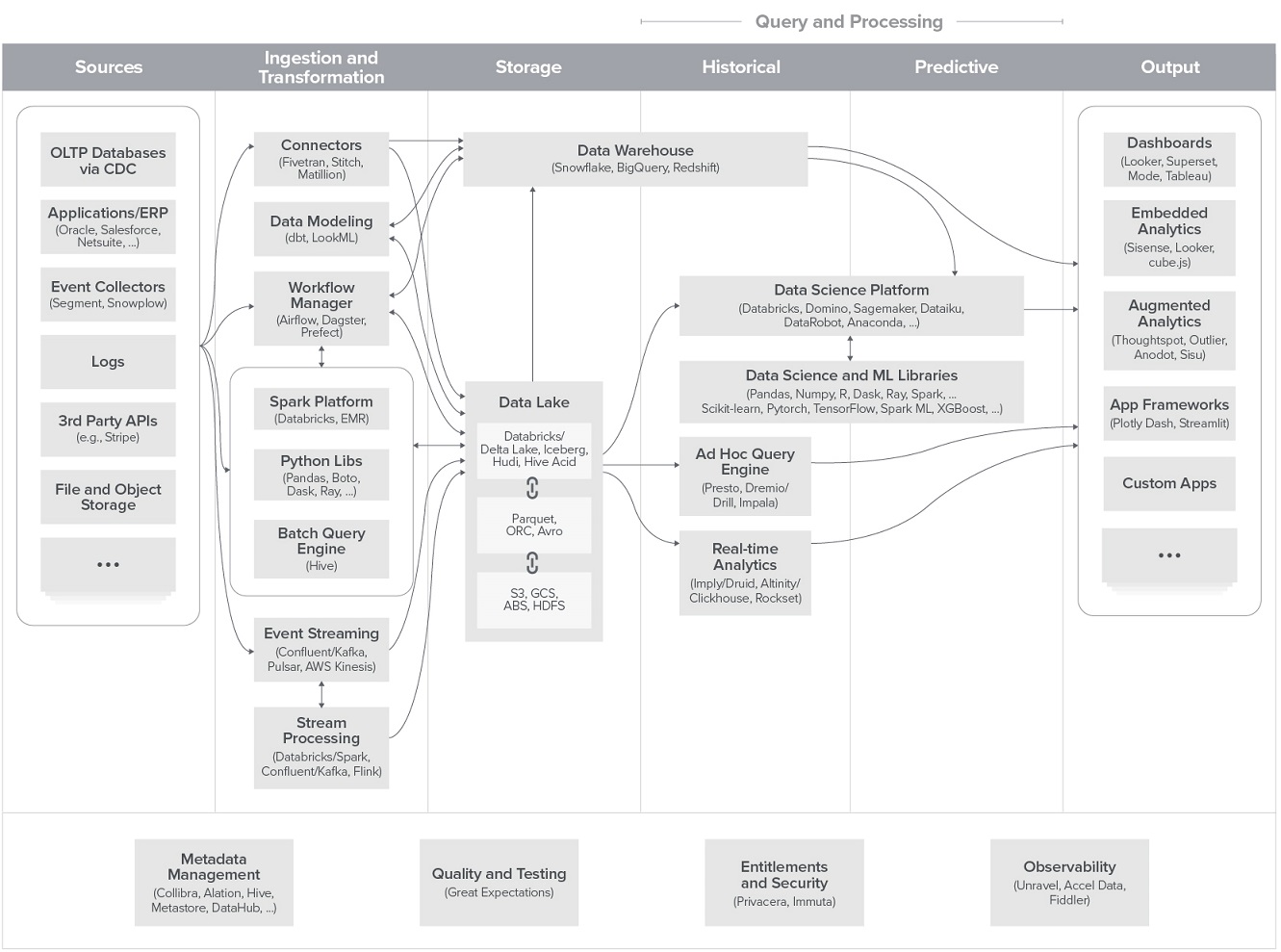
Data & AI Landscape 2020

Скачать документ в хорошем качестве -> 2020-Data-and-AI-Landscape-Matt-Turck-at-FirstMark.pdf
Подпишитесь на Telegram канал Data Engineering: DevOps & DataOps based on Open-Source software, чтобы получать актуальную информацию в сфере Дата инжиниринга.
Обзор методологий, принципов и концепций разных типов хранилищ данных
Data Warehouse Design
Подход Kimball
Модель данных Kimball — это восходящий подход к проектированию архитектуры хранилища данных (DWH или DW), в котором витрины данных сначала формируются на основе бизнес-требований.
Данные из источников данных с помощью ETL извлекаются и загружаются в промежуточную область сервера реляционной базы данных.
После того, как данные загружены в промежуточную область хранилища данных, следующий этап включает загрузку данных в многомерную модель хранилища данных, денормализованную по своей природе (схема звезда).
Эта модель разделяется на таблицу фактов, которая представляет собой числовые данные транзакций, и таблицы измерений, которые являются справочной информацией, которая является контекстом для данных в таблице фактов.
Схема «звезда» — это фундаментальный элемент модели многомерного хранилища данных.
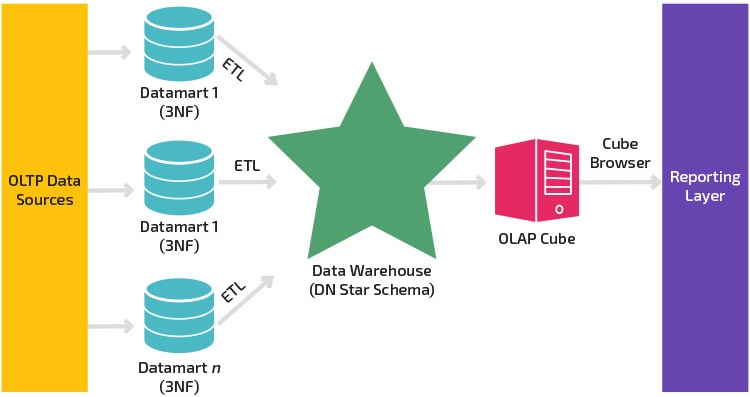
Dimensional Modeling Кимбалла позволяет пользователям создавать несколько звездообразных схем для удовлетворения различных требований к отчетности.
Преимущество звездообразной схемы заключается в том, что запросы к небольшим размерным таблицам выполняются мгновенно.
Для интеграции данных архитектура Kimball DWH предлагает идею согласованных измерений данных. Одни и те же Dimension таблицы могут совместно использоваться в разных таблицах фактов в хранилище данных, или одни и те же таблицы измерений могут использоваться в различных витринах данных Kimball. Это гарантирует, что один элемент данных используется одинаковым образом во всех отчетных формах.
Важным инструментом проектирования хранилища данных в методологии Ральфа Кимбалла является матрица шины предприятия или архитектура шины Кимбалла, которая записывает факты по вертикали и записывает согласованные измерения по горизонтали.
Преимущества подхода Кимбалла
- Kimball dimensional modeling позволяет быстро реализовывать хранилища данных поскольку не требуется нормализация данных, что позволяет быстро выполнять начальные фазы процесса проектирования хранилища данных.
- Преимущество звездообразной схемы состоит в том, что большинство операторов данных могут легко понять ее из-за ее денормализованной структуры, которая упрощает запросы и анализ.
- Площадь системы хранилища данных тривиальна, поскольку она ориентирована на отдельные области бизнеса и процессы, а не на все предприятие. Таким образом, хранилище занимает меньше места в базе данных, что упрощает управление системой.
- Это позволяет быстро извлекать данные из хранилища данных, поскольку данные разделяются на таблицы фактов и измерения. Например, таблица фактов и измерений для страховой отрасли будет включать транзакции по полисам и транзакции по претензиям.
- Для управления хранилищем данных достаточно небольшой группы проектировщиков и разработчиков, поскольку системы источников данных стабильны, а хранилище данных ориентировано на процессы. Кроме того, оптимизация запросов проста, предсказуема и управляема.
- Согласованная структура измерений для data quality framework. Подход Кимбалла также называют подходом к образу жизни, измеряющим бизнес, потому что он позволяет инструментам business intelligence глубже проникать в несколько звездообразных схем и дает надежную информацию.
Kimball Approach to Data Warehouse Lifecycle:
Недостатки подхода Кимбалла
- Данные не полностью интегрированы до создания отчетности, идея «единого источника правды» потеряна.
- При обновлении данных в архитектуре Kimball DWH могут возникать не точные данные. Это связано с тем, что при использовании техник денормализации хранилища данных избыточные данные добавляются в таблицы базы данных.
- В архитектуре Kimball DWH проблемы с производительностью могут возникать из-за добавления столбцов в таблицу фактов, поскольку эти таблицы содержат довольно подробные сведения. Добавление новых столбцов может расширить размерность таблицы фактов, что повлияет на ее производительность (т.е. увеличится детализация хранилища данных). Кроме того, модель многомерного хранилища данных становится трудно изменить при любых изменениях потребностей бизнеса.
- Поскольку модель Кимбалла ориентирована на бизнес-процессы, вместо того, чтобы сосредоточиться на предприятии в целом, она не может удовлетворить все требования к отчетности бизнес-аналитики.
- Процесс включения больших объемов устаревших данных в хранилище данных сложен.
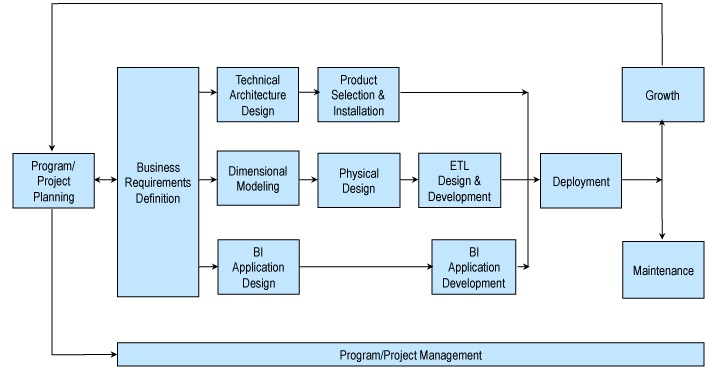
Подход Inmon
Подход Bill Inmon основывается на том, что Data Warehouse является централизованным хранилищем всех корпоративных данных. При использовании этого подхода организация сначала создает нормализованную модель хранилища данных. Затем на основе единого хранилища данных создаются витрины размерных данных. Это известно как нисходящий подход к хранилищу данных.
Детальная последовательность работ:
Этот метод начинается с моделирования корпоративных данных. Сначала определяются основные предметные области и сущности (клиенты, продукт/услуга, поставщики и т.д.). Затем на основе этого создается подробная логическая модель для каждой сущности. Структура сущности имеет нормализованный вид, по возможности избегается избыточность данных. Это ключевая характеристика этого метода, позволяющая определить бизнес-концепцию и избежать аномалий обновления данных.
Такая структура упрощает загрузку данных. Но использовать структуру для запросов сложно из-за большого количества таблиц и объединений.
Bill Inmon предлагает строить витрины данных для каждого конкретного отдела (финансов, продаж, развития бизнеса, маркетинга и т.д.). Все данные интегрированы, а хранилище данных — это единый источник данных из разных витрин. Такая концепция гарантирует полноту и согласованность данных во всей организации.
Преимущества подхода Инмона
- Хранилище данных действует как единый источник истины для всего бизнеса, где все данные интегрированы.
- Этот подход имеет очень низкую избыточность данных. Таким образом, уменьшается вероятность сбоев в обновлении данных, что делает процесс хранилища данных ETL более простым и менее подверженным сбоям.
- Это упрощает бизнес-процессы, поскольку логическая модель представляет подробные бизнес-объекты.
- Этот подход обеспечивает большую гибкость, поскольку проще обновлять хранилище данных в случае каких-либо изменений в бизнес-требованиях или исходных данных.
- Он может обрабатывать разнообразные требования к отчетности в масштабе всего предприятия.
Недостатки подхода Инмона
- Сложность увеличивается со временем по мере добавления нескольких таблиц в модель данных.
- Требуются разработчики, обладающие навыками моделирования и проектирования хранилищ данных, которые могут быть дорогими и недоступными на рынке труда.
- Первичная разработка и ввод в эксплуатацию занимают много времени.
- Требуется дополнительная операция ETL, поскольку витрины данных создаются после создания хранилища данных.
- Этот подход требует от экспертов эффективного управления хранилищем данных.
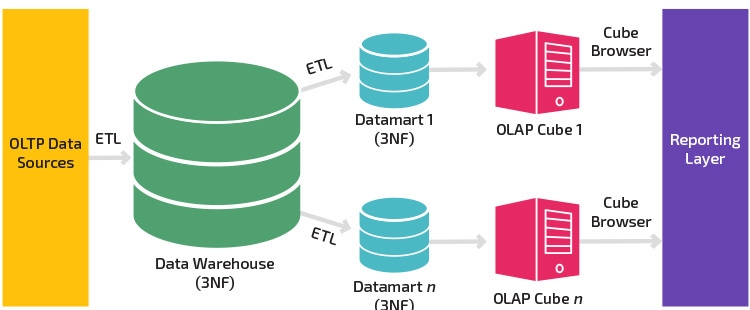
Kimball vs Inmod Data Warehouse Architectures
Архитектуры Кимбалла и Инмон имеют одну и ту же общую черту: каждая имеет единый интегрированный репозиторий атомарных данных. В архитектуре Inmon это называется корпоративным хранилищем данных. А в архитектуре Кимбалла это известно как пространственное хранилище данных. Обе архитектуры ориентированы на предприятие, которое поддерживает анализ информации в масштабах всей организации. Такой подход позволяет реализовывать бизнес-требования не только в рамках предметной области, но и между предметными областями.
Однако есть некоторые различия в этих подходах:
- Kimball использует размерную модель, такую как схема «Звездочка» или «Снежинка», для организации данных в пространственном хранилище данных, в то время как Inmon использует ER-модель в корпоративном хранилище данных. Inmon использует размерную модель только для витрин данных, в то время как Kimball использует ее для всех данных.
- Inmon использует витрины данных как физическое отделение от корпоративного хранилища данных, и они предназначены для использования в отделах. В архитектуре Кимбалла нет необходимости отделять витрины данных от пространственного хранилища данных.
- В многомерном хранилище данных Кимбалла аналитические системы могут получать доступ к данным напрямую. В архитектуре Inmon аналитические системы могут получать доступ к данным в корпоративном хранилище данных только через витрины данных.
Согласно философии Кимбалла, сначала все начинается с критически важных витрин данных, которые обслуживают аналитические потребности отделов. Затем он интегрирует эти витрины данных для обеспечения согласованности данных через так называемую информационную шину. Kimball использует размерную модель для удовлетворения потребностей отделов в различных областях внутри предприятия.
Билл Инмон рекомендует строить хранилище данных по принципу «сверху вниз». Согласно философии Inmon, это начинается с создания большого централизованного корпоративного хранилища данных, в котором все доступные данные из систем транзакций консолидируются в предметно-ориентированный, интегрированный, изменчивый по времени и энергонезависимый набор данных, который поддерживает принятие решений, а затем строятся витрины данных для аналитических нужд отделов.
Let’s Compare the Kimball and Inmon Data Warehouse Architectures
Подход DW 2.0 — Bill Inmon
В DW 2.0 было признано несколько важных аспектов среды хранилища данных.
Одним из них был жизненный цикл данных в среде хранилища данных. Со временем данные начали доживать свой собственный жизненный цикл после того, как были введены в хранилище данных.
Еще одним важным моментом DW 2.0 было то, что неструктурированные данные стали важным аспектом мира хранилищ данных.
До DW 2.0 единственными данными, которые можно было найти в хранилищах данных, была оперативная структурированная информация. Но с DW 2.0 было признано, что неструктурированные данные также могут загружаться в хранилище данных.
Еще одним открытием DW 2.0 стало признание того, что метаданные являются неотъемлемой частью инфраструктуры. DW 2.0 признал, что корпоративные метаданные так же важны, как и локальные. И, наконец, примерно в то время, когда обсуждался DW 2.0, было признано, что дизайн хранилищ данных был значительно улучшен за счет достижений Data Vault.
Но, пожалуй, самым большим достижением DW 2.0 стало осознание необходимости другой формы массового хранения. Фактически, оперативное хранилище было предшественником больших данных.
Эволюция информационной архитектуры
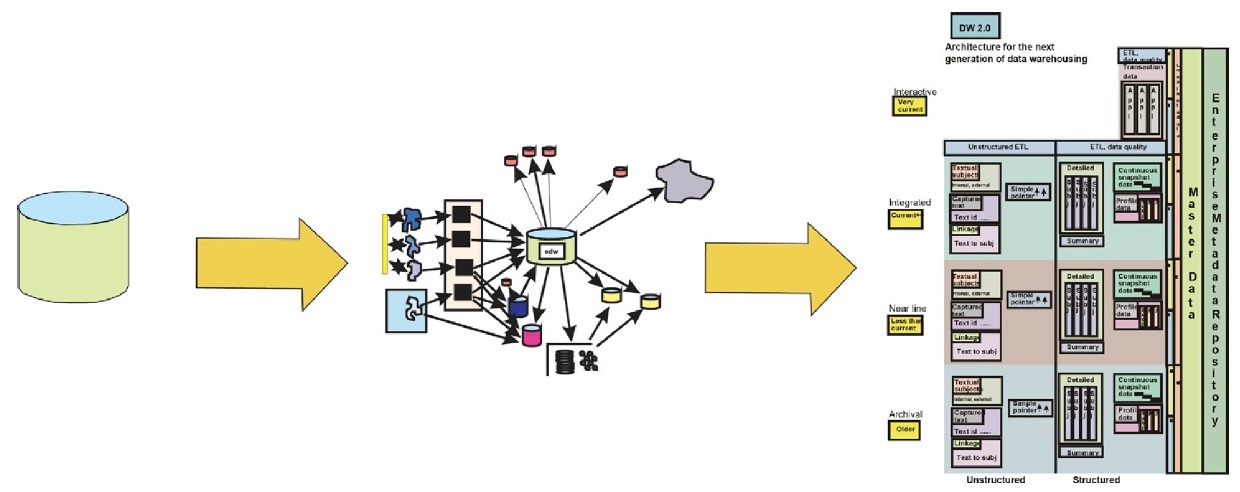
DW 2.0 — это определение архитектуры хранилища данных для следующего поколения хранилищ данных.
Чтобы понять, как появился DW 2.0, рассмотрим следующие факторы:
- В хранилищах данных первого поколения упор делался на создание хранилища данных и на adding business value. Во времена хранилищ данных первого поколения получение ценности означало получение преимущественно числовых транзакционных данных и их интеграцию. Сегодня получение максимальной выгоды от корпоративных данных означает использование ВСЕХ корпоративных данных и извлечение из них ценности. Это означает включение текстовых неструктурированных данных, а также числовых данных транзакций.
- В хранилищах данных первого поколения не уделялось особого внимания носителю, на котором хранятся данные, или их объему. Но время показало, что носитель, на котором хранятся данные, и их объем — действительно очень большие проблемы.
- В хранилищах данных первого поколения было признано, что интеграция данных является проблемой. В современном мире признано, что интеграция старых данных — еще более серьезная проблема, чем то, что когда-то считалось.
- В хранилищах данных первого поколения затраты практически не возникали. В современном мире стоимость хранилищ данных является главной проблемой.
- В хранилищах данных первого поколения метаданными не уделялось должного внимания. В сегодняшнем мире управление метаданными и основными данными является серьезной проблемой.
- На заре создания хранилищ данных первого поколения хранилища данных считались новинкой. В современном мире хранилища данных считаются фундаментом, на котором основано конкурентное использование информации. Хранилища данных стали незаменимыми.
- На заре создания хранилищ данных упор делался на простое создание хранилища данных. В современном мире признано, что хранилище данных должно быть гибким с течением времени, чтобы соответствовать меняющимся требованиям бизнеса.
- На заре создания хранилищ данных было признано, что хранилище данных может быть полезно для статистического анализа. Сегодня признано, что наиболее эффективное использование хранилища данных для статистического анализа — это связанная структура хранилища данных, называемая исследовательским хранилищем.
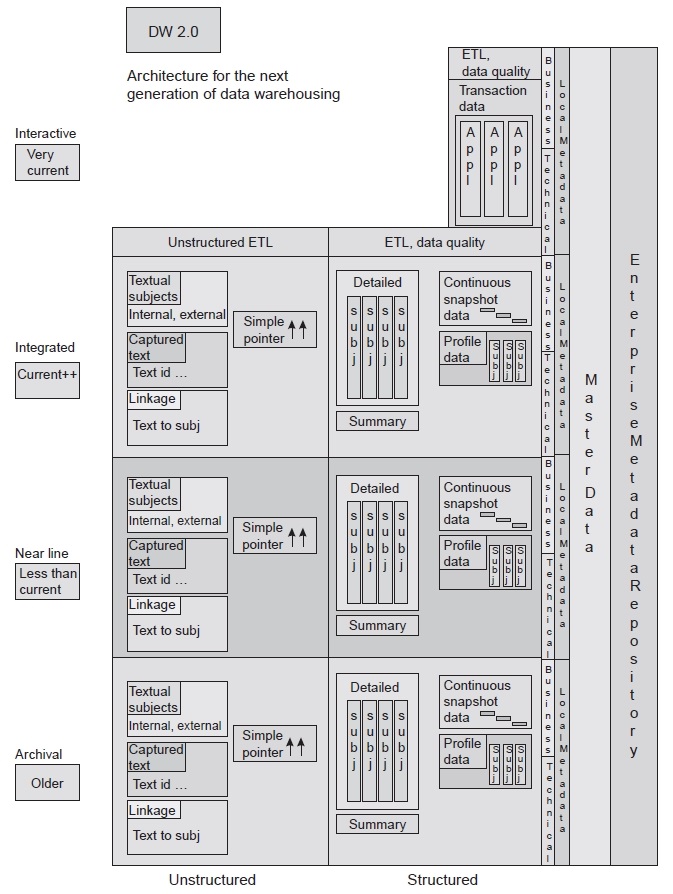
Структура данных в DW 2.0
DW 2.0 — это новая парадигма хранилищ данных. Это парадигма, которая фокусируется на основных типах данных, их структуре и том, как они связаны, чтобы сформировать мощное хранилище данных, которое удовлетворяет потребности корпорации в информации.
На рисунке изображена новая архитектура DW 2.0. Здесь показаны различные типы данных, их базовая структура и их взаимосвязь.
Подход Data Vault v2.0
Data Vault — это инновационная методология моделирования данных для крупномасштабных платформ хранилищ данных. Подход Data Vault, который был изобретен Дэном Линстедтом. В 2013 году Дэн Линстедт представил новую версию Data Vault 2.0.
Модель Data Vault — это детально ориентированный, исторически отслеживаемый и однозначно связанный набор нормализованных таблиц, которые поддерживают одну или несколько функциональных областей бизнеса. В Data Vault 2.0 сущности модели имеют hash-ключи, тогда как в Data Vault 1.0 сущности модели имеют ключи последовательностей.
Стиль моделирования представляет собой гибрид методов третьей нормальной формы и методов размерного моделирования, уникально объединенный для удовлетворения потребностей предприятия. Модель Data Vault также основана на шаблонах, обнаруженных в схемах типа «hub-and-spoke», также известных как «scale-free network».
Пример модели Data Vault
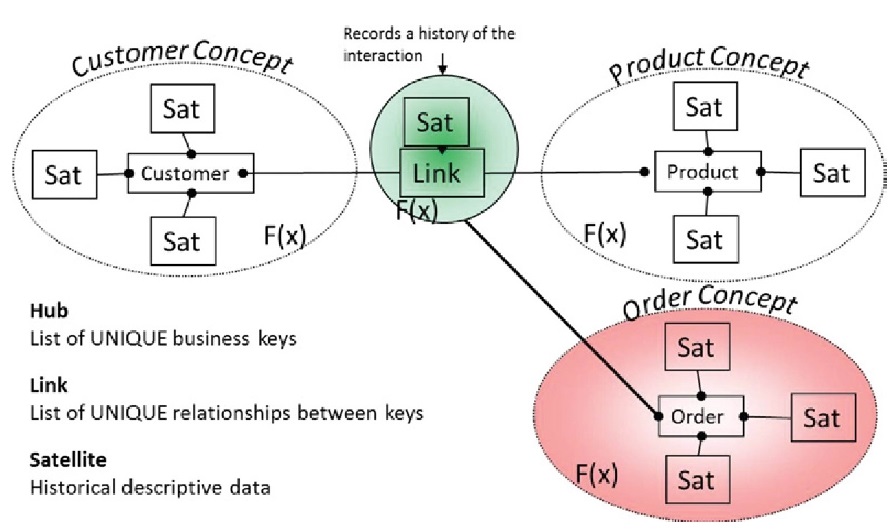
Эти шаблоны проектирования позволяют модели Data Vault наследовать немасштабируемые атрибуты, что означает, что нет никаких известных внутренних ограничений на размер модели или размер данных, которые модель может представлять, кроме ограничений, налагаемых инфраструктурой.
Архитектура Data Vault состоит из трех основных структур:
- Hub (Хаб) — естественный бизнес-ключ
- Link (Ссылка) — естественные деловые отношения
- Satellite (Сателлит или Спутник) — весь контекст, описательные данные и история

