
Contents
- 1 Что такое Apache Superset?
- 2 Обзор нововведений Apache Superset в релизах 1.3, 1.4, 1.5
- 3 Установка Apache Superset на docker с помощью Docker Compose
- 3.1 Интро для упрямых
- 3.2 Краткая инструкция по установке Apache Superset 1.5 через docker-compose
- 3.3 Какие файлы необходимо изучить для работы с Superset через Docker и Docker-Compose?
- 4 Архитектура Apache Superset
- 5 Настройка Superset Config файла
- 6 Список доступных визуализаций в версии Apache Superset 1.5.0
- 7 Примеры дашбордов Apache Superset
- 8 Сборник примеров архитектур BI-систем на базе Apache Superset
- 9 Подборка материалов по Apache Superset для дальнейшего развития навыков разработки
Что такое Apache Superset?
Apache Superset — Open-Source инструмент для визуализации данных, входящий в портфолио продуктов Apache Foundation. Зародился Apache Superset в компании Airbnb, там же где появился Airflow. Эта система является очень популярной и хорошо развивается за счет привлечения новых контрибьютеров.

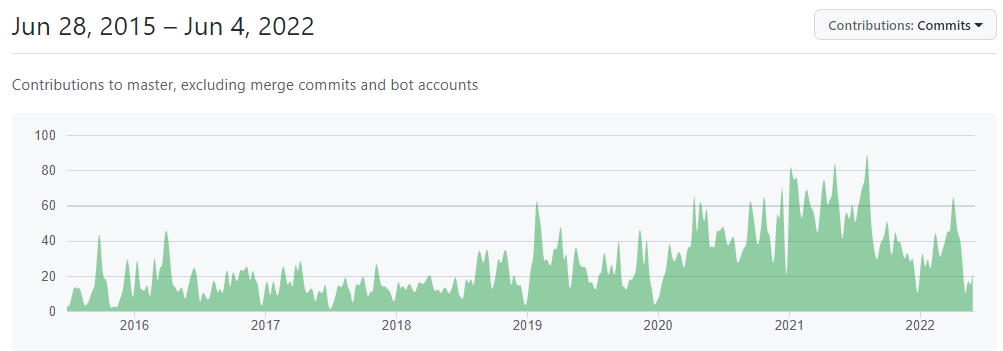
Количество комитов авторов на Github неуклонно растет:
Канал в телеграме Apache Superset BI:

В настоящее время Superset широко используется во многих компаниях по всему миру (полный перечень компаний, использующих Apache Superset). Например, Superset запускается в производственной среде Airbnb внутри Kubernetes и ежедневно обслуживает более 600 активных пользователей, просматривающих более 100 000 диаграмм в день.
Также Apache Superset приобретает популярность в России, в том числе после ухода западных вендоров.
Ознакомиться с полным функционалом и настройками Superset можно в официальной документации https://superset.apache.org/docs/intro.
Обзор главных фич/основного функционала Apache Superset?
- Интуитивно понятный интерфейс для визуализации наборов данных и создания интерактивных информационных панелей;
- Много готовых коннекторов (возможность подключения к более чем 40 базам данных, с минимальными донастройками);
- Интеграция с основными механизмами аутентификации (база данных, OpenID, LDAP, OAuth/SSO, REMOTE_USER и т.д.);
- Большой набор типов визуализации данных (40+ отличных вариантов визуализаций);
- Возможность добавления пользовательских плагинов визуализации;
- Бесшовное асинхронное кэширование и запросы в памяти (из docker-compose поднимается настроенный Redis, надо только кеширование включить в config);
- Расширяемая модель безопасности, которая позволяет настраивать очень сложные правила, определяющие, кто может получить доступ к каким функциям продукта и наборам данных;
- Rest API (на основе спецификации OpenAPI) для программной настройки Superset — возможность взаимодействия с артефактами Superset;
- Облачная архитектура, разработанная с нуля для масштабирования;
- Есть функционал Alerting;
- Есть функционал отправки отчетности на email;
- Superset поставляется с SQL Lab — современной многофункциональной интегрированной средой разработки SQL IDE (для подготовки данных к визуализации);
- SQL Lab and Explore поддерживает шаблоны Jinja в запросах (код Python можно встраивать в виртуальные наборы данных и в пользовательский SQL в фильтрах и элементах управления метриками);
- Асинхронные запросы через Celery (распределённая очередь заданий, реализованная на языке Python);
- К каждому отдельному дашборду можно применить кастомные стили CSS;
- Апач Суперсет умеет делать снимки дашборда, причем не видимой части, а всего дашборда целиком. Если у Вас длинный дашборд (что случается периодически), то скачается весь лист с учетом скроллинга вниз;
- в Superset есть Markdown-formatted text объект визуализации, который позволяет делать очень хорошие заметки к дашборду.
