
Contents
- 1 Краткий обзор Apache Spark
- 1.1 Что такое Apache Spark? С какими языками программирования он может работать?
- 1.2 История создания Apache Spark
- 1.3 Apache Spark / PySpark Tutorial: Basics In 15 Mins
- 1.4 Плюсы Apache Spark
- 1.5 Минусы Apache Spark
- 1.6 Что такое Resilient Distributed Datasets (RDD) — Устойчивые распределенные наборы данных?
- 1.7 Что такое Apache PySpark?
- 1.8 Интеграция Apache Spark с ClickHouse
- 2 Архитектура Apache Spark & PySpark
- 3 Установка
- 4 Примеры Apache PySpark
- 5 Какие способы оптимизации обработки данных применимы и рекомендуются к использованию для PySpark?
- 6 FAQs по Apache Spark
- 6.1 Как управлять обработками данных в PySpark? Есть ли какой-то Scheduler встроенный для Spark? Интегрируется ли Apache Spark с Apache Airflow?
- 6.2 Когда следует выбирать Apache Spark, а когда достаточно использовать Apache Airflow со скриптами на Python?
- 6.3 Насколько Apache Spark подходит для batch etl?
- 6.4 Какие типы данных используются для обработки и хранения данных в Apache Spark?
- 6.5 Как Apache Spark хранит данные и что происходит в момент обращения к данным внутри
- 6.6 Можно ли для хранения больших наборов данных использовать ClickHouse для Apache Spark?
Краткий обзор Apache Spark
Что такое Apache Spark? С какими языками программирования он может работать?
Apache Spark — это многоязычный движок для выполнения обработки данных, обработки данных и машинного обучения на одноузловых компьютерах или кластерах в памяти RAM.
Spark предоставляет высокоуровневые API-интерфейсы (библиотеки) на Java, Scala, Python и R, а также оптимизированный движок, поддерживающий общие графы выполнения.
Движок Apache Spark работает на JVM (Java), поэтому для запуска заданий и разработки приложений на компьютере должен быть установлен JDK.
Он также поддерживает богатый набор инструментов более высокого уровня, включая:
- Spark SQL для обработки SQL и структурированных данных,
- API-интерфейс pandas в Spark для рабочих нагрузок pandas,
- MLlib для машинного обучения,
- GraphX для обработки графов
- и Structured Streaming для incremental computation и stream processing (потоковой обработки).
Spark основан на Hadoop MapReduce и расширяет модель MapReduce, позволяя эффективно использовать ее для большего количества типов вычислений, включая интерактивные запросы и потоковую обработку.
История создания Apache Spark
Spark — это один из подпроектов Hadoop, разработанный Matei Zaharia в 2009 году в AMPLab Калифорнийского университета в Беркли. Проект был переведен в Open Sourced в 2010 году под лицензией BSD. Он был передан в дар фонду программного обеспечения Apache в 2013 году, и теперь с февраля 2014 года Apache Spark стал проектом Apache высшего уровня.
GitHub Apache Spark — A unified analytics engine for large-scale data processing
На момент написания статьи у проекта Apache Spark в GitHub следующие показатели:
Apache Spark / PySpark Tutorial: Basics In 15 Mins
This video gives an introduction to the Spark ecosystem and world of Big Data, using the Python Programming Language and its PySpark API. We also discuss the idea of parallel and distributed computing, and computing on a cluster of machines.
Плюсы Apache Spark
- Высокая скорость и производительность обработки данных за счет распределительных вычислениий на множестве машин in-memory.
- Удобные для разработчиков инструменты. Spark предоставляет удобные для разработчиков инструменты, которые работают с помощью простого вызова метода. Apache Spark также обеспечивает привязку к языку для R, Python, Scala и Java.
- Широкий выбор библиотек (для алгоритмов машинного обучения и анализа графов, позволяет решать различные задачи аналитики — возможность обработки данных в памяти с малой задержкой)
- Структурированная потоковая передача Spark Streaming
- Поддержка Lazy Evaluation (Ленивые вычисления): Apache Spark поддерживает ленивые вычисления. Это означает, что Apache Spark будет ждать всей инструкции перед ее обработкой.
Минусы Apache Spark
- Apache Spark требует много оперативной памяти для обработки данных, что напрямую будет влиять на стоимость владения инструментом.
- Ручная оптимизация: При работе со Spark требуется ручная оптимизация заданий, а также наборов данных. Для создания разделов пользователи могут самостоятельно указать количество разделов Spark. Для этого в качестве параметра метода parallelize необходимо передать количество фиксируемых разделов. Чтобы получить правильные разделы и кеш, все эти процедуры разделов должны контролироваться вручную. Например, SparkUI в какой-то степени решает вопросы наблюдения, а Spark Metrics — измерения производительности, но попробуйте подключиться к исполняемому приложению отладчиком — вы не знаете ни хост, где оно работает, ни порт, который окажется свободным для подключения.
- Spark сложно настраивать и обслуживать. Это означает, что обеспечить максимальную производительность, чтобы она не прогибалась под тяжелыми рабочими нагрузками по обработке данных, сложно. Нужно учесть следующие параметры: выделение памяти, количество ядер, доступные для работы Spark, количество памяти на каждый исполнитель, и т.п.
- Нет системы управления файлами.
- Spark не полностью поддерживает обработку потока данных в реальном времени.
В потоковой передаче Spark данные делятся на небольшие пакеты на основе заданных интервалов времени. Таким образом, Apache Spark поддерживает time-based window criteria, но не на основе записей. - Плохое быстродействие UDF в PySpark (Slowness of PySpark UDFs): UDF на питоне приводит к тому, что происходит двойное преобразование данных между приложением и UDF. Рекомендация — не пишите на Python, пишите на Scala/Java.