или

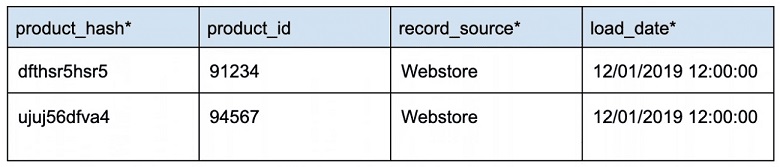
Hub (Хаб)
Хаб — основной бизнес-объект внутри компании (покупатель, товар, склад, магазин).
Hub не содержат никаких контекстных данных или сведений о сущности. Они содержат только определенный бизнес-ключ и несколько обязательных полей Data Vault. Важным атрибутом Hub является то, что они содержат только одну строку на ключ.
Пример Data Vault Hub:
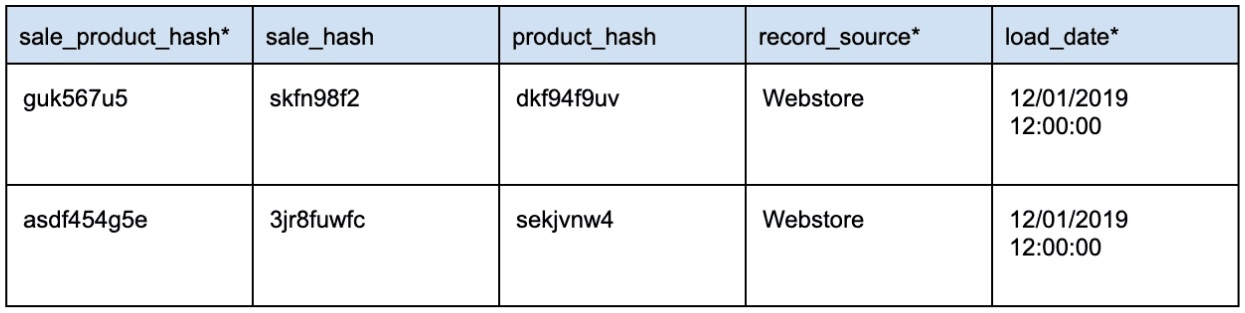
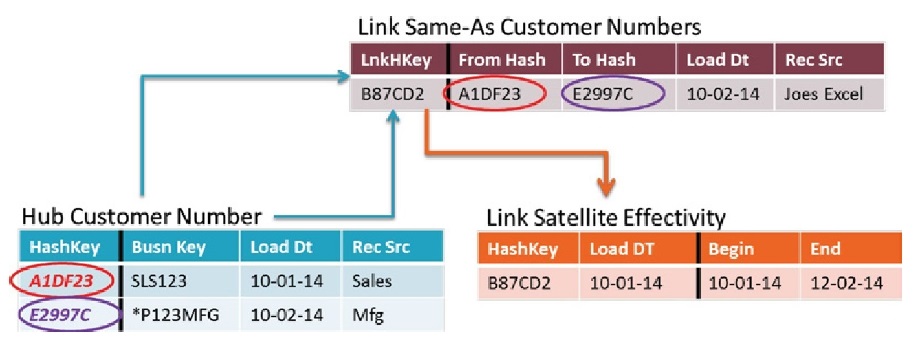
Link (Ссылка)
Link определяет отношения между бизнес-ключами от двух или более Hub. Link — это таблица, в которой хранятся пересечения бизнес-ключей нескольких HUB, эта таблица обеспечивает связь типа многие-ко-многим.

Пример таблицы Link:
Satellite (Сателлит или Спутник)
В архитектуре Data Vault сателлит (satellite) содержит все контекстные детали (все описательные атрибуты), относящиеся к сущности (hub).
Важной функцией Satellite является хранение истории изменения данных.
При изменении данных в системе-источнике необходимо вставить новую строку с измененными данными. Эти записи отличаются друг от друга с помощью хеш-ключа и одного из обязательных полей Data Vault: load_date. Для данной записи load_date позволяет нам определить, какая запись самая последняя.
Пример:
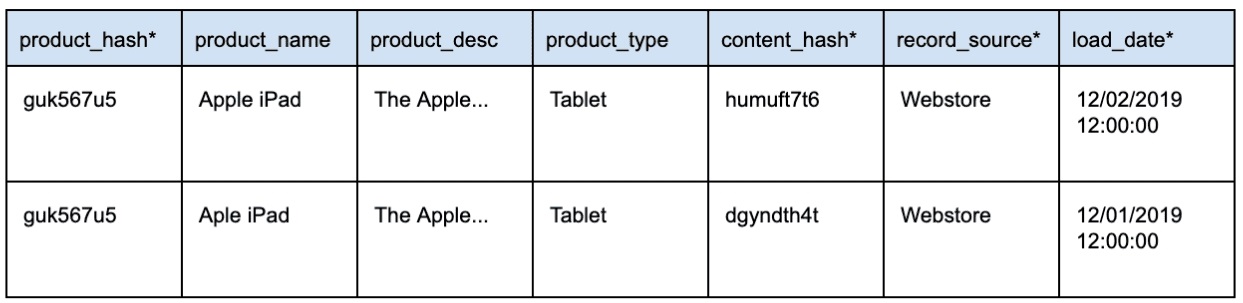
Возникает закономерный вопрос: «Но разве не потребуется вечность, чтобы определить, что изменилось между источником и хранилищем данных?»
Нет — это очень эффективно с использованием content_hash.
Content_hash вычисляется при заполнении промежуточной области Data Vault. Content_hash будет использовать все соответствующие контекстные поля данных. Когда любое из этих полей контекстных данных обновляется, будет вычисляться другой content_hash. Это позволяет очень быстро обнаруживать изменения.
Чтобы помочь с дифференциацией, спутники создаются на основе источника данных и скорости его изменения (точнее частоты изменения данных). Как правило, вы разрабатываете новую таблицу Satellite для каждого источника данных, а затем дополнительно отделяете данные из тех источников, которые могут изменяться с высокой частотой. Разделение высокочастотных и низкочастотных атрибутов данных может повысить пропускную способность приема и значительно сократить пространство, которое занимают исторические данные. Разделение атрибутов по частоте не является обязательным, но это может дать некоторые преимущества.
Как выглядит хранилище данных Data Vault?