Основные плюсы и минусы Apache Superset
Плюсы (преимущества) Apache Superset
- Довольно зрелая система с хорошим набором фич;
- Т.к. Superset развивается под крылом Apache, то переход продукта из бесплатного в разряд платного маловероятен. На текущий момент весь функционал Superset полностью бесплатен и доступен из коробки;
- Открытый исходный код (Вы можете добавить любую фичу, которая для бизнеса очень необходима и для разработки которой выделен бюджет — это может быть как новая визуализация, так и элемент интерфейса/меню/интеграции с любой вашей внутренней системой);
- BI можно развернуть на внутренних серверах компании и не опасаться за безопасность данных (по сравнению с облачными решениями);
- Богатый набор визуализаций данных (40+);
- Большое количество тестовых демо дашбордов, на основе которых можно быстро понять возможности визуализации инструмента;
- Можно встраивать визуализации из Superset в ваши внутренние приложения, системы;
- Бесплатная версия функционала ничем не ограничена;
- Есть настройка доступа как на уровне датасета и всех связанных дашбордов, так и на уровне данных (отдельных записей в БД);
- No-Code подход для создания визулизаций, можно пустить пользователей для self-service (как на основе предподготовленных datasets, либо более продвинутый вариант с помощью sql);
- Есть русскоязычный чат в Telegram (developer community);
- А также канал Telegram с основными новостями по Apache Superset;
Минусы (недостатки) Apache Superset
Возможно часть минусов будут закрыты в новых релизах выпуском новой функциональности. Следите обязательно за новостями!
- Основным минусом, на мой взгляд, является необходимость подготовки dataset, который является прямой таблицей. Т.е. создать модель данных с несколькими таблицами, соединенных по ключу (как в Qlik Sense или Power BI), особенно если разные сущности имеют связь 1 ко многим — очень сложно. Либо придется делать дашборд из нескольких датасетов, но тогда усложняется работа с запросами и потребуется параметризация, чтобы фильтр срабатывал для двух датасетов одновременно.
- Очень непросто создавать Custom Plugins (кастомные визуализации). Если развертывание и конфигурирование Superset можно оценить по сложности как 4 баллов из 10 для новичка. То создание плагина/деплой выльются в полные 10 баллов. Есть ряд свежих инструкций по созданию кастом плагинов для Superset, например на моем сайте — Build & Deploy Custom Superset Viz Plugin. Основные скилы, которые нужны для создания Custom Plugin и его деплоя:
- docker & Dockerfile & docker build
- docker-compose
- Linux (Ubuntu)
- npm, yarn, build, npm registry
- React, javascript, typescript
- json и обработка json структур с помощью typescript/javasript
- git
- Условная бесплатность Superset: он требует довольно сильных специалистов как по части подготовки данных, так и по части его администрирования. Это может быть 1 человек или команда, в зависимости от потребности бизнеса в аналитике.
- Для Apache Superset необходим сторонний движок БД, идеально ClickHouse или другие колоночные базы данных, которые могут на своей стороне быстро обрабатывать запросы.