Что такое Resilient Distributed Datasets (RDD) — Устойчивые распределенные наборы данных?
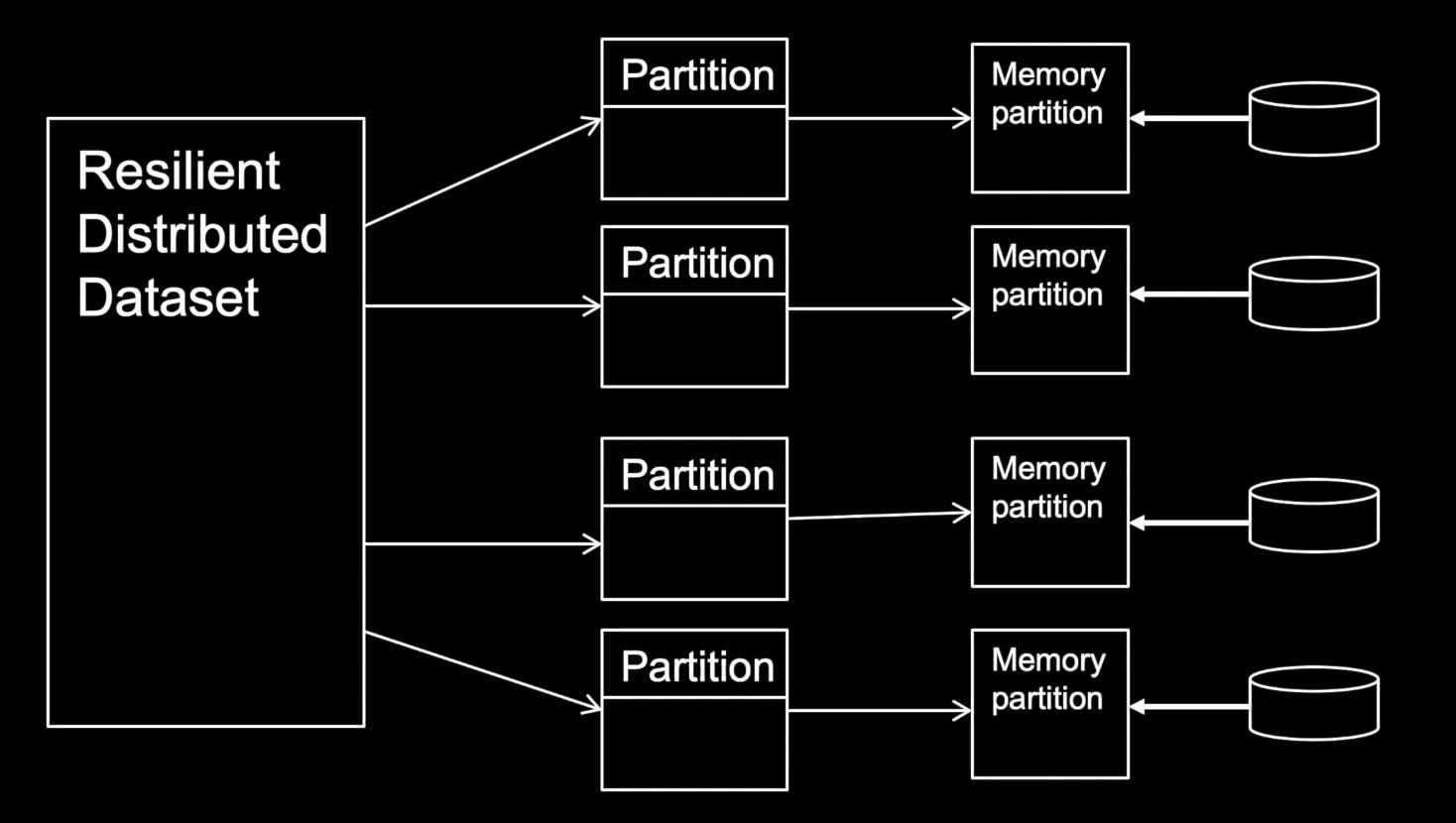
Resilient Distributed Datasets (RDD) — это фундаментальная структура данных Spark. Это неизменяемая распределенная коллекция объектов. Каждый набор данных в RDD разделен на логические разделы, которые могут быть вычислены на разных узлах кластера. RDD могут содержать объекты Python, Java, R или Scala любого типа, включая определяемые пользователем классы.
RDD — это отказоустойчивый набор элементов, с которыми можно работать параллельно.
Существует два способа создания RDD:
- распараллеливание существующей коллекции в программе-драйвере
- или ссылка на набор данных во внешней системе хранения, такой как общая файловая система, HDFS, HBase или любой источник данных, предлагающий входной формат Hadoop.
Spark использует концепцию RDD для достижения более быстрых и эффективных операций MapReduce.

Что такое Apache PySpark?
PySpark — это библиотека Spark, написанная на Python для запуска приложений Python с использованием возможностей Apache Spark. Используя PySpark, мы можем запускать приложения параллельно в распределенном кластере (несколько узлов). Другими словами, PySpark — это API Python для Apache Spark.

Spark в основном написан на Scala, а позже, благодаря адаптации к отрасли, это API PySpark, выпущенный для Python с использованием Py4J.
Py4J — это библиотека Java, которая интегрирована в PySpark и позволяет python динамически взаимодействовать с объектами JVM, поэтому для запуска PySpark вам также необходимо установить Java вместе с Python и Apache Spark.