Data Vault 2.0 Data model
Методология Data Vault позволяет командам очень быстро получать новые источники данных.
Данные из нового источника могут быть вставлены сразу в новую таблицу Satellite (без перепроектирования справочника, оценки изменений и т.д. как это требуется например в Kimball). Это позволяет инженерам по обработке данных быстро взаимодействовать с бизнес-пользователями при создании новых информационных витрин.
Вам нужно интегрировать в Data Vault совершенно новые бизнес-объекты? Вы можете добавить новые Hub в любое время, и вы можете определить новые отношения, создав новые таблицы link между hub. Этот процесс не оказывает никакого влияния на существующую модель.
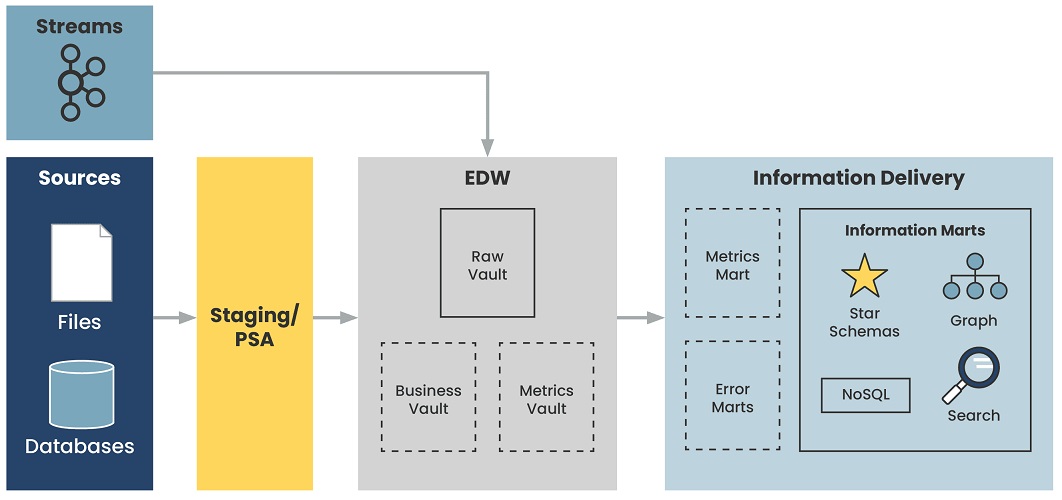
Архитектура Data Vault
Data Vault предоставляет многоуровневую архитектуру, которая является масштабируемой и гибкой.
Staging
Сначала данные из операционных систем поступают в Staging зону. Staging используется как промежуточное звено в процессе загрузки данных. Одна из основных функций этой промежуточной зоны — это снижение нагрузки на реляционные DB при выполнении запросов. Таблицы здесь полностью повторяют исходную структуру, при этом любые ограничения на вставку данных, например not null или проверки целостности внешних ключей, следует выключить, чтобы была возможность вставить даже поврежденные или неполные данные. Это очень актуально для excel-таблиц, Google Sheets, самописных решений без надлежащего контроля качества данных. Дополнительно в stage таблицах содержатся хеши бизнес-ключей и информация о времени загрузки и источнике данных.
Enterprise Data Warehouse
Raw
Raw — это то место, где живет наша основная модель Data Vault (hub, links, satellites). Данные загружаются в необработанный слой непосредственно из промежуточного уровня или, возможно, непосредственно в необработанный уровень при обработке источников данных в реальном времени. При загрузке на уровень Raw к данным также не должны применяться бизнес-правила.
Data Ingestion в Raw является важным шагом в архитектуре Data Vault и должно выполняться правильно для обеспечения согласованности.
Business Vault
Business Vault — это дополнительный уровень в Data Vault, где компания может определять общие бизнес-объекты, вычисления и логику. Это могут быть такие вещи, как Master Data или создание бизнес-логики, которая используется во всем бизнесе на различных Information Marts. Эти вещи не должны реализовываться в каждом information mart по-разному, это должно быть реализовано один раз в Business Vault и многократно использоваться через Information Marts.
Metrics Vault
Metrics Vault (Хранилище метрик) — это дополнительный уровень, используемый для хранения данных операционных метрик для процессов Data Vault Ingestion. Эта информация может быть бесценной при диагностике потенциальных проблем с data ingestion process. Metrics Vault может также использоваться как контрольный журнал для всех процессов, взаимодействующих с Data Vault.
Information Delivery
Information Marts
Информационные витрины — это то место, где бизнес-пользователи, наконец, получат доступ к данным. Все бизнес-правила и логика теперь применяются в этих витринах.
Для реализации бизнес-правил и логики методология Data Vault также в значительной степени опирается на использование SQL Views вместо создания конвейеров. Views позволяют разработчикам очень быстро реализовывать и согласовывать с бизнесом требования при внедрении информационных витрин. Наличие слишком большого количества конвейеров — это просто еще одна проблема, которую нужно поддерживать и беспокоиться о повторном запуске. Бизнес-пользователи могут отправлять запросы ко Views, зная, что они всегда получают доступ к последним данным.
Error Marts
Error Marts — это дополнительный уровень в Data Vault, который может быть полезен для выявления проблем с данными для бизнес-пользователей. Помните, что все данные, правильные или нет, должны оставаться в качестве исторических данных в Data Vault для аудита и отслеживания.
Metrics Marts
Metrics Mart — это дополнительный уровень, используемый для отображения операционных показателей для аналитических целей или отчетов.
Data Vault Rules v1.0.8 Cheat Sheet
Data Vault Rules v1.0.8 Cheat Sheet.pdf
Базовые правила построения модели Data Vault
При создании модели Data Vault необходимо сначала создать сущности и описать их атрибуты, а затем установить связи между ними. Сущности должны создаваться в следующем порядке.
- Сущности-Hub должны содержать бизнес-ключи предметной области.
- Сущности-Link для поддержки взаимосвязей между бизнес-ключами, т.е. информация о деятельности организации в контексте бизнес-ключей.
- Сущности-Satellite для описания полной картины деятельности организации с точки зрения бизнес-процедур.
- Сущности Point In Time (PIT) для обеспечения поиска моментов времени изменения описательной информации.
При создании связей в структуре модели Data Vault следует соблюдать правила поддержки ссылочной целостности (referential integrity).
- Ключи Hub не могут мигрировать в другие концентраторы, т.е. не поддерживается отношение «родитель-потомок» для Hub.
- Hub взаимодействуют между собой через Link таблицы.
- Сущность-Link может быть использована для связи более двух Hub.
- Сущности-Link могут быть связаны друг с другом.
- Сущности-Link должны связывать минимально два Hub.
- Суррогатные ключи могут использоваться для Hub и Link.
- Бизнес-ключи Hub никогда не изменяются, так же, как и их первичные ключи.
- Satellite могут связываться с Hub и Link.
- Могут быть использованы стандартные таблицы временных меток (standalone table), такие как календарь, время, код и описание.
- Satellite всегда содержат либо временную метку загрузки, либо числовой указатель на временную метку загрузки (на стандартные таблицы временных меток).
- Сущности-Link могут иметь суррогатные ключи.
- Если Hub имеет более двух Satellite, то может быть создана сущность Point In Time.
- В Satellite не должно быть строк-дубликатов.
- Данные в Satellite разделяются по типу информации или по скорости изменения.
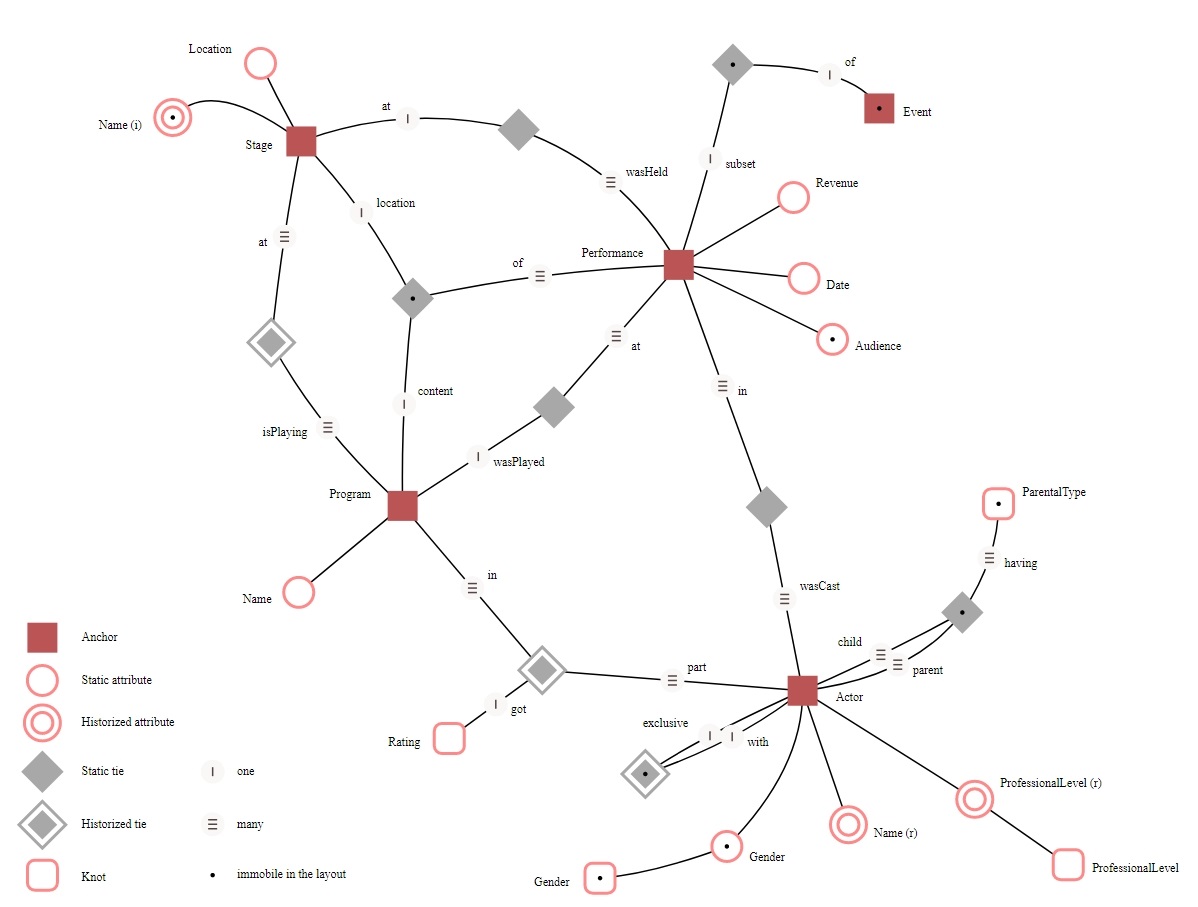
Подход Anchor
Anchor modeling (Якорное моделирование или модель привязки) — это гибкий метод моделирования хранилищ данных, подходящий для информации, которая со временем изменяется как по структуре, так и по содержанию. Он предоставляет графическую нотацию, используемую для концептуального моделирования, аналогичную моделированию сущностей-отношений, с расширениями для работы с временными данными. Техника моделирования включает четыре конструкции моделирования: якорь (привязку), атрибут, связь и узел, каждая из которых отражает различные аспекты моделируемой области. Полученные модели можно преобразовать в проекты физических баз данных с использованием формализованных правил. Когда такой перевод будет выполнен, таблицы в реляционной базе данных будут в основном в шестой нормальной форме.
Эта модель позволяет гибко реагировать на изменения сохраненных данных или добавление новых данных. Это также позволяет более эффективно сжимать данные и быстрее работать с ними.
Например, чтобы добавить новый атрибут к существующей сущности, вы можете просто создать другую таблицу и сообщить аналитикам о необходимости создания для нее соединений.
Пример якорной модели
Подборки видео
Евгений Ермаков: Есть 2 стула — Data Vault и Anchor Modeling, на какой сядешь, на какой DWH посадишь
DataVault / Anchor Modeling / Николай Голов
DataTalks — Лекция 2, Семененко Сергей, Эволюция аналитических хранилищ данных
Принципы построения архитектуры платформы данных
Принцип Data Mesh
Data Mesh по сути относится к концепции разделения озер и хранилищ данных на более мелкие и децентрализованные части. Подобно переходу от монолитных приложений к архитектуре микросервисов в мире разработки программного обеспечения, Data Mesh можно описать как версию микросервисов, ориентированную на данные.
Data Mesh представляет собой новую организационную и архитектурную концепцию, которая бросает вызов традиционной точке зрения, согласно которой большие данные должны быть централизованы, чтобы использовать их аналитический потенциал. Если все данные не хранятся в одном месте и не управляются централизованно, они не могут обеспечить их истинную ценность. В отличие от этого широко распространненого утверждения, Data Mesh утверждает, что большие данные могут способствовать инновациям только тогда, когда они распределяются между владельцами домена данных, которые затем предоставляют данные как продукт.
Демократизация данных — это ключевая предпосылка, на которой основывается концепция Data Mesh и ее невозможно достичь без децентрализации, взаимодействия и приоритизации опыта потребителей данных.
В качестве архитектурной парадигмы Data Mesh открывает огромные перспективы для масштабирования аналитики за счет быстрого предоставления доступа к быстрорастущим распределенным наборам доменов данных. В частности, в случае роста потребления данных, таких как аналитика, машинное обучение или разработка и развертывание приложений, ориентированных на данные.
По своей сути, Data Mesh направлен на устранение недостатков, связанных с традиционной архитектурой платформы, которые привели к созданию централизованных озер или хранилищ данных. В отличие от монолитных инфраструктур для обработки данных, где потребление, хранение, обработка и вывод данных ограничены центральным озером данных, Data Mesh поддерживает распределение данных по определенным доменам. Подход «данные как продукт» позволяет владельцам разных доменов независимо обрабатывать свои собственные конвейеры данных.
Data Mesh устраняет пробелы в традиционном подходе к управлению большими данными:
- Монолитные платформы не могут угнаться за ними: монолитным платформам данных, таким как DWH и Data Lakes, часто не хватает разнообразия источников данных и предметно-ориентированных структур, необходимых для получения ценной информации из растущих объемов данных. В результате на этих централизованных платформах теряются важные знания, относящиеся к конкретной предметной области. Это ограничивает способность инженеров по обработке данных устанавливать значимые корреляции между различными точками данных для создания точной аналитики, отражающей операционные реалии.
- Конвейеры данных порождают узкие места: в их традиционной форме конвейеры данных создают узкие места из-за изоляции процессов приема, преобразования и доставки данных.
- Различные отделы, работающие с разными наборами данных, работают без взаимного сотрудничества. Фрагменты данных по существу передаются от одной команды к другой без какой-либо значимой интеграции и преобразования.
- Эксперты по данным, работают с разными целями: гиперспециалисты по обработке данных, владельцы источников и потребители часто в конечном итоге работают с разными целями, поскольку у всех них совершенно разные точки зрения. Это часто сильно снижает продуктивность.
3 ключевых компонента Data Mesh
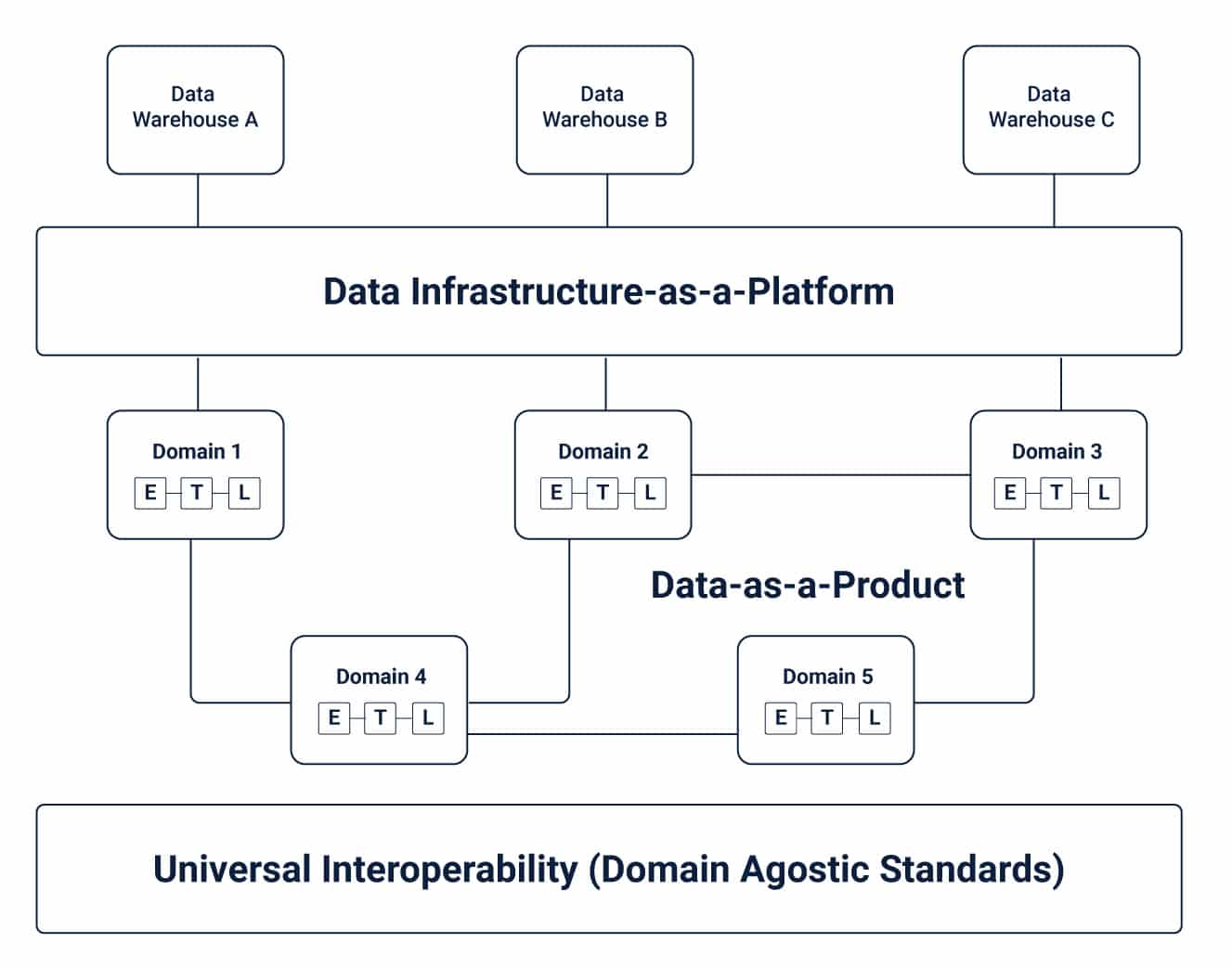
Для бесперебойной работы Data Mesh требуются различные элементы — инфраструктура данных, источники данных и доменно-ориентированные конвейеры. Каждый из этих элементов важен для обеспечения универсальной совместимости, наблюдаемости, управления, а также для поддержки независимых от предметной области стандартов в архитектуре ячеистой сети данных.
Следующие ключевые компоненты играют решающую роль в обеспечении соответствия Data Mesh этим стандартам:
- Владельцы и конвейеры данных, ориентированные на предметную область: сетки данных объединяют владение данными между различными владельцами доменов, которые несут ответственность за предложение своих данных в качестве продукта, а также облегчают обмен данными между различными местами, по которым данные были распределены. Хотя каждый домен отвечает за владение своим конвейером извлечения-преобразования-загрузки (ETL) и управление им, к разным доменам применяется набор возможностей для облегчения хранения, каталогизации и доступа к необработанным данным. Владельцы доменов могут использовать данные для операционных или аналитических нужд после того, как они были доставлены в данный домен и должным образом преобразованы.
- Функциональность самообслуживания: одна из основных проблем, связанных с предметно-ориентированным подходом к управлению данными — это дублирование усилий по поддержке конвейеров и инфраструктуры в каждом из них. В концепции Data Mesh инфраструктура данных для реализации конвеера данных должна поставляться централизовано. Каждый домен использует компоненты, необходимые для работы их конвейеров ETL. Эта функция самообслуживания позволяет владельцам доменов сосредоточиться на конкретных случаях использования данных.
- Функциональная совместимость и стандартизация коммуникаций: каждый домен поддерживается базовым набором универсальных стандартов данных, которые во многом прокладывают путь для совместной работы там, где это необходимо. Это очень важно, потому что один и тот же набор необработанных и преобразованных данных неизбежно может иметь значение для более чем одного домена. Стандартизация функций данных, таких как управление, обнаруживаемость, формирование, спецификации метаданных, обеспечивает междоменное сотрудничество.
4 основных принципа и логическая архитектура Data Mesh
Парадигма Data Mesh основана на четырех основных принципах, каждый из которых интуитивно направлен на решение многих проблем, создаваемых до сих пор централизованным подходом к управлению большими данными и аналитике данных.
- Доменно-ориентированная децентрализованная собственность и архитектура данных: по своей сути Data Mesh стремится децентрализовать ответственность за распространение данных на тех, кто работает в тесном сотрудничестве с ней, ради поддержки масштабируемости и непрерывного внедрения изменений. Декомпозиция и децентрализация данных достигаются путем встряхивания экосистемы данных, включающей аналитические данные, метаданные и дополняющие их вычисления. Поскольку сегодня большинство организаций децентрализованы по доменам, в которых они работают, декомпозиция данных также выполняется по той же оси. Это локализует результаты эволюции и непрерывных изменений по отношению к ограниченному контексту домена. Следовательно, создание правильной экосистемы для распределения прав собственности на данные.
- Данные как продукт. Одной из ключевых проблем, связанных с архитектурой монолитных данных, является высокая стоимость и сложности для процессов data discovering, data trusting, а также обеспечить понимание данных и обеспечить качество данных. Эту проблему можно было бы многократно усилить в Data Mesh, учитывая увеличение количества доменов данных. Принцип «данные как продукт» рассматривался как эффективное решение проблем устаревших разрозненных данных и качества данных в них. Здесь аналитические данные рассматриваются как продукт, а те, кто использует эти данные, как клиенты. Использование таких возможностей, как обнаружение данных, понятность, безопасность и надежность данных, становится обязательным условием для использования данных в качестве продукта.
- Инфраструктура данных самообслуживания как платформа: Создание, развертывание, доступ и мониторинг «данных как продукт» требуют обширной инфраструктуры и навыков для их предоставления. Репликация этих ресурсов для каждого домена, созданного с использованием подхода Data Mesh, была бы невозможна. Что еще более важно, разным доменам может потребоваться доступ к одному и тому же набору данных. Для исключения дублирования усилий и ресурсов используется высокоуровневая абстракция инфраструктуры. Именно здесь вступает в игру принцип самообслуживания инфраструктуры данных как платформы. По сути, это расширение существующих платформ доставки, необходимое для запуска и мониторинга различных сервисов. Платформа данных самообслуживания включает инструменты, способные поддерживать рабочий процесс разработчика домена с минимальными специальными навыками и ноу-хау. В то же время он должен быть в состоянии снизить затраты на создание продуктов для обработки данных.
- Федеративное управление вычислениями: Data Mesh включает в себя архитектуру распределенной системы, которая является автономной и создается и поддерживается независимыми группами. Чтобы получить оптимальную отдачу от такой архитектуры, необходимо взаимодействие между независимыми продуктами. Федеративная вычислительная модель управления предлагает именно это. В этом случае объединению владельцев продуктов домена и платформы доверяется автономия в принятии решений при работе в рамках определенных глобальных правил. Это, в свою очередь, приводит к здоровой экосистеме взаимодействия.
Зачем использовать Data Mesh?
До сих пор большинство организаций использовали отдельные хранилища данных или озера данных как часть инфраструктуры больших данных для удовлетворения своих потребностей в бизнес-аналитике. Такие решения внедряются, управляются и обслуживаются небольшим кругом специалистов, которые часто борются с огромными техническими долгами. В результате группа данных, у которой имеется накопившаяся информация, изо всех сил пытается справиться с растущими бизнес-требованиями, разрыв между производителями и пользователями данных и растущее нетерпение среди потребителей данных.
Напротив, децентрализованная структура, такая как Data Mesh, сочетает в себе лучшее из обоих миров — централизованную базу данных и децентрализованные домены данных с независимыми конвейерами — для создания более жизнеспособной и масштабируемой альтернативы.
Data Mesh способна устранить все недостатки озер данных, обеспечивая большую гибкость и автономность владения данными. Это приводит к расширению возможностей для экспериментов с данными и инноваций, поскольку бремя снимается с рук нескольких избранных экспертов.
В то же время инфраструктура самообслуживания как платформа открывает возможности для гораздо более универсального, но автоматизированного подхода к стандартизации данных, а также к сбору и обмену данными.
В целом преимущества Data Mesh выражаются в несомненном конкурентном преимуществе по сравнению с традиционными архитектурами данных.
Подборка видео по Data Mesh
Дмитрий Шостко: Как построить Data Mesh в организации
Keynote — Data Mesh by Zhamak Dehghani
Что такое Data Fabric (фабрика данных)?
Фабрика данных — это комбинация архитектуры, технологий и сервисов, разработанная для облегчения сложностей управления множеством различных типов данных с использованием нескольких систем управления базами данных и развертываемых на множестве платформ. Он предоставляет единую унифицированную платформу для управления данными с использованием нескольких технологий и платформ развертывания. Следует выделить один ключевой момент в этом определении: фабрика данных — это комбинация архитектуры, технологий и сервисов. Сама по себе архитектура не создает структуру данных, но архитектура является ее неотъемлемой частью.
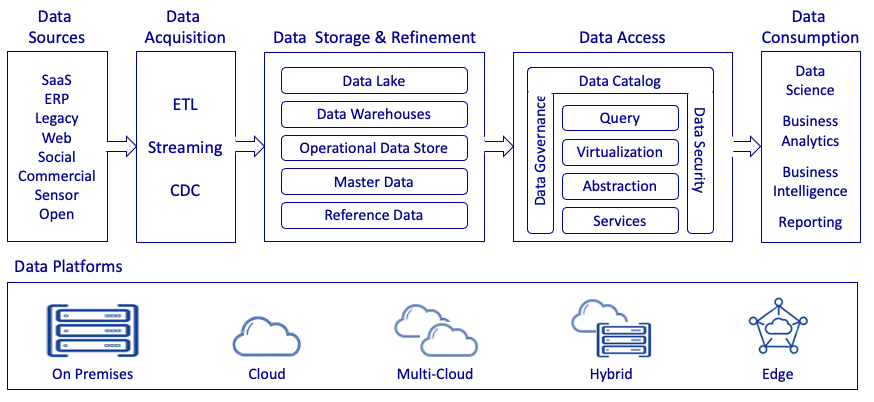
Data Fabric использует непрерывную аналитику существующих, обнаруживаемых и предполагаемых активов метаданных для поддержки проектирования, развертывания и использования интегрированных и повторно используемых данных во всех средах, включая гибридные и мультиоблачные платформы.
Фабрика данных — это единая среда, состоящая из унифицированной архитектуры и служб или технологий, работающих на этой архитектуре, которая помогает организациям управлять своими данными.
Подумайте о фабрике данных как о переплетении, растянутом на большом пространстве, которое соединяет несколько местоположений, типов и источников данных с методами доступа к этим данным. Данные можно обрабатывать, управлять и хранить по мере их перемещения в фабрике данных. К данным также можно получить доступ или поделиться ими с внутренними и внешними приложениями для широкого спектра аналитических и операционных сценариев использования для всех организаций, включая расширенную аналитику для прогнозирования, разработки продуктов и оптимизации продаж и маркетинга.
Пример архитектуры Data Fabric
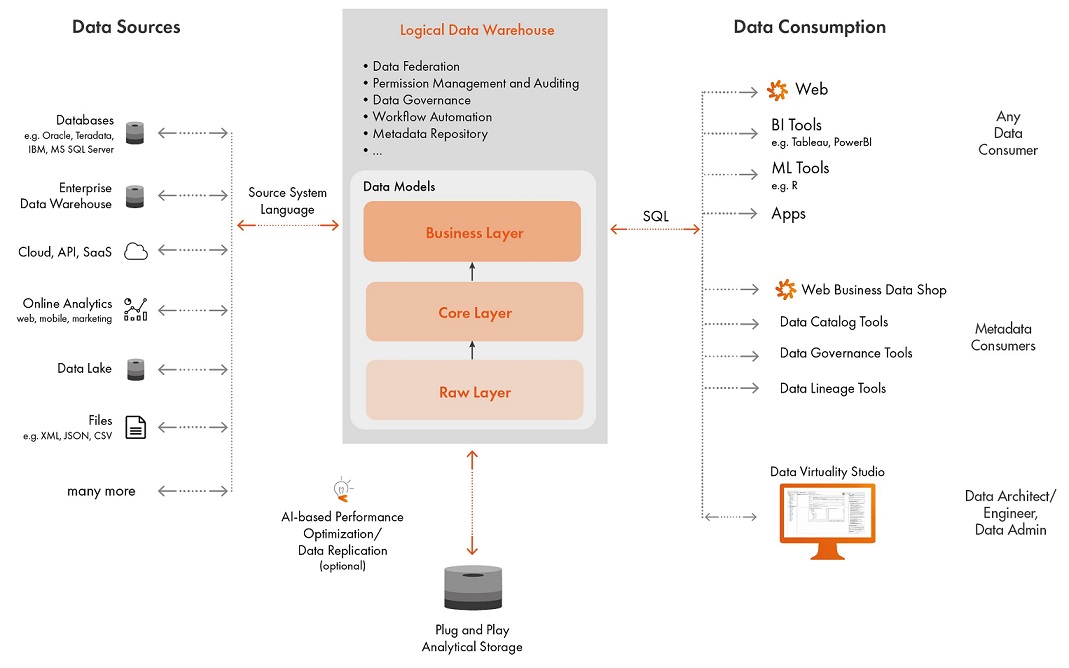
Фабрика данных должна обеспечивать беспрепятственный доступ и совместное использование данных в распределенной среде данных. Она должна обеспечивать единую и согласованную структуру управления данными.
Строительные блоки архитектуры Big Data Fabric
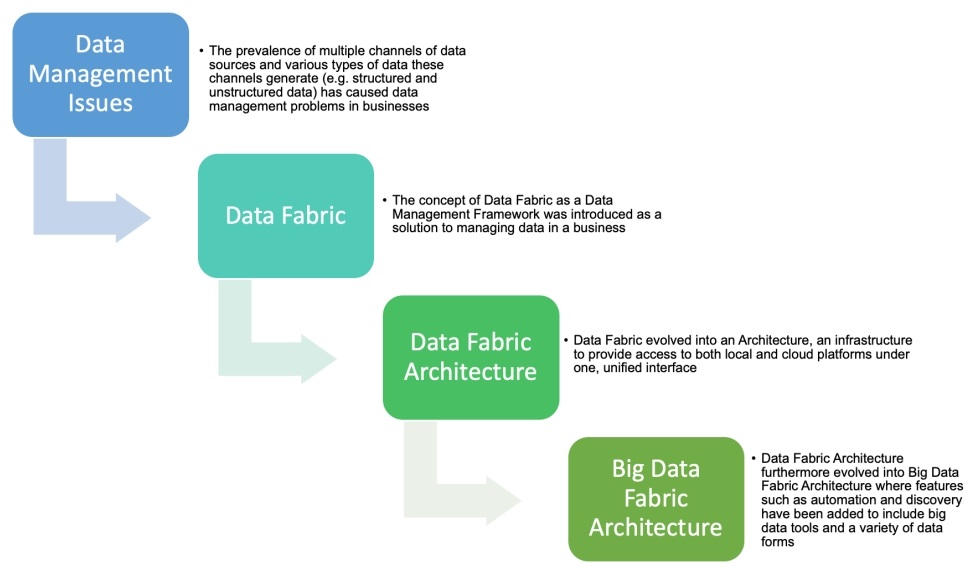
Уровни архитектуры Big Data Fabric
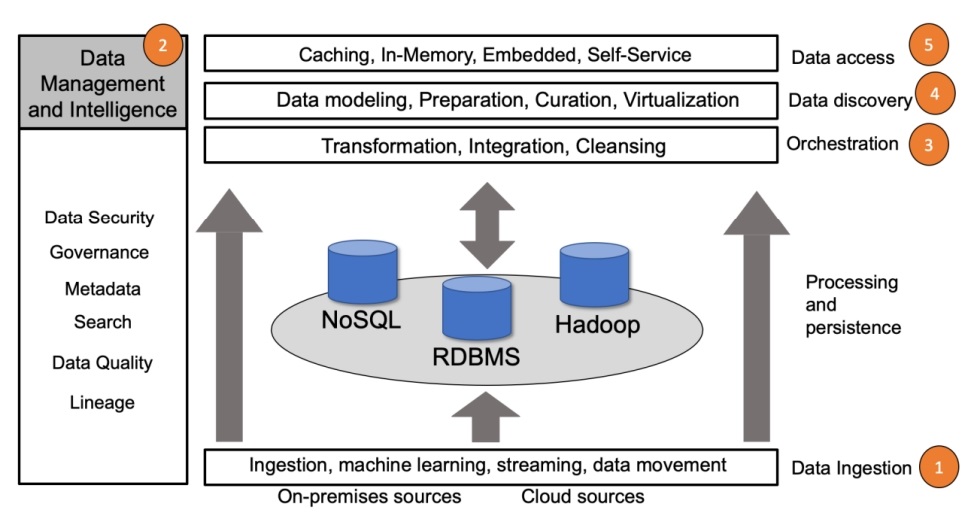
Архитектура Big Data Fabric состоит из аналитических инструментов Big Data и следующих 5 слоев:
- Data Ingestion (Прием данных): данные загружаются в репозитории больших данных.
- Data Management and Intelligence (Управление данными и аналитика): как данные обрабатываются, защищаются, управляются, как выдается доступ и другие связанные процессы.
- Orchestration (Оркестровка): данные интегрируются и преобразуются в значимую информацию, которая используется бизнес-пользователями.
- Data Discovery (Обнаружение данных): доступные данные, которые могут видеть пользователи.
- Data Access (Доступ к данным): интерфейс для поиска доступных в компании данных и для отправки запроса на доступ к найденным данным.
Data Warehouse — Корпоративное хранилище данных
Enterprise Data Warehouse (EDW) является одной из форм корпоративного хранилища, которое хранит и управляет всеми историческими бизнес-данными предприятия.
Информация обычно поступает из разных систем, таких как ERP, CRM, самописные DB и плоские файлы (Excel, csv, Google Sheet). Чтобы подготовить данные для дальнейшего анализа, их необходимо поместить в единое хранилище. Таким образом, различные бизнес-подразделения могут запрашивать и анализировать информацию с разных сторон.
Принципы построения DWH
- Отражаются исходные данные: Enterprise DWH получает данные из различных систем хранения данных, таких как ERP, Google Analytics, CRM, External API Sources, Google Sheet и т.д. Данные в хранилище данных не создаются, то есть поступают из внешних источников, не корректируются и не удаляются.
- Интегрированность: Данные объединены так, чтобы они удовлетворяли всем требованиям предприятия в целом, а не единственной функции бизнеса.
- Хранится структурированные данные: Данные, хранящиеся в Enterprise DWH, всегда стандартизированы и структурированы. Это позволяет конечным пользователям запрашивать их через интерфейсы бизнес-аналитики и формировать отчеты. И это то, что отличает хранилище данных от озера данных. Озера данных используются для хранения в аналитических целях как структурированных, так и неструктурированных данных. Но в отличие от хранилищ, озера данных больше используются data engineers/data scientists для работы с большими наборами необработанных данных.
- Содержат предметно-ориентированные данные: Основное внимание в хранилище уделяется бизнес-данным, которые могут относиться к разным доменам. Чтобы понять, к чему относятся данные, они всегда структурированы вокруг определенного subject, называемого data model (моделью данных). Примером subject может быть регион продаж или общий объем продаж данного товара. Кроме того, добавляются метаданные, чтобы подробно объяснить, откуда берется каждая часть информации.
- Зависимость от времени: Собранные данные обычно представляют собой исторические данные, поскольку они описывают прошлые события. Чтобы понять, когда и как долго имела место определенная тенденция, большинство хранимых данных обычно делятся на периоды времени.
- Энергонезависимость: После помещения на склад данные никогда не удаляются из него. Данными можно манипулировать, изменять или обновлять из-за изменений источника, но они никогда не предназначены для удаления, по крайней мере, конечными пользователями. Когда мы говорим об исторических данных, удаление контрпродуктивно для аналитических целей. Тем не менее, общие пересмотры могут происходить раз в несколько лет, чтобы избавиться от нерелевантных данных.
Типы хранилищ данных
Классическое хранилище данных
Классическое DWH — это унифицированное хранилище со специальным оборудованием и программным обеспечением. С физическим хранилищем вам не нужно настраивать инструменты интеграции данных между несколькими базами данных. Вместо этого EDW можно связать с источниками данных через API, чтобы постоянно получать информацию и преобразовывать ее в процессе. Итак, вся работа выполняется либо в области подготовки (место, где данные преобразуются перед загрузкой в DW), либо в самом хранилище.