- Также необходим сторонний ETL инструмент для подготовки данных. В целом сойдет и Python, но тогда нужна система оркестрации всем ETL.
- Если Вы нашли баг в Apache Superset — теперь это ваша головная боль, поддержка исключительно на английском языке (хотя ввиду ситуации в России скоро должны появиться и на местном рынке услуги по Apache Superset).
- Сложность бекапирования и восстановления ввиду контейнеризации. Если работать без контейнеров, то придется возиться с зависимостями и инсталляцией на чистую OS.
- Сообщество разработчиков находится в Slack, что в текущих условиях может затруднять доступ к получению быстрой помощи.
- Немного непрозрачная модель настройки ролей доступа (нужно потратить какое-то время на освоение какая настройка за что отвечает).
- Есть небольшая доля вероятности, что из-за санкций придется Apache Superset качать через VPN сервисы (небольшая вероятность, но назвать её стоит).
- Сложный процесс обновления версии ПО, особенно если у вас имеются custom plugins. Придется протестировать отдельно сборку образа, отдельно накатывание новой версии на тестовую среду.
- Прежде всего это инструмент для визуализации данных. Для создания сложных приложений с элементами управления потребуется продвинутый уровень (необходимо изучить способы применения jinja & python в superset).
- Не очень удобный функционал фильтров, нет компактности. Стандартный Filter Box скоро будет удален из функционала (он к тому же потреблял много ресурсов, у меня есть такая гипотеза, которую я не проверял).
- Нет кнопок, переменных и т.п. функционала из коробки для работы с параметрами.
- Если нужно поменять datasource для дашборда (например, вы решите из одной схемы перенести таблицу в другую схему, чтобы изменить доступ), то придется создать новый datasource и в каждом chart заменить datasource. Но есть проблемка, при замене datasource в chart слетают все настройки chart (поля, меры, фильтры). Фактически приходится заново создавать chart. Проверял до 1.3.0 версии (возможно дальше этот багофичу починили).
- Очень ограниченный функционал таблиц, нет ссылок, картинок.
- Из документации не всегда понятно, что нужно сделать и как делать. Большая часть описана скорей для DevOps инженеров. Приходится делать множество попыток, прежде чем получается. После проприоритарных BI плюешься в разные стороны, т.к. сил на настройку тратится очень много и результат не всегда получается. Если Вы не спец по Linux и python — рекомендую закатать рукава 😉
Почему я рекомендую использовать Apache Superset?
Лично для меня есть несколько основных доводов согласно которым я хочу посоветовать использовать Apache Superset (в том числе вместо российского BI):
- Его условная бесплатность, популярность и простота использования;
- Наличия кучи коннекторов, в том числе для ClickHouse;
- Ядро Apache Superset — python и react (есть мотивация подтянуть, пригодится и в других инструментах);
- Динамично развивается функционал (некоторые фичи, например, как сертификация визуализаций, отсутствует в известных BI системах);
- На нем работают или вводят в эксплуатацию несколько крупных российских компаний (Вкусвилл, Сбер, Ozon, МТС, VK);
- Визуализации используются из Apache ECharts что очень круто;
- Если у Вас есть проприоритарный BI, то Superset однозначно позволит срезать косты по лицензиям для тех отчетов, которые являются простыми и которые необходимы широкому кругу лиц.
Обзор нововведений Apache Superset в релизах 1.3, 1.4, 1.5
В этом разделе описаны наиболее значимые новвоведения в релизах Apache Superset.
Примечания к релизу Apache Superset version 1.3.0
Усовершенствования в работе с диаграммами:
- Воронкообразная диаграмма
- Древовидная диаграмма
- Переработанная визуализация treemap
Улучшения пользовательского интерфейса:
- Улучшен пользовательский интерфейс галереи графиков (категории диаграмм)
- Облегчено добавление новых подключений к базе данных в Superset через пошаговую инструкцию.