Spark выполняет операции с миллиардами и триллионами данных в распределенных кластерах в 100 раз быстрее, чем традиционные приложения Python.
Кто использует PySpark?
PySpark очень хорошо используется в сообществе Data Science и Machine Learning, поскольку существует множество широко используемых библиотек для обработки данных, написанных на Python, включая NumPy, TensorFlow. Также используется из-за эффективной обработки больших наборов данных.
PySpark используется многими организациями, такими как Walmart, Trivago, Sanofi, Runtastic и многими другими.
Возможности PySpark
- Вычисления в памяти
- Распределенная обработка с использованием parallelize
- Может использоваться со многими менеджерами кластеров (Spark, Yarn, Mesos и т.д.)
- Fault-tolerant
- Immutable
- Lazy evaluation
- Cache & persistence
- Встроенная оптимизация при использовании DataFrames
- Поддерживает ANSI-SQL
Модули и пакеты PySpark
- PySpark RDD (pyspark.RDD)
- PySpark DataFrame and SQL (pyspark.sql)
- PySpark Streaming (pyspark.streaming)
- PySpark MLib (pyspark.ml, pyspark.mllib)
- PySpark GraphFrames (GraphFrames)
- PySpark Resource (pyspark.resource)
Сравнение Apache PySpark с Python Pandas
- Pandas выполняет операции на одной машине, тогда как PySpark работает на нескольких машинах.
- Pandas не поддерживает распределенную обработку, поэтому вам всегда нужно увеличивать ресурсы, когда вам нужна дополнительная мощность для поддержки ваших растущих данных.
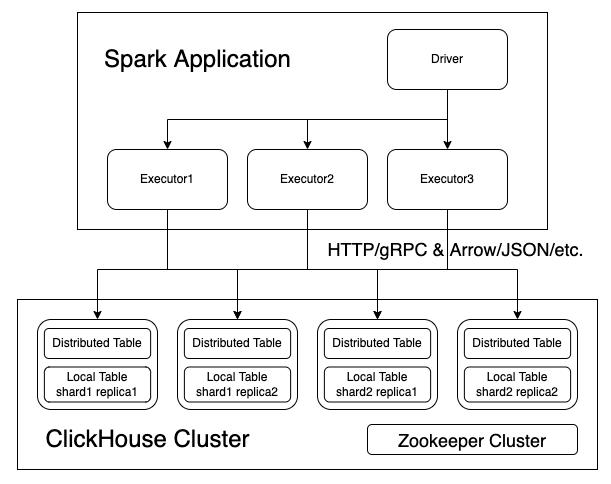
Интеграция Apache Spark с ClickHouse
- GitHub — Spark ClickHouse Connector build on DataSourceV2 API
- https://housepower.github.io/spark-clickhouse-connector/
Spark ClickHouse Connector — это высокопроизводительный коннектор, основанный на Spark DataSource V2.
Архитектура Apache Spark & PySpark
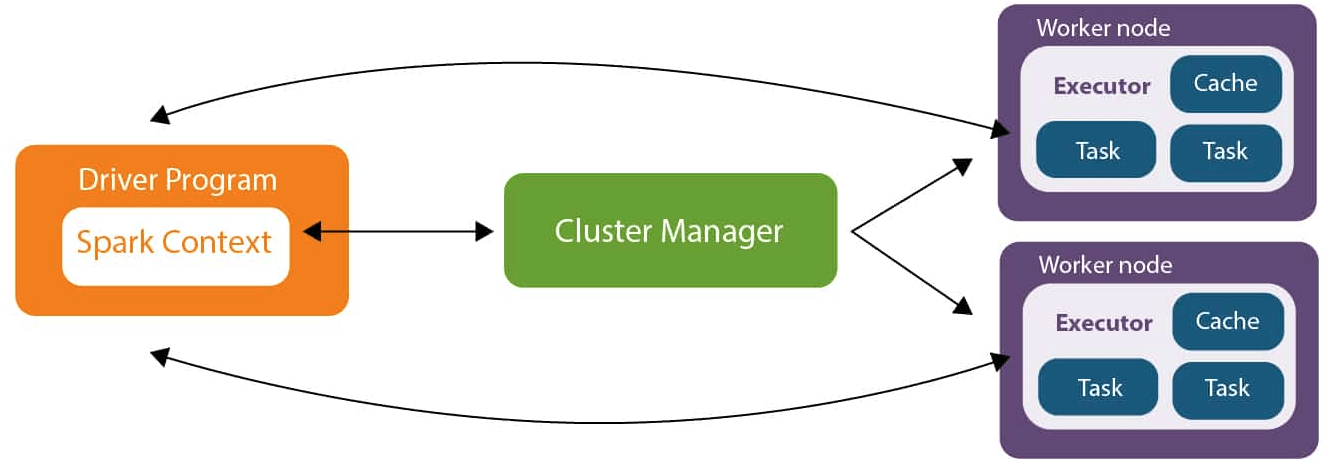
Как работает Apache Spark?
Apache Spark — это распределенная вычислительная система, которая используется для обработки больших объемов данных. Spark обеспечивает эффективную обработку данных, позволяя распределенно выполнить вычисления на кластере из множества узлов.
Система Apache Spark состоит из нескольких компонентов, включая:
-
Driver: Это основной процесс, который инициирует и контролирует выполнение задач на кластере.
-
Executor: Это процесс, который выполняет конкретную задачу на узле кластера.
-
Cluster Manager: Управляет кластером и выделяет ресурсы для выполнения задач.
Spark использует концепцию RDD (Resilient Distributed Datasets), что позволяет ему работать с данными, которые распределены по нескольким узлам кластера. RDD представляет собой неизменяемый набор элементов, который можно распределить и обрабатывать параллельно.