Наиболее часто встречается схема, в которой данные перемещаются между несколькими областями:
- Область временного хранения данных (Staging Area) – необходима для временного хранения данных, которые извлекаются из исходных систем (баз данных, api, плоских файлов и т.п.). Эта область является промежуточным слоем между источниками данных и самим DWH;
- Область постоянного хранения данных, включает в себя:
- Детальные данные (System of records or Raw data) – здесь хранятся детальные данные, которые приведены к структуре модели данных корпоративного хранилища, а также прошли процессы очистки и обогащения;
- Агрегаты (Summary data) – агрегированные (другими словами сгруппированные) по времени детальные данные;
- Витрины данных (Data Marts) – тематические наборы данных, хранящиеся в пригодном для анализе виде (например, схема «Звезда» или схема «Снежинка»). Data Marts ориентированы на анализ данных по конкретным бизнес-процессам, приложениям, подразделениям компании, а также для анализа бизнес-целей;
- Интерфейсы обмена данными с другими системами (Data Exchange Interface или API) – таблицы БД или API, которые возвращают подготовленные данные для передачи в другие информационные системы компании из DWH;
- Метаданные (Metadata) – важная часть архитектуры DWH. Метаданные — это данные, которые описывают правила, по которым функционирует хранилище данных. Например, с точки зрения базы данных хранилища, метаданными является описание структур таблиц, взаимосвязей между ними, правил секционирования, описание витрин данных и т.п. С точки зрения ETL, метаданные — это описания правил извлечения и преобразования данных, периодичность запуска ETL операций и т.п.
Классическое хранилище данных считается лучшим вариантом по сравнению с виртуальным, потому что здесь нет дополнительного уровня абстракции. Это упрощает работу инженеров по обработке данных и упрощает управление потоком данных на стороне предварительной обработки, а также для формирования фактической отчетности.
Недостатки классического DWH зависят от конкретной реализации, но для большинства предприятий это:
- Дорогая технологическая инфраструктура, как аппаратная, так и программная;
- Найм команды инженеров по обработке данных и специалистов DevOps для настройки и обслуживания всей платформы данных;
Когда следует использовать DWH: подходит для организаций любого размера, которые хотят обрабатывать свои данные и использовать их. Классические хранилища позволяют трансформироваться в различные архитектурные стили платформы данных, а также целенаправленно увеличивать и уменьшать масштаб.
Виртуальное хранилище данных
Виртуальное DWH — это несколько баз данных, подключенных виртуально, поэтому к ним можно обращаться как к единой системе.
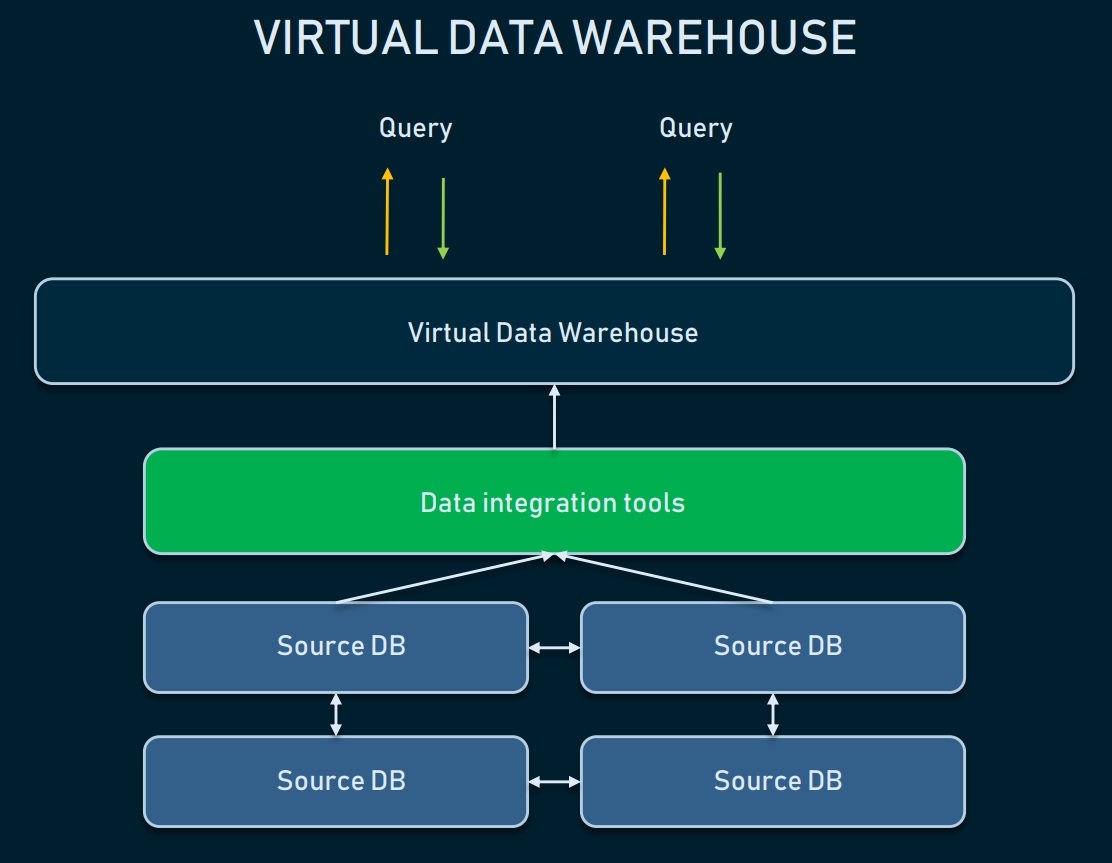
Такой подход позволяет организациям упростить задачу: данные могут оставаться в своих источниках, но их по-прежнему можно извлекать с помощью аналитических инструментов. Виртуальные хранилища можно использовать, если вы не хотите возиться со всей базовой инфраструктурой или если существующими данными легко управлять.
Однако у такого подхода много недостатков:
- Несколько баз данных потребуют постоянного обслуживания программного и аппаратного обеспечения, а следовательно нести расходы.
- Данные, хранящиеся в виртуальном хранилище данных, по-прежнему требуют программного обеспечения для преобразования, чтобы сделать их удобоваримыми для конечных пользователей и инструментов отчетности.
- Сложные запросы данных могут занять слишком много времени, так как необходимые фрагменты данных могут быть помещены в две отдельные базы данных.
Когда использовать: подходит для предприятий, которые имеют необработанные данные в стандартизированной форме, не требующей сложной аналитики. Виртуальное DWH также подходит организациям, которые не используют бизнес-аналитику систематически или только внедряют BI.
Облачное хранилище данных
Облачные технологии в последние годы стали стандартом для использования на уровне всей организации. На рынке вы найдете бесчисленное количество поставщиков, предлагающих DWH как услугу.
Примеры:
- Amazon Redshift
- IBM Db2
- Google BigQuery
- Snowflake
- Microsoft SQL Data Warehouse (Azure Synapse Analytics)
Все упомянутые поставщики предлагают управляемое и масштабируемое хранилище, как часть своих инструментов бизнес-аналитики или сосредоточены на EDW как на отдельной услуге, как это делает Snowflake. В этом случае архитектура облачного хранилища имеет те же преимущества, что и любой другой облачный сервис. Его инфраструктура обслуживается за вас, а это означает, что вам не нужно настраивать собственные серверы, базы данных и инструменты для управления инфраструктурой. Цена на такую услугу будет зависеть от объема необходимой памяти и количества вычислительных мощностей для выполнения запросов.
Единственный аспект, который может беспокоить с точки зрения платформы облачного хранилища — это безопасность данных. Ваши бизнес-данные — очень важная вещь. Также не последним фактором является цена услуг.
Когда использовать: облачные платформы — отличный выбор для организаций любого размера. Если вам нужно все быстро настроить, включая интеграцию данных, обслуживание DWH и поддержку BI. Вам не придется задумываться о таких вещах как обновление ПО, миграции с одного сервера на другой в случае кратного роста объема данных.
Стадии Data Warehouse Design
Как и в операционных базах данных, существует два основных метода проектирования хранилищ данных и витрин данных. При подходе сверху вниз требования пользователей на разных уровнях организации объединяются до начала процесса проектирования, и создается одна схема для всего хранилища данных, из которой могут быть получены витрины данных. При восходящем подходе для каждой витрины данных создается схема в соответствии с требованиями пользователей каждой области бизнеса. Созданные схемы витрин данных затем объединяются в схему глобального хранилища. Выбор между подходом «сверху вниз» и «снизу вверх» зависит от многих факторов.