Примечания к релизу Apache Superset version 1.4.0
Этот релиз содержит:
- Сертификация диаграмм и информационных панелей: Понимание того, какие диаграммы и информационные панели надежны, полезны и актуальны, является универсальной задачей в инструментах бизнес-аналитики. Чтобы решить эту проблему, теперь вы можете сертифицировать диаграммы и информационные панели и прикреплять к ним свое имя.
- Улучшенные возможности компоновки панели мониторинга: теперь можно добавлять вкладки в столбцы.
- Больше переменных в шаблонах Jinja: Шаблоны Jinja позволяют добавить больше динамики вашим информационным панелям. В Superset 1.4 добавлена поддержка ссылок и переменных в коде Jinja.
time_grain,time_column - Оповещения и отчеты в Superset получили несколько незначительных обновлений пользовательского интерфейса, которые сделали их более читабельными и удобными.
- ClickHouse: Superset теперь включает имена функций ClickHouse в автозаполнение для SQL Lab.
Примечания к релизу Apache Superset version 1.5.0
- Оптимизировали загрузку сложных информационных панелей
- Улучшили дизайн для нативных фильтров (superset native filters)
- Добавлен функционал зависимости фильтров друг от друга (теперь при выборе значений в одном фильтре ограничиваются отображаемые значения в других фильтрах) — привет ассоциативность 🙂
- Появился функционал добавления пользовательских выражений непосредственно в диаграммы (без необходимости добавления их в набор данных в виде сохраненных выражений)
- Сделан ряд улучшений для кэширования:
- Superset 1.5 представляет SupersetMetastoreCache , который позволяет кэшировать данные в хранилище метаданных Superset, не полагаясь на внешний кеш, такой как Redis или Memcached.
- Раньше информационные панели с большим количеством фильтров вызывали ошибки, потому что состояние фильтра находилось в самом URL-адресе, что приводило к проблеме с длинным URL-адресом. Теперь Superset хранит состояние Dashboard и Explore в кеше (а не в URL-адресе).
- Основываясь на обеих вышеупомянутых функциях, постоянные URL-адреса страниц Dashboard и Explore теперь сохраняют состояние в объектах JSON в хранилище метаданных Superset (вместо URL-адреса). Кроме того, URL-адреса содержат хэши вместо числовых идентификаторов для дополнительной безопасности.
Установка Apache Superset на docker с помощью Docker Compose
Устанавливается Apache Superset довольно просто, если не сопротивляться и сразу идти в сторону Docker. Т.к. основным минусом Apache Superset является необходимость много делать руками в среде Linux, а значит необходимо наличие специалиста, способного либо разобраться с Docker и Docker-Compose (в идеале DevOps инженера).
Интро для упрямых 
Установка напрямую в Linux среду возможна только при соблюдении множества факторов (версии python, библиотек, зависимостей и т.д. и т.п.). Любой фактор несоответствующий среде разработки сфейлит инсталляцию. Именно поэтому почти любой open source софт идет в комплекте с образом, dockerfile, docker-compose инструкциями и т.д.
Если вы ставите напрямую в свою среду без докера — то будьте готовы, что никто не поможет с ошибками, т.к. все работают через докер.Мне кажется, что дешевле по времени и перспективнее освоить Docker. Так точно надежнее будет, т.к. все зависимости задаются настройками, плюс это тестируется сообществом.
Apache Superset разворачивается всегда на конкретной версии python, а поставить фиксированную старую версию python в Linux без пляски с бубном тяжело.