Основная идея Spark заключается в том, чтобы обрабатывать данные в памяти, минимизируя использование дискового пространства. Для этого Spark использует in-memory computing, что позволяет обрабатывать данные намного быстрее, чем при использовании традиционных технологий обработки данных.
Программирование в Spark осуществляется с использованием API на языке Scala, Java, Python или R. Spark также предоставляет удобный интерфейс для обработки SQL-запросов, а также библиотеки машинного обучения и графовых вычислений.
Самый распространенный способ запуска Spark на кластере — это использование Apache Hadoop YARN или Apache Mesos в качестве менеджера ресурсов. При этом Spark взаимодействует с HDFS (Hadoop Distributed File System) для доступа к данным. Также Spark может быть запущен в режиме standalone на локальной машине или на кластере без использования Hadoop.
Что такое RDD (Resilient Distributed Datasets) и как оно работает?
RDD (Resilient Distributed Datasets) — это распределенный набор данных в Apache Spark, который может храниться и обрабатываться на множестве узлов кластера. RDD является неизменяемым и отказоустойчивым, что означает, что если какой-либо узел кластера выходит из строя, данные могут быть восстановлены из копий, хранящихся на других узлах.
RDD может быть создан из данных, загруженных из внешних источников, например из файловой системы Hadoop или из базы данных. Кроме того, RDD может быть создан из других RDD, путем применения различных преобразований данных, таких как отображение, фильтрация, сортировка и т.д.
Преобразования RDD являются ленивыми, то есть они не выполняются немедленно, а только при вызове действий (actions) над RDD. Действия возвращают результаты вычислений, которые могут быть использованы в дальнейшей обработке данных или записаны во внешние хранилища данных.
Когда RDD создан, он автоматически распределяется по узлам кластера и может быть кэширован в памяти, чтобы обеспечить более быстрый доступ к данным в будущем. При необходимости данные могут быть дополнительно разбиты на части и параллельно обработаны на разных узлах кластера.
RDD предоставляет мощный инструментарий для распределенной обработки данных в Apache Spark, который позволяет анализировать большие объемы данных быстро и эффективно, благодаря параллельному выполнению вычислений на кластере.
Как работает Apache PySpark?
PySpark позволяет анализировать и обрабатывать данные, используя язык Python.
Работа PySpark начинается с создания объекта SparkContext, который связывает приложение Python с кластером Spark. После создания SparkContext можно создавать объекты RDD (Resilient Distributed Datasets), которые представляют собой распределенные коллекции объектов, над которыми можно выполнять различные операции.
PySpark также предоставляет множество функций для обработки данных, включая функции фильтрации, сортировки, агрегации, объединения и т.д. Все эти функции могут быть применены к RDD, что позволяет обрабатывать большие объемы данных быстро и эффективно.
Кроме того, PySpark поддерживает SQL-запросы через модуль Spark SQL, который позволяет использовать SQL-запросы для работы с данными. Модуль Spark SQL предоставляет объект DataFrame, который является распределенной таблицей данных, и который можно использовать для выполнения различных операций над данными.
PySpark также поддерживает машинное обучение и обработку потоков данных через модули MLlib и Spark Streaming соответственно. MLlib предоставляет множество алгоритмов машинного обучения, которые можно использовать для обучения моделей на больших объемах данных, а Spark Streaming позволяет обрабатывать потоковые данные в режиме реального времени.
В целом, PySpark предоставляет мощный инструментарий для обработки данных в распределенной среде, который позволяет использовать высокопроизводительные вычисления на кластере для обработки больших объемов данных в Python.
Как работает Spark SQL?
Spark SQL — это модуль Apache Spark, который позволяет выполнять обработку структурированных данных, используя язык SQL. Он предоставляет объект DataFrame, который является распределенной таблицей данных, схожей с таблицами в реляционных базах данных.
DataFrame в Spark SQL может быть создан из различных источников, включая CSV-файлы, JSON-файлы, базы данных и т.д. DataFrame также может быть создан из RDD, используя метод toDF(), который преобразует RDD в DataFrame.
DataFrame в Spark SQL поддерживает множество операций, включая фильтрацию, сортировку, агрегацию, группировку, объединение и т.д. Все эти операции могут быть выполнены с использованием языка SQL или с использованием функций API DataFrame.
DataFrame в Spark SQL является ленивым, так же как и RDD, и выполняет преобразования только при вызове действий (actions) над DataFrame. Это позволяет оптимизировать производительность обработки данных, так как Spark SQL может объединять несколько операций в один физический план выполнения, что снижает накладные расходы на выполнение операций.
DataFrame в Spark SQL также поддерживает машинное обучение, благодаря интеграции с модулем MLlib. Это позволяет выполнять обработку данных и обучение моделей машинного обучения в единой экосистеме Apache Spark.
В целом, DataFrame в Spark SQL предоставляет удобный и мощный способ работы с данными, который позволяет выполнять операции с высокой производительностью в распределенной среде.
Что такое SparkContext, как оно работает, где хранится? Как SparkContext взаимодействует с DataFrame и RDD?
SparkContext — это главный входной точкой для любой операции в Apache Spark, и это объект, который отвечает за связь между приложением и кластером Spark. Он предоставляет интерфейс для создания RDD и других структур данных, а также для настройки параметров приложения, таких как конфигурация и кэширование.
Когда приложение Spark запускается, SparkContext создается автоматически. Каждое приложение Spark имеет свой собственный SparkContext, который может быть доступен через переменную среды «sc». SparkContext управляет пулом ресурсов, включая выделение памяти, настройку задач, распределение задач по кластеру, отслеживание выполнения задач и другие операции.