До сих пор нет единого мнения по поводу этапов, которые следует соблюдать при проектировании хранилища данных. Большинство книг в литературе по хранилищам данных придерживаются восходящего, практического подхода к проектированию, основанного на реляционной модели, с использованием схем звезды, снежинки и созвездия.
Логическое моделирование хранилищ данных
Существует несколько подходов к реализации многомерной модели в зависимости от того, как хранится куб данных. Вот эти подходы:
- Реляционный OLAP (Relational OLAP — ROLAP) — данные хранятся в реляционных базах данных и поддерживает расширения SQL и специальные методы доступа для эффективной реализации многомерной модели данных и связанных операций.
- Многомерный OLAP (Multidimensional OLAP — MOLAP) — данные хранятся в специализированных многомерных структурах данных (например, массивах) и реализует операции OLAP над этими структурами данных.
- Гибридный OLAP (Hybrid OLAP — HOLAP) — сочетается оба подхода.
Подборка видео по DWH
Основы теории создания хранилищ данных (DWH). Вячеслав Ерин, АНАЛИТИКА ПЛЮС
Data Vault vs Traditional Data Warehouse Architectures
Data Lakes
Введение в Озера данных
Когда у вас большой объем данных, их хранение в базе данных или хранилище данных может быть дорогостоящим. Кроме того, данные, поступающие в хранилища данных, должны быть обработаны, прежде чем их можно будет сохранить в какой-либо схеме или структуре. Другими словами, у него должна быть модель данных, что не всегда возможно.
В ответ компании начали поддерживать озера данных, которые хранят все структурированные и неструктурированные корпоративные данные в одном месте. И они стараются сделать это наиболее экономичным способом.
Data Lake (Озеро данных) — это система или централизованное хранилище данных, которое позволяет хранить все ваши структурированные, полуструктурированные, неструктурированные и двоичные данные в их естественном / исходном / необработанном формате, которые кому-либо в организации может понадобиться проанализировать.
Структурированные данные могут включать таблицы из СУБД; полуструктурированные данные включают файлы CSV, файлы XML, журналы, JSON и т.д .; неструктурированные данные могут включать PDF-файлы, текстовые документы, текстовые файлы, электронные письма и т.д.; а двоичные данные могут включать в себя файлы аудио, видео и изображения.
Озеро данных это плоская архитектура для хранения данных. Как правило, данные хранятся в виде больших двоичных объектов или файлов.
С помощью Data Lake вы можете хранить все данные компании «как есть» в одном месте, без необходимости предварительно структурировать и обрабатывать данные. Вы можете напрямую на нем строить различные типы аналитики, включая машинное обучение, аналитику в реальном времени, on-premises data-movement, real-time data movement, создавать панели мониторинга и визуализации.
Он сохраняет все данные в нем в исходном виде и предполагает, что анализ будет проведен позже, по запросу.
Цель озера данных — предоставить необработанное представление данных (данные в их чистом виде).
В настоящее время многие крупные компании, включая Google, Amazon, Cloudera, Oracle, Microsoft и некоторые другие, предлагают Data Lake.
Многие организации используют службы облачного хранения, такие как Azure Data Lake или Amazon S3. Компании также используют распределенную файловую систему, такую как Apache Hadoop. Также эволюционировала концепция озера личных данных, которое позволяет вам управлять собственными большими данными и делиться ими.
Если говорить о промышленном использовании, то он очень подходит для сферы здравоохранения. Из-за неструктурированного формата большого количества данных в сфере здравоохранения (например, заметок врача, клинических данных, истории болезни пациента и т.д.) и необходимости получения аналитических данных в реальном времени озеро данных является отличным вариантом по сравнению с хранилищем данных.
Схема при записи (Schema Read) и Схема при чтении (Schema Write)
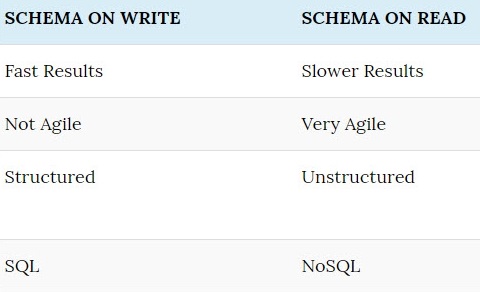
Прежде чем пойти дальше, разберем такие понятия как схема при чтении и схема при записи.
Схема при записи — создание схемы для данных происходит перед записью в базу данных. Эта конструкция тесно связана с управлением реляционной базой данных, включая создание схемы и таблицы, а также прием данных. Данные не могут быть загружены в таблицы без создания и настройки схем и таблиц. В противоположность этому, рабочая структура базы данных не может быть определена без понимания структуры данных, которые должны быть загружены в базу данных. Одна из самых трудоемких задач при работе с реляционной базой данных — выполнение работы с извлечением и преобразованием данных (ETL).
Схема при чтении — схема базы данных создается при чтении данных. Структуры данных не применяются и не инициируются до того, как данные будут загружены в базу данных. Таким образом схема создается в процессе ETL. Это позволяет хранить неструктурированные данные в базе данных. Основная причина разработки схемы при чтении — стремительный рост объемов неструктурированных данных и высокие накладные расходы, связанные с процессом схемы при записи.
Жизненный цикл Data Lake
Уровни архитектуры озера данных
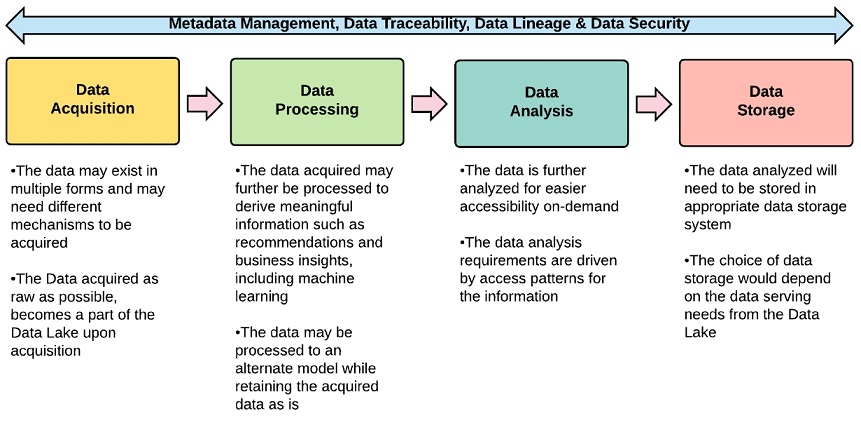
Обработку данных в Data Lakes можно условно организовать в следующей концептуальной модели:
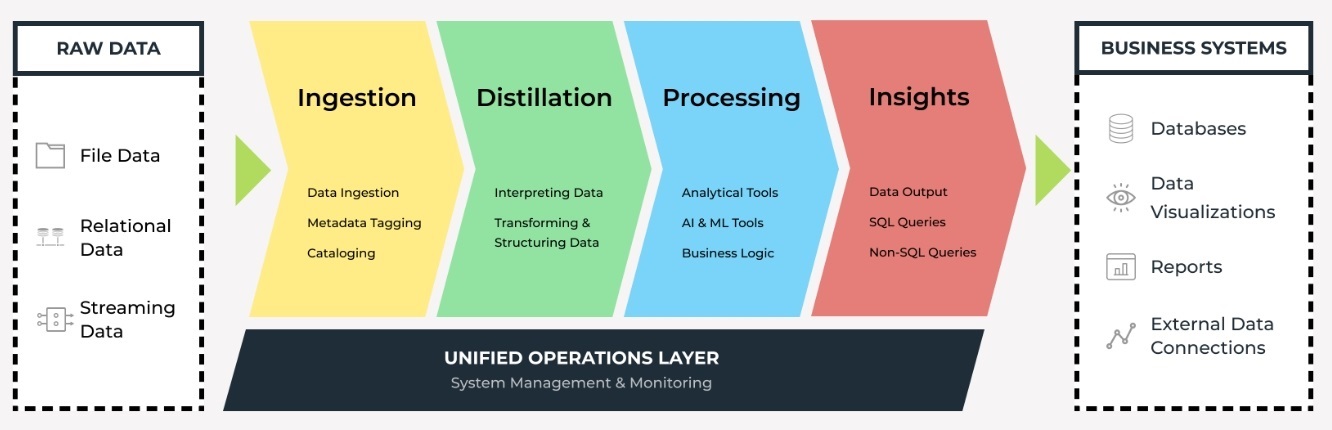
Ingestion Layer (Слой приёма данных)
Слой приема данных выполняет задачу по получению необработанных данных в озеро данных. Модификация необработанных данных запрещена. Необработанные данные можно загружать партиями, а также в режиме реального времени. Данные организованы в логическую структуру папок. На уровне приема можно размещать данные из различных внешних источников, таких как:
- Социальные сети
- IoT устройства
- Гаджеты
- Устройства потоковой передачи данных
Одним из преимуществ Data Lake является то, что оно может быстро принимать практически любой тип данных, охватывающий любую систему, включая (но не ограничиваясь):
- Данные в реальном времени с подключенных устройств для мониторинга состояния
- Видеопотоки с камер видеонаблюдения
- Видео, фотографии или геолокационные данные с мобильных телефонов
- Все типы данных телеметрии
Distillation Layer (Слой дистилляции)
Уровень дистилляции преобразует данные, хранящиеся на уровне приема, в структурированные данные для дальнейшего анализа. На этом уровне необработанные данные интерпретируются и преобразуются в наборы структурированных данных и впоследствии сохраняются в виде файлов или таблиц. На этом этапе данные очищаются, денормализуются и выводятся, а затем становятся единообразными с точки зрения кодирования, формата и типа данных.
Processing Layer (Слой обработки)
Уровень обработки запускает пользовательские запросы и расширенные аналитические инструменты для структурированных данных. Процессы могут выполняться в режиме реального времени, пакетно или в интерактивном режиме. На этом уровне применяется бизнес-логика и данные используются аналитическими приложениями. Этот слой также известен как trusted, gold или production-ready.
Insights Layer (Слой аналитики)
Уровень Insights — это выходной интерфейс или интерфейс запросов озера данных. Он поддерживает запросы SQL или NoSQL для вывода данных в отчетах или информационных панелях.
Unified Operations Layer (Уровень унифицированных операций)
Уровень унифицированных операций выполняет мониторинг системы и предоставляет инструменты для управления системой, через использование workflow management, аудит и proficiency management.
В некоторых реализациях в Data Lake также включен уровень песочницы (Sandbox Layer). Как следует из названия, это место для исследования данных специалистами по данным и продвинутыми аналитиками. Слой песочницы также называют уровнем исследования или уровнем науки о данных.
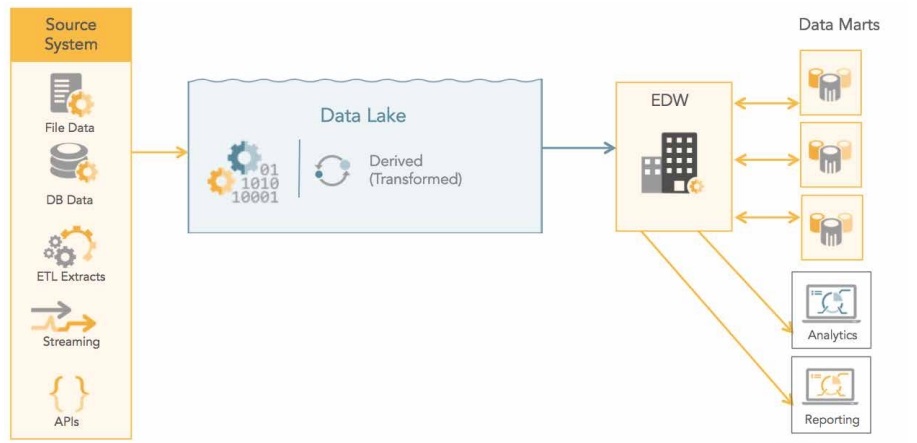
Hybrid Data Lake
Hybrid Data Lake — это объединение Data Lake и Data Warehouse в единую экосистему данных. Комбинированный подход позволяет покрывать все потребности компании по хранению данных, а также быстрого доступа к этим данным для всех заинтересованных лиц.
Пример архитектуры Hybrid Data Lake:
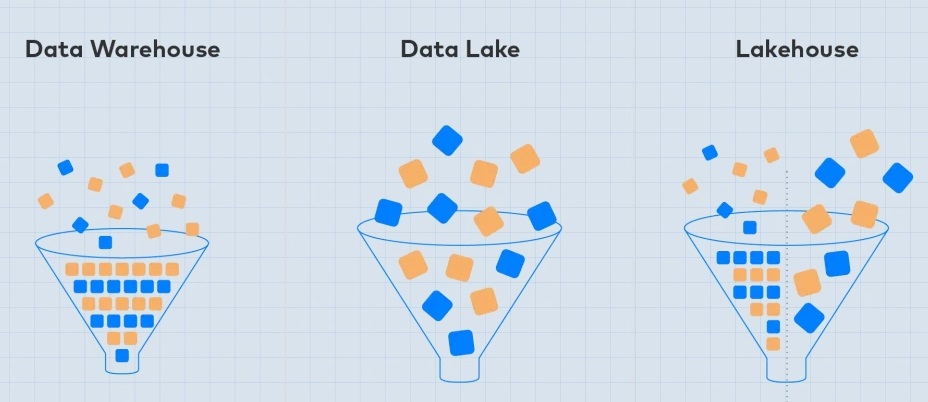
Data Lakehouse
Data Lakehouse — это новая открытая архитектура, сочетающая в себе лучшие элементы озер данных и хранилищ данных. Одним из ключевых преимуществ хранилища данных является использование схем реляционных баз данных для определения структурированных данных, что обеспечивает быструю аналитику и совместимость с SQL. Озера данных, с другой стороны, превосходят хранилища данных своей гибкостью для хранения неструктурированных данных.