Краткая инструкция по установке Apache Superset 1.5 через docker-compose
Установка docker и docker-compose на Ubuntu 20.04
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
# Обновляем существующий список пакето sudo apt update # Далее устанавливаем пакеты, которые позволят apt использовать пакеты через HTTPS: sudo apt install apt-transport-https ca-certificates curl software-properties-common # Далее добавим ключ GPG для официального репозитория Docker curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - # Добавляем ремозиторий докер в источники apt sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu focal stable" # Обновляем базу данных пакетов и добавим в нее пакеты Docker из недавно добавленного репозитория sudo apt update # Далее проверим, что установка будет выполняться из репозитория Docker, а не из репозитория Ubuntu по умолчанию apt-cache policy docker-ce # Мы должны получить следующий ответ (номер версии Docker может отличаться): # root@apache1superset:~# apt-cache policy docker-ce # docker-ce: # Installed: (none) # Candidate: 5:20.10.6~3-0~ubuntu-focal # Version table: # 5:20.10.6~3-0~ubuntu-focal 500 # 500 https://download.docker.com/linux/ubuntu focal/stable amd64 Packages # 5:20.10.5~3-0~ubuntu-focal 500 # 500 https://download.docker.com/linux/ubuntu focal/stable amd64 Packages # 5:20.10.4~3-0~ubuntu-focal 500 # 500 https://download.docker.com/linux/ubuntu focal/stable amd64 Packages # 5:20.10.3~3-0~ubuntu-focal 500 # ... # Далее устанавливаем докер командой (на доп.вопрос отвечаем "yes") sudo apt install docker-ce # Docker будет автоматически установлен, также запустится демон-процесс и будет активирован запуск при загрузке. # Проверить статус докера можно командой (что он running/active): sudo systemctl status docker # Загружаем текущую стабильную версию Docker Compose sudo curl -L "https://github.com/docker/compose/releases/download/v2.5.