SparkContext хранится в памяти кластера и управляет выполнением операций на RDD и DataFrame. Взаимодействие между SparkContext и DataFrame/RDD происходит через методы SparkContext, которые позволяют создавать, преобразовывать и агрегировать данные внутри RDD/DataFrame.
DataFrame взаимодействует с SparkContext через методы DataFrame, которые позволяют создавать, преобразовывать и агрегировать данные внутри DataFrame. SparkContext используется для выполнения операций на DataFrame, таких как фильтрация, сортировка, объединение, агрегирование и другие.
RDD взаимодействует с SparkContext через методы RDD, которые позволяют создавать, преобразовывать и агрегировать данные внутри RDD. SparkContext используется для выполнения операций на RDD, таких как фильтрация, сортировка, объединение, агрегирование и другие.
В целом, SparkContext является центральным элементом взаимодействия между приложением Spark и кластером, а DataFrame и RDD используют SparkContext для выполнения операций в памяти кластера.
Что такое SparkSession? Как с ней работать в PySpark?
SparkSession — это точка входа в PySpark для создания и настройки DataFrame и Dataset. Он заменяет более ранний SparkContext, который использовался в предыдущих версиях PySpark.
SparkSession можно создать с помощью метода builder:
from pyspark.sql import SparkSession
# Создаем объект SparkSession
spark = SparkSession.builder \
.appName("MyApp") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
Мы можем установить некоторые конфигурационные параметры в методе config(). Затем мы можем использовать spark для чтения и записи данных, выполнения запросов SQL и многого другого.
Например, мы можем использовать spark для чтения данных из CSV-файла:
df = spark.read.csv("path/to/file.csv", header=True, inferSchema=True)
Или мы можем использовать spark для записи данных в базу данных:
df.write \
.format("jdbc") \
.option("url", "jdbc:postgresql://localhost:5432/mydatabase") \
.option("dbtable", "mytable") \
.option("user", "myuser") \
.option("password", "mypassword") \
.mode("append") \
.save()
Обратите внимание, что SparkSession автоматически создает объекты SparkContext и SQLContext для вас, поэтому вам не нужно явно создавать эти объекты, как это было необходимо в более ранних версиях PySpark.
В чем разница между DataFrame в Spark SQL и RDD?
В Spark SQL объект DataFrame и объект RDD (Resilient Distributed Dataset) являются двумя разными концепциями для обработки данных.
Основные различия между DataFrame и RDD следующие:
-
Структура данных: DataFrame — это распределенная таблица данных с определенной структурой (набор столбцов и типов данных для каждого столбца), тогда как RDD — это распределенный набор неструктурированных данных (набор объектов).
-
Производительность: DataFrame имеет лучшую производительность по сравнению с RDD за счет оптимизированной обработки структурированных данных и использования оптимизированных движков выполнения запросов, таких как Catalyst и Tungsten. RDD могут иметь более низкую производительность, поскольку не имеют структуры данных и могут быть обработаны только с помощью более общих методов.
-
Удобство использования: DataFrame проще и удобнее использовать благодаря своей структурированной форме и языку SQL, который облегчает выполнение запросов и фильтрации данных. RDD более гибкий и может быть использован для обработки неструктурированных данных и выполнения более сложных операций.
-
Машинное обучение: DataFrame в Spark SQL интегрирован с модулем машинного обучения MLlib, что облегчает выполнение операций машинного обучения на структурированных данных. RDD не имеют встроенной поддержки машинного обучения и могут быть использованы только с использованием дополнительных библиотек и инструментов.
В целом, DataFrame в Spark SQL лучше подходит для работы со структурированными данными, в то время как RDD лучше подходят для обработки неструктурированных данных или выполнения более сложных операций.
Где хранится RDD в Apache Spark?
RDD (Resilient Distributed Dataset) в Apache Spark — это распределенный набор данных, который хранится в памяти кластера и может быть управляемым программно.
Фактические места хранения RDD зависят от того, как они создаются и используются в приложении Spark. В общем, RDD могут храниться в памяти кластера (RAM) или на диске (HDD или SSD).
Если RDD помещаются в память кластера, они могут храниться в кэше (cache) Spark и использоваться для быстрого доступа и повторного использования в различных операциях. Кроме того, RDD могут храниться на диске, если они не помещаются в память кластера.
Распределенное хранение данных RDD также может быть управляемым, что означает, что можно управлять тем, как часто и где RDD должны сохраняться на диске, как они будут кэшироваться и какие данные должны быть выгружены из памяти.
Кроме того, Spark поддерживает несколько видов хранения данных, таких как HDFS (Hadoop Distributed File System), S3 (Amazon Simple Storage Service) и другие, что позволяет сохранять RDD на диске в распределенном хранилище данных и загружать их при необходимости.
В целом, места хранения RDD зависят от различных факторов, включая размер и тип данных, доступную память и доступ к кластеру. Однако, Spark обеспечивает гибкость в управлении хранением RDD, что позволяет оптимизировать производительность приложений Spark в зависимости от потребностей приложения.
При перезагрузке сервера RDD как восстанавливается в памяти?
При перезагрузке сервера RDD (Resilient Distributed Dataset) восстанавливается в памяти с использованием механизма кэширования Spark.
Spark обеспечивает механизмы управления памятью кластера и кэширования данных, которые позволяют сохранять RDD в памяти кластера между запросами и перезапусками. Кэширование Spark позволяет сохранять RDD в памяти кластера на долгое время, пока они не будут удалены вручную или автоматически для освобождения памяти.