Плюсы Data Lake
- «Схема при чтении» обеспечивает большую гибкость по сравнению со «Схемой при записи».
- Интеграция данных с различной структурой намного проще.
- Необработанные данные всегда остаются нетронутыми.
- Анализ данных можно провести позже, когда это потребуется, и повторить при необходимости.
- Одни и те же исходные данные можно интерпретировать по-разному для разных нужд.
- Озера данных гораздо более масштабируемы, чем традиционные хранилища данных.
Минусы озера данных
- Неструктурированные данные и отсутствие метаданных могут привести к тому, что озеро данных превратится в «болото данных», где трудно найти полезные данные.
- Специалистам по обработке данных может потребоваться дополнительное обучение для успешного извлечения данных из озера данных.
- Неопытные пользователи могут начать сбрасывать данные в озеро данных, не имея жизнеспособной стратегии или плана по извлечению ценной информации.
Подборки видео по теме Data Lake & Data Lakehouse
What is a Data Lake?
Программные стеки, используемые в озерах данных
Microsoft Azure
- Azure Data Lake — интегрированное решение для озера данных
- Хранилище озера данных Azure — Облачное хранилище озера данных
- Data Lake Analytics — служба заданий аналитики по требованию
- HDInsight — управляемый Hadoop для аналитики с открытым исходным кодом
Data Platform Architecture
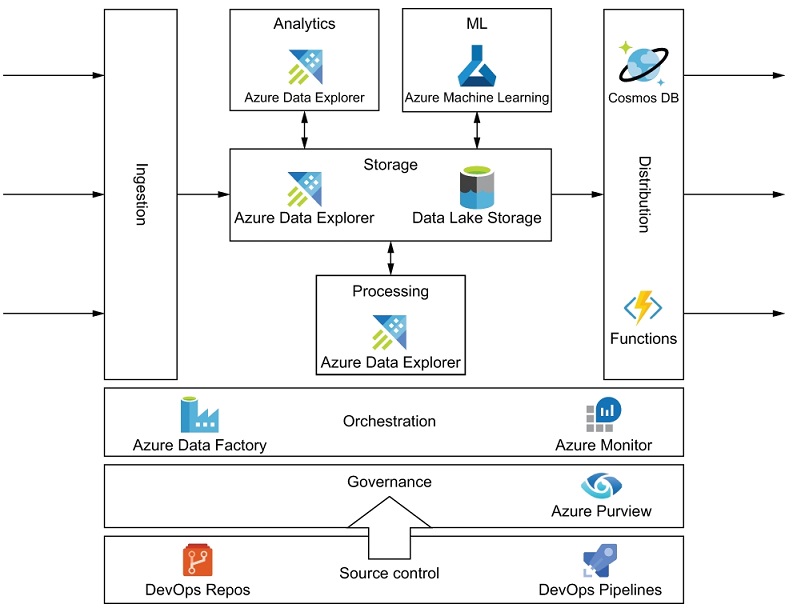
Data engineering in Microsoft Azure
- Self-managed data engineering services (IaaS)
- Azure-managed data engineering services (PaaS)
- Data engineering as a service (SaaS)