При создании RDD, вы можете указать, что RDD должен быть кэширован с помощью метода persist() или cache(). Когда RDD кэшируется, он сохраняется в памяти кластера и доступен для повторного использования в различных операциях, включая операции по работе с данными и вычислениями.
Если происходит перезагрузка сервера, то Spark запустит автоматический процесс восстановления кэшированных RDD из журнала транзакций, который содержит информацию о состоянии RDD. Spark использует эту информацию для восстановления RDD в памяти кластера, после чего они становятся доступными для повторного использования в приложении.
Важно отметить, что восстановление RDD может занять некоторое время, в зависимости от размера и сложности RDD. Поэтому рекомендуется управлять кэшированием RDD и выполнять его наиболее важные части, чтобы минимизировать время восстановления после перезагрузки сервера.
DataFrame в Spark SQL
DataFrame в Spark SQL — это распределенная таблица данных, которая может быть хранимой в различных местах в памяти кластера, в зависимости от того, как она создана и используется.
При создании DataFrame в Spark SQL, вы можете загрузить данные из различных источников, таких как Hadoop Distributed File System (HDFS), Amazon S3, Apache Cassandra, Apache HBase, Apache Kafka и другие. Данные могут быть хранимы в различных форматах, таких как CSV, JSON, Parquet, Avro и другие.
Когда данные загружаются в DataFrame, они могут быть кэшированы в памяти кластера или на диске, в зависимости от настроек кэширования. DataFrame может быть создан из RDD, в таком случае, DataFrame может быть храним в памяти кластера также как и RDD.
DataFrame в Spark SQL хранится в памяти кластера в форме распределенных блоков данных, называемых партициями (partitions). Каждая партиция содержит некоторое количество строк таблицы, которые могут быть обработаны параллельно в рамках кластера. Число партиций может быть настроено в зависимости от требований приложения и доступных ресурсов.
По умолчанию, Spark SQL сохраняет DataFrame в памяти кластера, но это может быть изменено с помощью настроек кэширования. DataFrame может быть кэширован в памяти кластера, на диске или в обоих местах одновременно. Кроме того, Spark SQL поддерживает различные стратегии кэширования, которые могут быть выбраны в зависимости от типа и размера DataFrame.
В целом, DataFrame в Spark SQL может быть хранимым в памяти кластера, на диске или в обоих местах одновременно. DataFrame хранится в форме распределенных блоков данных, называемых партициями, которые могут быть обработаны параллельно в рамках кластера.
Установка
Установка Apache PySpark на Ubuntu
todo
Установка Apache PySpark с помощью Docker Compose
todo
Примеры Apache PySpark
Пример агрегации данных в Apache PySpark
Для выполнения агрегации данных в PySpark можно использовать следующий скрипт:
from pyspark.sql import SparkSession
# Создаем объект SparkSession
spark = SparkSession.builder.appName("Aggregation Script").getOrCreate()
# Читаем данные из исходной таблицы
df = spark.read.format("csv").option("header", "true").load("path/to/input/file.csv")
# Преобразуем столбец даты в формат месяца
df = df.withColumn("month", date_format(col("date"), "yyyy-MM"))
# Группируем данные по категории товара и месяцу и вычисляем сумму и количество продаж
agg_df = df.groupBy("category", "month").agg(sum("sales_amount").alias("total_sales"), count("sales_amount").alias("sales_count"))
# Записываем агрегированные данные в ClickHouse
agg_df.write \
.format("jdbc") \
.option("driver", "ru.yandex.clickhouse.ClickHouseDriver") \
.option("url", "jdbc:clickhouse://clickhouse-server:8123/database_name") \
.option("dbtable", "aggregated_data") \
.option("user", "username") \
.option("password", "password") \
.mode("append") \
.save()
В этом скрипте мы используем функции withColumn и date_format для преобразования столбца даты в формат месяца. Затем мы группируем данные по категории товара и месяцу с помощью метода groupBy, а затем вычисляем сумму и количество продаж с помощью функций sum и count. Наконец, мы записываем агрегированные данные в ClickHouse с помощью метода write и указываем драйвер и параметры подключения к ClickHouse в качестве опций. Важно заметить, что мы используем режим «append», чтобы добавить данные в таблицу каждый час, вместо перезаписи таблицы каждый раз. Это помогает сохранить целостность данных и ускорить процесс записи данных.
Пример создания pipeline на Apache PySpark
Apache PySpark предоставляет возможность создания pipeline для обработки данных в пакетном режиме. Pipeline может включать в себя различные этапы обработки данных, такие как чтение данных, преобразование данных и запись данных.
Ниже приведен пример создания pipeline на Apache PySpark:
from pyspark.sql import SparkSession
from pyspark.ml import Pipeline
from pyspark.ml.feature import VectorAssembler, StandardScaler
from pyspark.ml.classification import LogisticRegression
# Создаем SparkSession
spark = SparkSession.builder.appName("Example Pipeline").getOrCreate()
# Загрузка данных из CSV файла
data = spark.read.format("csv").option("header", "true").load("data.csv")
# Выбор признаков для модели и объединение их в вектор
assembler = VectorAssembler(inputCols=["feature1", "feature2", "feature3"], outputCol="features")
# Масштабирование признаков
scaler = StandardScaler(inputCol="features", outputCol="scaledFeatures")
# Создание модели логистической регрессии
lr = LogisticRegression(featuresCol="scaledFeatures", labelCol="label")
# Создание pipeline из этапов обработки данных
pipeline = Pipeline(stages=[assembler, scaler, lr])
# Обучение модели на данных
model = pipeline.fit(data)
# Использование модели для предсказания на новых данных
predictions = model.transform(data)
# Отображение результата предсказания
predictions.show()
В этом примере мы загружаем данные из CSV файла, выбираем признаки для модели и объединяем их в вектор, масштабируем признаки, создаем модель логистической регрессии и создаем pipeline из этапов обработки данных. Затем мы обучаем модель на данных, используя pipeline, и используем модель для предсказания на новых данных.
Какие способы оптимизации обработки данных применимы и рекомендуются к использованию для PySpark?
PySpark предоставляет множество инструментов для оптимизации обработки данных, которые можно использовать для ускорения работы вашего приложения. Ниже перечислены некоторые из рекомендуемых способов оптимизации:
-
Используйте кластер с высокопроизводительными узлами. PySpark распределенная обработка данных, и чем больше у вас вычислительных ресурсов, тем быстрее будет работать ваше приложение.
-
Используйте форматы файлов, которые эффективно работают с PySpark, такие как Parquet и ORC. Эти форматы файлов обладают хорошей сжатием и структурированными данными, что ускоряет обработку данных.
-
Используйте кэширование и персистенцию для сохранения промежуточных результатов в памяти, чтобы ускорить последующие запросы. Это позволяет избежать повторной обработки данных каждый раз, когда они нужны.
-
Используйте методы, такие как
select,filterиgroupBy, для минимизации объема данных, которые передаются в обработку. Это позволяет уменьшить объем данных, которые необходимо передавать между узлами кластера. -
Используйте методы оптимизации запросов, такие как
explainиset, чтобы определить, как запросы будут выполняться и какие настройки нужно установить для улучшения производительности. -
Используйте параллельную обработку и распределенную обработку данных, когда это возможно. Например, можно использовать метод
mapPartitionsдля параллельной обработки каждой части данных. -
Используйте методы оптимизации работы с памятью, такие как
broadcast, чтобы снизить нагрузку на сеть и ускорить передачу данных между узлами. -
Используйте инструменты мониторинга, такие как Spark UI и логи, для определения узких мест в вашей обработке данных и оптимизации производительности.
Это только некоторые из способов оптимизации, которые можно использовать для ускорения работы вашего приложения на PySpark. Как правило, оптимизация зависит от конкретных характеристик вашего приложения и вашей инфраструктуры, поэтому рекомендуется проводить тестирование и эксперименты, чтобы определить наилучший набор методов оптимизации для вашего случая.
FAQs по Apache Spark
Как управлять обработками данных в PySpark? Есть ли какой-то Scheduler встроенный для Spark? Интегрируется ли Apache Spark с Apache Airflow?
Управление обработками данных в PySpark осуществляется с помощью управления задачами (job management) и мониторинга выполнения задач (task monitoring). Управление задачами в PySpark осуществляется с помощью объекта SparkContext, который запускает и распределяет задачи между узлами кластера.
Для управления и планирования выполнения задач в Spark можно использовать встроенный планировщик задач (Task Scheduler), который автоматически распределяет задачи между узлами кластера. В Spark можно выбрать различные планировщики задач, такие как FIFO, Fair и другие, в зависимости от конкретных потребностей приложения.
Apache Spark также интегрируется с Apache Airflow, который является платформой управления рабочими процессами и позволяет автоматизировать и планировать выполнение PySpark задач. Apache Airflow позволяет создавать DAG (Directed Acyclic Graph) задач, которые определяют зависимости между задачами и планируют их выполнение в определенном порядке. Для выполнения PySpark задач в Apache Airflow используется оператор SparkSubmitOperator, который запускает задачи в Spark кластере через командную строку.
Когда следует выбирать Apache Spark, а когда достаточно использовать Apache Airflow со скриптами на Python?
Apache Spark и Apache Airflow являются разными инструментами и предназначены для решения различных задач. Apache Spark предназначен для обработки больших объемов данных в режиме реального времени и масштабируется для работы с кластером серверов. Spark может использоваться для различных задач, включая машинное обучение, обработку потоковых данных, аналитику больших данных и другие.
Apache Airflow, в свою очередь, является платформой для управления рабочими процессами (workflow management platform) и предназначен для автоматизации и оркестрации задач внутри комплексных рабочих процессов. Airflow позволяет планировать выполнение задач в определенном порядке, управлять зависимостями между задачами, запускать задачи в определенное время и т.д.
Если задача связана с обработкой больших объемов данных в режиме реального времени, то Apache Spark является лучшим выбором. Если же задача связана с автоматизацией и оркестрацией сложных рабочих процессов, в которых есть зависимости между задачами, то Apache Airflow может быть более подходящим инструментом.
Кроме того, Apache Spark и Apache Airflow могут использоваться совместно для выполнения сложных рабочих процессов, где Apache Spark может использоваться для обработки данных, а Apache Airflow — для автоматизации запуска задач и управления процессами.
Насколько Apache Spark подходит для batch etl?
Apache Spark подходит очень хорошо для batch ETL. Он был разработан с учетом обработки больших объемов данных и позволяет эффективно обрабатывать данные как в пакетном режиме (batch), так и в потоковом режиме (streaming).
При обработке данных в batch режиме Apache Spark позволяет работать с данными из различных источников (например, файловой системы, баз данных, кластеров Hadoop и т.д.), выполнять операции трансформации и агрегации данных, а также сохранять результаты в различных форматах.
Важным преимуществом Apache Spark является его способность к распараллеливанию обработки данных на кластере, что позволяет значительно ускорить обработку данных в сравнении с традиционными инструментами.
Таким образом, Apache Spark является отличным выбором для обработки данных в batch режиме.