Amazon AWS
- Amazon S3 — Облачное хранилище озера данных
- Amazon S3 Glacier — архивное облачное хранилище
- AWS Glue — подготовка данных загрузки и каталога
- AWS Data Exchange — поиск и использование сторонних данных
- Amazon Athena — интерактивная аналитика озера данных
- Amazon EMR — управляемая служба Hadoop для аналитики с открытым исходным кодом
- Amazon Kinesis — Аналитика в реальном времени
- Amazon Elasticsearch Service — операционная аналитика и индексирование
- Amazon Quicksight — информационные панели и визуализация
Облачная платформа Google
- Google Cloud Storage — Облачное хранилище
- Dataproc — управляемая служба Hadoop для аналитики с открытым исходным кодом
- BigQuery — интерактивная аналитика озера данных
Google Storage Decision Tree

Ключевые отличия DWH и Data Lakes
- Разные цели. Хранилища данных используются менеджерами, аналитиками и другими бизнес-конечными пользователями, в то время как озера данных в основном используются специалистами по обработке данных и инженерами по данным. Напомним, что в Data Lake хранятся в основном необработанные неструктурированные и полуструктурированные данные — телеметрия, графика, журналы поведения пользователей, метрики веб-сайтов и информационные системы, а также другие данные с различными форматами хранения. Они пока не подходят для повседневной аналитики в системах бизнес-аналитики, но могут использоваться специалистами по анализу данных для проверки новых бизнес-гипотез с использованием статистических алгоритмов и методов машинного обучения.
- Различные методы обработки. ETL — это популярная парадигма обработки данных во многих популярных хранилищах данных. По сути, мы извлекаем данные из источника или источников, очищаем их, преобразуем в нужную нам структурированную информацию и загружаем ее. С Data Lakes мы используем другую парадигму ELT (извлечение, загрузка, преобразование), потому что преобразование происходит на более поздних этапах и только в случае необходимости, а не заранее.
- Разные уровни понимания данных. В Data Lakes данные никогда не отклоняются, потому что они хранятся в необработанном формате. Это особенно полезно в среде с большими данными, если вы заранее не знаете, какая информация будет получена в результате анализа данных. В то же время центральные базы данных являются основой среды хранилища данных. Обычно такие базы данных реализуются по технологии РСУБД, и поэтому требуется необходимое углубленное проектирование модели данных.
- Разные подходы к дизайну. Дизайн хранилища данных основан на логике реляционной обработки данных — третьей нормальной форме для нормализованного хранения, схемах хранения в виде звезды или снежинки. При проектировании озера данных архитектор больших данных и инженер данных уделяют больше внимания процессам ETL, принимая во внимание разнообразие источников и потребителей информации. А вопрос с хранилищем решается довольно просто — вам нужна только масштабируемая, отказоустойчивая и относительно дешевая файловая система, например HDFS или AWS S3.
- Разная цена. Обычно Data Lake строится на основе дешевых серверов с Apache Hadoop, без дорогих лицензий и мощного оборудования, в отличие от больших затрат на обслуживание, а также больших затрат на проектирование и покупку специализированных платформ для хранилищ данных, таких как SAP, Oracle, Teradata и т.д.
Подборки видео DWH vs Data Lake
Чем классическое DWH отличается от озера данных?
ETL, ELT, Data Pipelines, Оркестрация
ETL
ETL (извлечение-загрузка-преобразование) — это наиболее распространенный подход к интеграции данных, практика консолидации данных из разрозненных исходных систем с целью улучшения доступа к данным. История все та же: у предприятий есть море данных (облачные приложения, CRM-системы, плоские файлы, данные из API и т.д.) и понимание этих данных способствует повышению эффективности бизнеса. ETL играет центральную роль в этом поиске: это процесс превращения необработанных, беспорядочных данных в очищенные, актуальные и надежные данные, из которых можно извлечь бизнес-идеи.
Процесс ETL состоит из объединения данных из этих разрозненных источников для создания уникального источника правды: хранилища данных.
Конвейеры ETL — это конвейеры данных, которые имеют очень специфическую роль: извлекать данные из исходной системы / базы данных, преобразовывать их и загружать в хранилище данных, которое является централизованной базой данных. Сами конвейеры данных представляют собой подмножество инфраструктуры данных, уровень, поддерживающий оркестровку данных, управление и их потребление в организации.

Зачем нам нужен ETL?
ETL может быть полезен для компаний во многих аспектах:
- ETL объединяет базы данных и различные формы данных в единое унифицированное представление. Это упрощает поиск данных и выполнения задач бизнес-анализа.
- ETL повышает продуктивность людей, работающих с данными, поскольку он кодифицирует и повторно использует процессы, перемещающие данные.
- ETL предлагает глубокий исторический контекст, который укрепляет доверие к данным.
- ETL позволяет сравнивать образцы данных между исходной и целевой системой.
ELT
При ELT-процессах в Data Lake или целевые системы загружаются любые данные и обрабатываются уже после загрузки. Такой подход дает больше гибкости и упрощает хранение при появлении новых форматов данных.

Идея состоит в том, чтобы извлечь данные из исходных систем и напрямую загрузить их в хранилище данных без каких-либо преобразований. Преобразование для конкретного бизнес-варианта использования не выполняется соединителями; он обрабатывается после загрузки данных в хранилище с помощью таких инструментов, как dbt.
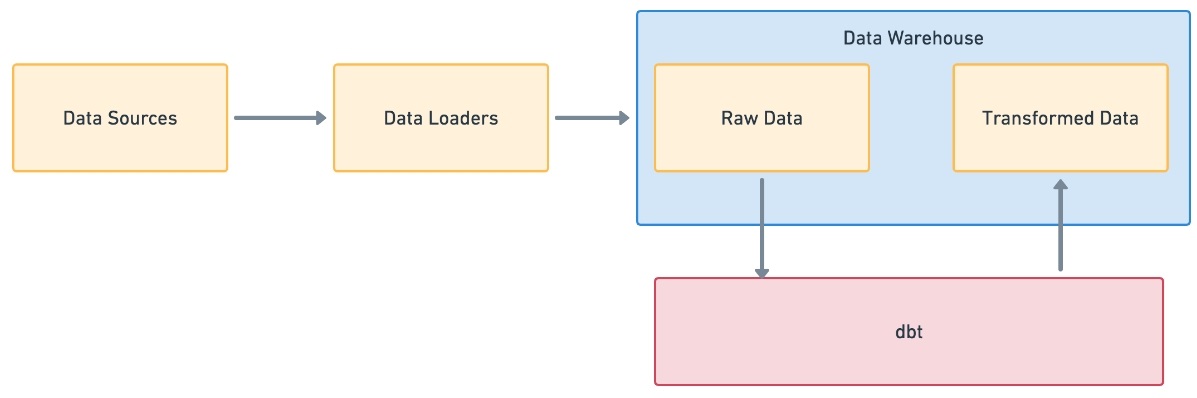
Batch ETL
ETL означает извлечение, преобразование и загрузку данных из различных источников, и этот процесс может выполняться двумя способами: либо пакетами, либо потоками.
В традиционных средах данных программа ETL извлекает пакеты данных из исходной системы, как правило, по расписанию, преобразовывает эти данные, а затем загружает их в репозиторий, например, в хранилище данных или базу данных. Это модель «пакетного ETL». Однако многие современные бизнес-среды не могут ждать часами или днями, пока приложения обрабатывают пакеты данных. Они должны реагировать на новые данные в реальном времени по мере их создания.
Streaming ETL
Streaming ETL (Потоковый ETL) — приложениям реального времени требуется потоковый ETL. Они должны реагировать на новые данные в режиме реального времени по мере их создания.
Обнаружение мошенничества, Интернет вещей, периферийные вычисления, потоковая аналитика и обработка платежей в реальном времени — вот примеры приложений, которые полагаются на потоковый ETL.
Потоковая передача ETL — это обработка и перемещение данных в реальном времени из одного места в другое.
Benchmark: Какой инструмент ETL / ELT подходит для вашей организации?
При выборе инструмента ETL сравниваются различные параметры и учитываются те или иные факторы. Вот несколько аспектов, на которые стоит обратить внимание:
- Встроенные интеграции: или, точнее, предлагают ли инструменты интеграцию, которая вам интересна. Самые продвинутые инструменты ETL предлагают готовые коннекторы для 150-200 наиболее часто используемых приложений. Если вам нужна интеграция с конкретным приложением, убедитесь, что вы выбрали инструмент, в котором она имеется и работает так, как вам это нужно. Вероятно, ваш инструмент ETL не будет интегрирован со всеми вашими приложениями / базами данных. В этом случае убедитесь, что вы выбрали инструмент, который интегрируется с другими инструментами ETL, у которых есть нужный вам коннектор, подключается к корзине S3, которая может выступать в качестве посредника между исходным источником данных и вашим инструментом ETL, или принимает данные из вручную закодированного pipeline.
- Техническое обслуживание: при поиске решения для обработки данных не забывайте, насколько критично техническое обслуживание для процесса. Если вам нужна штатная команда инженеров, чтобы конвейер ETL работал должным образом, возможно, вам стоит подумать о другом решении.
- Масштабируемость: выбранный вами инструмент будет отличаться в зависимости от того, являетесь ли вы корпоративным клиентом или небольшой / средней компанией. Если вы корпоративный заказчик, вам следует выбрать инструмент ETL, который можно легко масштабировать, с инфраструктурой высокой доступности и возможностью обрабатывать тысячи или десятки тысяч таблиц каждый день.
- Поддержка: независимо от того, какой инструмент вы используете, в конечном итоге вам понадобится помощь. Если вы не можете получить необходимый уровень помощи, ваша команда не сможет выполнять свои критически важные операции по обработке данных, и это плохо отразится на бизнесе компании.
Ниже приведен ландшафт инструментов ETL, который поможет выбрать решение, адаптированное к вашим потребностям.

Полный обзор инструментов ETL и ELT — Catalog of ETL and EL-T tools
ETL плюсы и минусы
Оба эти метода интеграции данных обладают уникальными преимуществами и недостатками. Ниже перечислены некоторые из заметных плюсов и минусов ETL.
Плюсы:
- Снижение накладных расходов: поскольку процесс ETL обеспечивает вывод, позволяющий извлекать и обрабатывать только релевантную информацию в хранилище данных, он помогает организациям снизить затраты на вычисления и администрирование.
- Минимальное потребление ресурсов: целенаправленный процесс загрузки метода интеграции данных ETL гарантирует, что сервер хранения будет содержать только необходимую информацию. Это обеспечивает снижение потребления ресурсов, что, в свою очередь, снижает административные расходы.
- Поддерживает несколько инструментов: инструменты ETL стали более зрелыми, что привело к более широкой и глубокой поддержке множества технологий. Это означает, что вы можете тратить меньше времени на совместную работу технологий.
- Стабильно и эффективно: ETL может ограничивать объем имеющихся у вас данных, но меньшее количество более структурированных данных приводит к более быстрым запросам.
- Соответствие стандартам безопасности данных. Еще одним заметным преимуществом более зрелых инструментов ETL является то, что в них добавлены функции для поддержки различных требований к безопасности и нормативных требований.
Минусы:
- Может занимать много времени: целенаправленный процесс преобразования данных иногда может быть препятствием. Если вам нужны какие-либо новые данные, которые вы не включили в последний проект, вам нужно подождать следующего выпуска, который часто составляет месяцы.
- Сравнительно более старая технология: эксперты говорят, что ETL устарел, поскольку он работает с традиционной инфраструктурой. Он не был разработан, чтобы быть облачным сервисом или поддерживать новые конвейеры данных, например, для потоковой аналитики.
ELT плюсы и минусы
Вот некоторые существенные преимущества и недостатки процесса ELT:
Плюсы:
- Большая маневренность: ELT предлагает повышенную маневренность. Вы можете напрямую загрузить все (необработанные) данные в хранилище. Поскольку все данные легко доступны, вы получаете возможность структурировать модель преобразования данных по мере необходимости.
- Большой пул ресурсов для преобразований: в большинстве моделей преобразования данных используется SQL — второй по популярности язык после JavaScript и наиболее широко используемый язык для данных. Это знает почти каждый аналитик данных, инженер и специалист по анализу данных. Это означает, что они могут выполнять большую часть работы самостоятельно, не полагаясь на отдельную группу интеграции данных.
- Повышенная гибкость: с ELT все ваши необработанные данные легко доступны в хранилище данных или озере данных. Это делает данные более доступными.
- Повышенная масштабируемость: с помощью ELT преобразования могут быть развернуты как SQL в современном облачном хранилище данных, которое имеет практически неограниченный масштаб.
Минусы:
- Сравнительно новый метод: хотя ELT доказал свою эффективность, это все еще новый метод по сравнению с ETL. В результате он часто сталкивается с ограниченной доступностью инструментов.
- Ограниченные возможности подключения: по сравнению с ETL у вас может быть не так много разъемов для устаревших систем. Со временем это становится менее серьезной проблемой, поскольку продукты ELT становятся более зрелыми, а некоторые устаревшие системы выводятся из эксплуатации. Кроме того, выполнение ETL для озера данных и ELT из озера данных в хранилище данных устраняет эту проблему.
- Требуется озеро данных: лучше всего подходит ELT, когда у вас есть легкий доступ к необработанным данным через озеро данных. Но это требует, чтобы компании внедрили озеро данных.
2021 Magic Quadrant for Data Integration Tools
Полный перечень инструментов из Gartner можно найти на странице Data Integration Tools.
Подпишитесь на Telegram канал Data Engineering: DevOps & DataOps based on Open-Source software, чтобы получать актуальную информацию в сфере Дата инжиниринга.
Modern Data Stack
Рейтинг Data Warehouse
https://www.g2.com/categories/data-warehouse
По ссылке полный перечень отзывов, а в низу страницы матрица:
Рейтинг Columnar Databases
https://www.g2.com/categories/columnar-databases