Какие типы данных используются для обработки и хранения данных в Apache Spark?
Apache Spark поддерживает множество типов данных для обработки и хранения данных. Некоторые из наиболее распространенных типов данных, используемых в Apache Spark, перечислены ниже:
-
Числовые типы данных: целые числа (
IntegerType), числа с плавающей точкой (FloatTypeиDoubleType), длинные целые числа (LongType), короткие целые числа (ShortType) и т.д. -
Типы данных для работы со строками: строки (
StringType), бинарные данные (BinaryType) и т.д. -
Логические типы данных: логические значения (
BooleanType). -
Дата/временные типы данных:
DateType,TimestampTypeи т.д. -
Сложные типы данных: массивы (
ArrayType), структуры (StructType), множества (MapType) и т.д. -
Нестандартные типы данных: например, типы данных для работы с геопространственными данными (
GeometryType), типы данных для работы с JSON (JsonType) и т.д.
Кроме того, Spark позволяет определять пользовательские типы данных (UserDefinedType), что позволяет разработчикам создавать собственные типы данных для специфических задач.
Как Apache Spark хранит данные и что происходит в момент обращения к данным внутри
Apache Spark использует распределенную файловую систему Hadoop (HDFS) для хранения больших наборов данных. HDFS разделяет данные на блоки и распределяет их по нескольким узлам кластера. Каждый блок данных имеет дубликаты, что позволяет обеспечить отказоустойчивость и защиту от потери данных.
Когда Spark обращается к данным, он сначала читает блоки данных из HDFS на узлы кластера. Затем Spark выполняет операции обработки данных на этих узлах, распределяя вычислительные задачи между узлами кластера. Каждый узел обрабатывает данные локально, минимизируя задержки из-за сетевых переходов.
Кроме того, Spark использует механизм кэширования данных, чтобы ускорить доступ к часто используемым данным. Spark сохраняет промежуточные результаты обработки данных в памяти кластера и повторно использует их при необходимости. Это позволяет избежать повторной загрузки данных из HDFS, что может существенно ускорить выполнение вычислительных задач.
При обращении к данным внутри Spark, данные сначала загружаются в память кластера, если они еще не находятся там. Затем Spark использует распределенные операции обработки данных, такие как фильтрация, сортировка и группировка, чтобы извлечь нужную информацию. Результаты операций обработки данных могут быть сохранены в HDFS или переданы другой части вычислительной системы для дальнейшей обработки.
Можно ли для хранения больших наборов данных использовать ClickHouse для Apache Spark?
Да, возможно использовать ClickHouse вместе с Apache Spark для хранения и обработки больших наборов данных. ClickHouse — это высокопроизводительная колоночная СУБД, которая может хранить и обрабатывать большие объемы данных. ClickHouse поддерживает различные форматы данных, такие как CSV, TSV, JSON, Avro и Parquet, которые также используются в Apache Spark.
Существует два основных подхода к интеграции ClickHouse с Apache Spark:
-
Использование драйвера JDBC: Spark поддерживает соединение с ClickHouse через драйвер JDBC. Это позволяет использовать SQL для чтения и записи данных в ClickHouse из Spark. Этот подход может быть полезен, когда требуется выполнить простые SQL-запросы к ClickHouse из Spark.
-
Использование Spark-ClickHouse Connector: существует набор пакетов и библиотек, которые облегчают интеграцию ClickHouse с Apache Spark. Spark-ClickHouse Connector позволяет использовать Spark для обработки и анализа данных в ClickHouse. Он поддерживает чтение и запись данных в ClickHouse из Spark и предоставляет оптимизированные API для работы с ClickHouse.
Оба подхода могут быть полезны в зависимости от задачи и требований к производительности и скорости выполнения.
Что быстрее работает драйвер JDBC для ClickHouse или Spark-ClickHouse Connector?
Это зависит от многих факторов, таких как размер данных, типы операций, конфигурация кластера и т.д. В целом, Spark-ClickHouse Connector обычно работает быстрее, чем драйвер JDBC для ClickHouse, потому что он использует специальные оптимизации для улучшения производительности при работе с ClickHouse.
Spark-ClickHouse Connector позволяет загрузить данные из ClickHouse в Spark кэш, что позволяет Spark выполнять операции на этих данных в памяти, что может значительно ускорить их обработку. Кроме того, Spark-ClickHouse Connector позволяет использовать функции ClickHouse для фильтрации данных и других операций в Spark, что также может ускорить их выполнение.
Однако, драйвер JDBC может быть более удобным решением для небольших задач или когда требуется просто выполнить несколько простых SQL-запросов к ClickHouse из Spark.
В любом случае, при интеграции ClickHouse с Apache Spark необходимо провести тестирование производительности и выбрать оптимальный вариант для конкретной задачи и условий эксплуатации.
Кто создал и поддерживает Spark-ClickHouse Connector?
Spark-ClickHouse Connector был разработан командой Yandex Data Factory, частью компании Yandex, которая занимается разработкой решений в области машинного обучения, анализа данных и искусственного интеллекта. Коннектор распространяется под лицензией Apache License 2.0, что означает, что он является открытым исходным кодом и может быть свободно использован, модифицирован и распространен.
Yandex Data Factory продолжает поддерживать и развивать Spark-ClickHouse Connector, обеспечивая его совместимость с новыми версиями Spark и ClickHouse, а также исправляя ошибки и улучшая производительность. Кроме того, сообщество разработчиков и пользователей Spark-ClickHouse Connector также вносит свой вклад в развитие и поддержку коннектора, создавая дополнительные функции и расширения.