Колоночные базы данных (Columnar Databases)
ClickHouse
Yandex ClickHouse (https://clickhouse.com/docs/ru/) — высокопроизводительная колоночная СУБД, которая предназначена для онлайн обработки аналитических запросов. Система способна масштабироваться до десятков триллионов записей и петабайтов данных.
Основные термины Clickhouse:
- Шардирование — это стратегия горизонтального масштабирования кластера, при которой части одной базы данных ClickHouse размещаются на разных шардах. Шард состоит из одного или нескольких хостов-реплик. Запрос на запись или чтение в шард может быть отправлен на любую его реплику, выделенного мастера нет. При вставке данных они будут скопированы с реплики, на которой был выполен INSERT-запрос, на другие реплики шарда в асинхронном режиме.
- Репликация — синхронизация данных между хостами-репликами в рамках одной шарды (в рамках одного кластера).
- ClickHouse-кластер (или шард) — это один или несколько хостов базы данных, между которыми настраивается репликация.
Суть шардирования: взяли данные и разделили частями на разные шарды (на разные кластеры/серверы). Это нужно для хранения огромного числа данных. Заправшиваются данные с каждого шарда (запрос sql), затем результаты склеиваются и обрабатываются, после итоговый результат отдается юзеру.
Данные внутри одного шарда одинаковые — они реплицированы между отдельными серверами. Между шардами данные разные.
Репликация и шардирование настраивается на уровне таблиц. Т.е. можно сделать таблицы с разной конфигурацией (какие-то таблицы можно разнести на несколько шард, какие-то оставить на одной, аналогично настраивается реплицирование на уровне каждой отдельной таблицы).
Apache Druid
Apache Druid (https://github.com/apache/druid/) — это база данных в реальном времени для современных аналитических приложений. Поставляется под лицензией Apache v2.0. Написано на Java и переведено на лицензию Apache в феврале 2015 года.
Данные могут храниться в Druid через два типа источников данных: Batch/Пакетные (Native, Hadoop и т.д.) и Streaming/Потоковые (Kafka, Kinesis, Tranquility и т.д.).
В Apache Druid есть три типа столбцов:
- Timestamp — используется для partitioning и сортировки
- Dimension — измерение — поле, которое используется для объединения или фильтрации данных. Вот несколько примеров общих параметров: city, state, country, deviceId, campaignId
- Metric — необязательное поле, представляющее данные, агрегированные из других полей. Вот несколько примеров показателей: клики, показы
Запросы можно отправлять в Druid двумя разными способами без снижения производительности: Native Druid JSON или DruidSQL.
Apache Kudu
Apache Kudu — это диспетчер хранения по столбцам, разработанный для платформы Apache Hadoop. Kudu обладает общими техническими характеристиками приложений экосистемы Hadoop: он работает на стандартном оборудовании, масштабируется по горизонтали и поддерживает работу с высокой доступностью.
Kudu — это хранилище для быстрой аналитики быстрых данных, обеспечивающее сочетание быстрых вставок и обновлений наряду с эффективным сканированием по столбцам, что позволяет выполнять несколько аналитических рабочих нагрузок в реальном времени на одном уровне хранилища.
HDFS не позволяет модифицировать уже записанные данные, а Apache Kudo объединил преимущества HDFS системы, добавив возможность модификации данных.
Apache Kudu изначально разрабатывался как проект в Cloudera. На сегодняшний день большую часть вкладов внесли разработчики, работающие в Cloudera. Во время его выпуска в репозитории Cloudera были включены только удобные двоичные файлы, однако он принял процесс выпуска исходного кода Apache Software Foundation (ASF) после присоединения к инкубатору. Он специально разработан для случаев использования, требующих быстрой аналитики. Apache Kudu был разработан, чтобы использовать преимущества оборудования нового поколения и обработки в памяти. Это значительно снижает задержку запросов для Apache Impala и Apache Spark. Он распределяет данные с помощью механизма хранения по столбцам или с помощью горизонтального разделения, затем реплицирует каждый раздел с помощью Алгоритм Raft, обеспечивая тем самым низкое среднее время восстановления и низкие задержки.
Продвинутые методы работы с данными. Работа с потоковыми данными
Apache Spark
Apache Spark (https://spark.apache.org) — это многоязычный движок для крупномасштабной обработки данных (анализа данных и машинного обучения на одноузловых машинах или кластерах). Spark предлагает набор библиотек на трех языках (Java, Scala, Python) для своего единого вычислительного движка. Apache Spark интегрируется со множеством популярных фреймворков, помогая масштабировать их до тысяч машин (Data science and Machine learning, SQL analytics and BI, Storage and Infrastructure). Секрет скорости заключается в том, что Spark работает в оперативной памяти (RAM) и это делает обработку намного быстрее, чем на диске.
- Унифицированный — со Spark нет необходимости собирать приложение из нескольких API или систем. Spark предоставляет вам достаточно встроенных API-интерфейсов для выполнения работы.
- Вычислительный движок — Spark обрабатывает загрузку данных из различных файловых систем и выполняет на них вычисления, но не хранит данные на постоянной основе. Spark полностью работает в памяти, что обеспечивает беспрецедентную производительность и скорость.
- Библиотеки — Spark состоит из ряда библиотек, созданных для задач науки о данных. Spark включает библиотеки для SQL (Spark SQL), машинного обучения (MLlib), потоковой обработки (потоковая передача Spark и структурированная потоковая передача) и аналитики графиков (GraphX).
Устойчивые распределенные наборы данных (Spark RDD, DataFrames, DataSets) — являются строительными блоками Spark — все состоит из них. Даже высокоуровневые API Spark (DataFrames, Datasets) состоят из RDD под капотом. RDD — это неизменяемая, секционированная коллекция записей, что означает, что она может содержать значения, кортежи или другие объекты. Эти записи секционированы для обработки в распределенной системе, и что после того, как RDD был создан, изменить его невозможно. Это в основном резюмирует его аббревиатуру: они устойчивы благодаря своей неизменяемости и графам происхождения, они могут быть распределены благодаря своим разделам, и они являются наборами данных, потому что содержат данные.
Экосистема Apache Spark
Ниже приведены компоненты экосистемы Apache Spark:
- Spark Core: базовая функциональность Spark (планирование задач, управление памятью, восстановление после сбоев, взаимодействие с системами хранения).
- Spark SQL: пакет для работы со структурированными данными, запрашиваемыми через SQL, а также через HiveQL
- Spark Streaming: компонент, который позволяет обрабатывать потоки данных в реальном времени (например, файлы журналов, сообщения об обновлениях статуса).
- MLLib: это библиотека машинного обучения, подобная Mahout. Он построен на основе Spark и поддерживает множество алгоритмов машинного обучения.
- GraphX: для графиков и графических вычислений у Spark есть собственный механизм вычисления графиков, называемый GraphX. Он похож на другие широко используемые инструменты или базы данных для обработки графов, такие как Neo4j, Giraffe и многие другие базы данных с распределенными графами.
Spark Streaming
Spark считается очень быстрым механизмом для обработки больших объемов данных и оказывается в 100 раз быстрее, чем MapReduce. Это так, поскольку он использует распределенную обработку данных, посредством которой он разбивает данные на более мелкие части, так что фрагменты данных могут вычисляться параллельно на машинах, что экономит время. Кроме того, он использует обработку в памяти, а не на диске, что позволяет ускорить вычисления.
Spark Streaming (https://spark.apache.org/docs) — это расширение основного Spark API, которое обеспечивает масштабируемую, высокопроизводительную и отказоустойчивую потоковую обработку данных в реальном времени. Данные могут поступать выгружаться из многих источников, таких как Кафка, Kinesis, или TCP сокетов, и могут быть обработаны с использованием сложных алгоритмов, выраженных с функциями высокого уровня как map, reduce, join и window. Наконец, обработанные данные могут быть отправлены в файловые системы, базы данных и живые информационные панели.

Spark Streaming имеет следующую микропакетную архитектуру :
- обрабатывает поток как серию пакетов данных
- новые партии создаются через определенные промежутки времени
- размер временных интервалов называется пакетным интервалом
- интервал пакетной обработки обычно составляет от 500 мс до нескольких секунд.
Airflow
Airflow (https://airflow.apache.org или https://github.com/apache/airflow) — это инструмент для автоматизации и планирования задач и рабочих процессов (оркестратор для управления ETL/ELT).
Airflow — это платформа, которая позволяет создавать и запускать рабочие процессы . Рабочий процесс представлен как DAG (направленный ациклический график) и содержит отдельные части работы, называемые задачами , упорядоченные с учетом зависимостей и потоков данных.

Основные концепции инструмента Airflow:
- DAG (направленный ациклический граф) — это серия задач, которые вы хотите выполнять как часть рабочего процесса. Он может в себя извлечение данных с помощью SQL-запроса, выполнения некоторых вычислений с помощью Python и последующей загрузки преобразованных данных в новую таблицу. Либо запуск через API в сторонных системах последовательности действий, проверять статусы отдельных задач и реагировать на события в системе. Airflow позволяет также указать взаимосвязь между задачами, любые зависимости (например, данные, загруженные в таблицу перед запуском задачи) и порядок, в котором задачи должны выполняться. DAG написан на Python и сохраняется в виде .py файла.
- DAG Run — это объект, представляющий реализацию DAG во времени.
- Operator (Оператор) — представляет собой единственную, в идеале идемпотентную задачу. Операторы определяют, что на самом деле выполняется при запуске DAG.
Установка Airflow обычно состоит из следующих компонентов:
- Scheduler (Планировщик) — запускает запланированные рабочие процессы.
- Executor (Исполнитель) — обрабатывает выполнения задачи.
- Веб-сервер — удобный пользовательский интерфейс для проверки, запуска и отладки поведения DAGs и задач.
- Папка файлов DAG, читаемая планировщиком и исполнителем (и любыми рабочими, которые есть у исполнителя).
- База метаданных — используется планировщиком, исполнителем и веб-сервером для сохранения состояния.
Dbt
Dbt (https://www.getdbt.com и https://github.com/dbt-labs/dbt-core) — позволяет инженерам-аналитикам преобразовывать данные в своих хранилищах, просто записывая операторы выбора. dbt превращает эти операторы выбора в таблицы и представления.
dbt выполняет процессы T in ELT (извлечение, загрузка, преобразование) — он не извлекает и не загружает данные, но он очень хорош для преобразования данных, которые уже загружены в ваше хранилище.
Airbyte
Airbyte (https://airbyte.io) — платформа конвейера данных с открытым исходным кодом (альтернатива Fivetran или Stitchdata). Коннекторы Airbyte работают в контейнерах Docker, что означает, что все они работают независимо друг от друга.

Kafka
Kafka (https://kafka.apache.org) — это платформа распределенной потоковой передачи событий с открытым исходным кодом для высокопроизводительных конвейеров данных, потоковой аналитики, интеграции данных и критически важных приложений.
Apache Kafka зародился в LinkedIn и позже стал проектом Apache с открытым исходным кодом в 2011 году. Kafka написан на Scala и Java. Apache Kafka — это отказоустойчивая система обмена сообщениями.
В больших данных используется огромный объем данных. Что касается данных, у нас есть две основные проблемы: первая задача — как собрать большой объем данных, а вторая — проанализировать собранные данные. Чтобы преодолеть эти проблемы, вам понадобится система обмена сообщениями.
Kafka разработан для распределенных систем с высокой пропускной способностью. Kafka, как правило, очень хорошо работает как замена более традиционному брокеру сообщений. По сравнению с другими системами обмена сообщениями, Kafka имеет лучшую пропускную способность, встроенное разделение, репликацию и отказоустойчивость, что делает его хорошо подходящим для крупномасштабных приложений обработки сообщений.
Kafka Streams
Kafka Streams (https://kafka.apache.org/documentation/streams) —
Apache Nifi
Apache Nifi (https://nifi.apache.org) —
Apache Flink
Apache Flink (https://flink.apache.org) — is an open-source, unified stream-processing and batch-processing framework.
Scala
Scala (https://www.scala-lang.org) —
Apache Beam
Apache Beam (https://beam.apache.org) — это унифицированная модель с открытым исходным кодом и набор SDK для конкретных языков для определения и выполнения рабочих процессов обработки данных и приема данных.
Другие Open-source системы
- Alluxio is an open-source data orchestration layer that brings Data close to compute for big data and AI/ML workloads in the cloud.
- Delta Lake, an open-source storage layer, brings scalable ACID transactions to Spark and big data workloads.
- H2O, fully open-source, distributed in-memory machine learning platform with linear scalability.
- maiot-ZenML is the open-source MLOps framework for reproducible ML pipelines and production-ready Machine Learning.
- Marquez, Marquez is an open-source metadata service for the collection, aggregation, and Visualization of a data ecosystem’s metadata.
- MLFlow is an open-source platform developed by Databricks to help manage the complete machine learning lifecycle with enterprise reliability, security, and scale.
Data Catalog Open-Source
Зачем нужен каталог данных в компании?
Все инициативы по обновлению документации вручную обречены на провал. Инженеры по обработке данных предпочитают кодирование, а не документирование. Специалисты по анализу данных моделируют, а не документируют, а специалисты по анализу данных и визуализации данных играют с данными, а не документируют. Все предпочитают играть на детской площадке, чем документировать. Вот почему важно иметь правильный процесс, позволяющий поддерживать документацию данных с помощью автоматизированных процессов.
Основная цель каталога данных — демократизировать данные и дать сотрудникам компании возможность получать информацию, помогая исследовать и находить данные, а также доверять им.
Рассмотрим три популярные системы управления данными.
SKAN
SKAN (https://ckan.org/) — один из самых популярных инструментов с открытым исходным кодом для организации каталога данных (система управления данными). Он разработан с использованием Python, имеет в себе API. CKAN поставляется с богатой поисковой системой, которая позволит находить данные в вашем хранилище файлов.
Magda
Magda (https://github.com/magda-io/magda) — Объединенный каталог данных с открытым исходным кодом для всех ваших больших и малых данных. Magda начинала как небольшой проект по управлению данными, который оказался одной из самых популярных систем управления данными для хранения данных в стиле каталога.
Magda разработана специально на основе концепции федерации — предоставления единого окна для поиска среди всех данных, которые могут представлять интерес для пользователя, независимо от того, где данные хранятся или откуда они были получены. Система способна быстро сканировать внешние источники данных, отслеживать изменения, вносить автоматические улучшения и отправлять уведомления, когда происходят изменения.
Функции:
- Мощный и масштабируемый поиск на основе ElasticSearch
- Основан на Kubernetes для развертывания в облаке или локально на компьютере/сервере
- Расширения основаны на добавлении новых образов докеров в кластер и, следовательно, могут быть разработаны на любом языке
Magda построена на основе набора микросервисов, которые распространяются как контейнеры докеров. Это было сделано для обеспечения легкой расширяемости — Magda можно настроить, просто добавляя новые службы с использованием любой технологии в качестве образов докеров и интегрируя их с остальной системой через стабильные HTTP API. Использование Helm и Kubernetes для оркестровки означает, что конфигурация настроенного экземпляра Magda может храниться и отслеживаться как обычный текст, а экземпляры с идентичной конфигурацией могут быть быстро и легко воспроизведены.
Фактически, Magda также использует части CKAN под капотом.
DataHub
DataHub (https://datahubproject.io/ и https://github.com/linkedin/datahub) — Платформа метаданных для современного стека данных. Платформа расширяемых метаданных DataHub обеспечивает обнаружение данных, возможность наблюдения за данными и федеративное управление.
Изначально DataHub создавался в LinkedIn, а впоследствии был открыт в рамках лицензии Apache 2.0. DataHub следует архитектуре на основе push-уведомлений, что означает, что он создан для непрерывного изменения метаданных.
Модульная конструкция позволяет масштабировать ее по мере роста объема данных в любой организации. DataHub имеет встроенную интеграцию с вашими любимыми системами: Kafka, Airflow, MySQL, SQL Server, Postgres, LDAP, Snowflake, Hive, BigQuery и многими другими (см. https://datahubproject.io/docs/metadata-ingestion/).
Архитектура Datahub дает ряд интересных преимуществ.
- Во-первых, он допускает инкрементную загрузку (вместо очистки или создания моментальных снимков один раз за каждый период времени).
- Во-вторых, он позволяет обновлять данные почти в реальном времени, поскольку любое изменение, которое передается в Datahub, немедленно передается нижестоящим потребителям.
Инструменты инфраструктуры DevOps
- Puppet (https://puppet.com) — Управляет и автоматизирует инфраструктуру и сложные рабочие процессы.
- Ansible (https://www.ansible.com) — обеспечивает простую автоматизацию ИТ, которая завершает повторяющиеся задачи и освобождает команды DevOps для более стратегической работы.
- Terraform (https://www.terraform.io) — инфраструктура с открытым исходным кодом как программный инструмент, который обеспечивает согласованный рабочий процесс CLI для управления сотнями облачных сервисов.
Роль Docker и Kubernetes в Data Engineering
todo
Кликабельный LF AI & Data Interactive Landscape
https://landscape.lfai.foundation/
Roadmap to becoming a data engineer in 2021
Источник: https://github.com/datastacktv/data-engineer-roadmap