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose # Применяем разрешения для исполняемого файла к двоичному файлу sudo chmod +x /usr/local/bin/docker-compose # Чтобы протестировать docker-compose (установилась версия или нет), запустим команду docker-compose --version |
Установка Apache Superset 1.5
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# Клонируем проект из github git clone https://github.com/apache/superset.git # Переходим в директорию cd superset # Переключаемся на ветку релиза 1.5.0 (иногда без этого шага не удавалось инсталлировать, поэтому так делаю) git checkout 1.5.0 # Чекаем статус git status # Теперь нужно поставить версию образа для разветывания с помощью docker-compose. # Для этого в файле docker-compose-non-dev.yml (в корне проекта) изменяем строчку # x-superset-image: &superset-image apache/superset:${TAG:-latest-dev} # меняем на # x-superset-image: &superset-image apache/superset:1.5.0 # Запускаем установку (запустится скачивание образов с hub.docker.com) sudo docker-compose -f docker-compose-non-dev.yml up # =========================================== # После завершения инсталляции # Переходим по адресу http://localhost:8088/ # и авторизуемся логин/пароль: admin/admin # =========================================== |
Картинки по установке согласно описанным шагам
Шаг 1. Клонируем проект Superset из репозитория github:
git clone https://github.com/apache/superset.git
Шаг 2. Переходим в директорию, переключаемся на версию 1.5.0 и проверяем статус репозитория:
|
1 2 3 |
cd superset git checkout 1.5.0 git status |
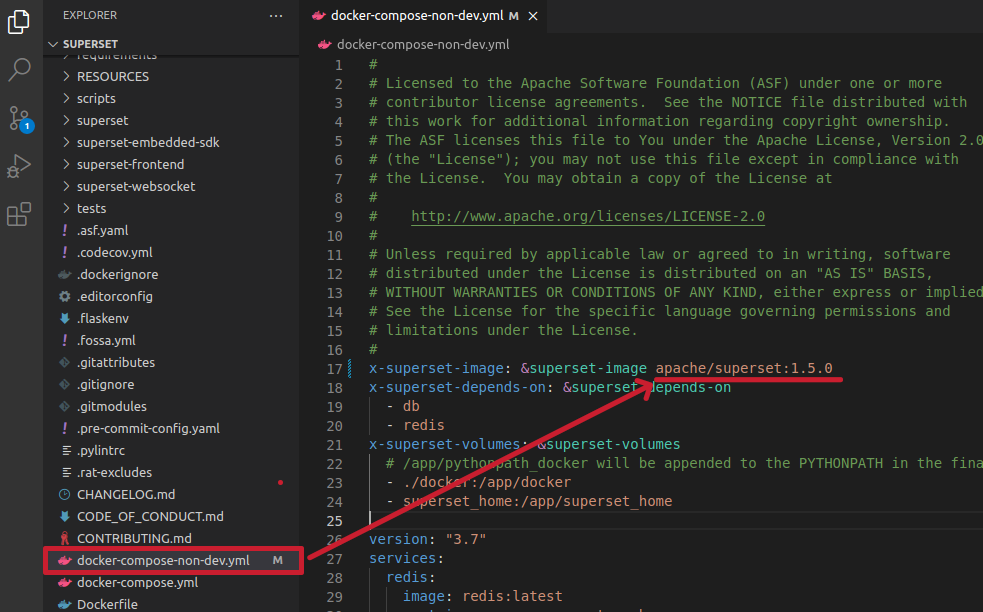
Шаг 3. Правим версию образа в файле docker-compose-non-dev.yml:
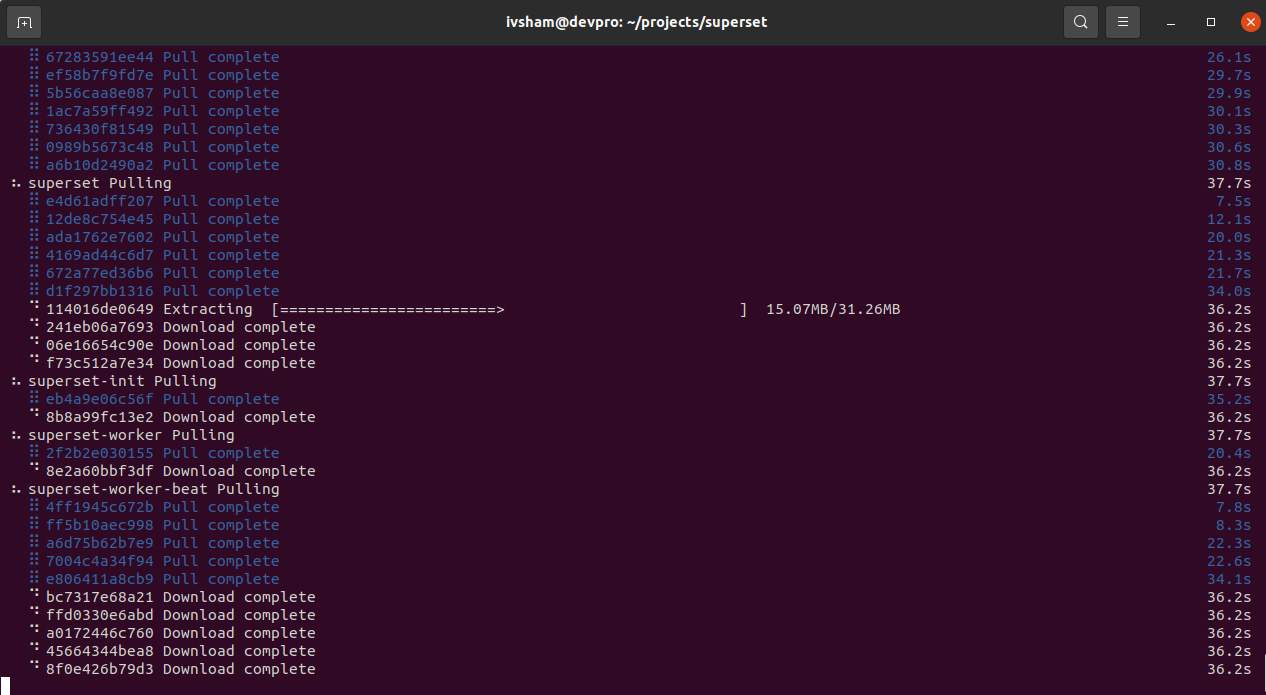
Шаг 4. Запуск инсталляции с помощью docker-compose:
|
1 |
sudo docker-compose -f docker-compose-non-dev.yml up |
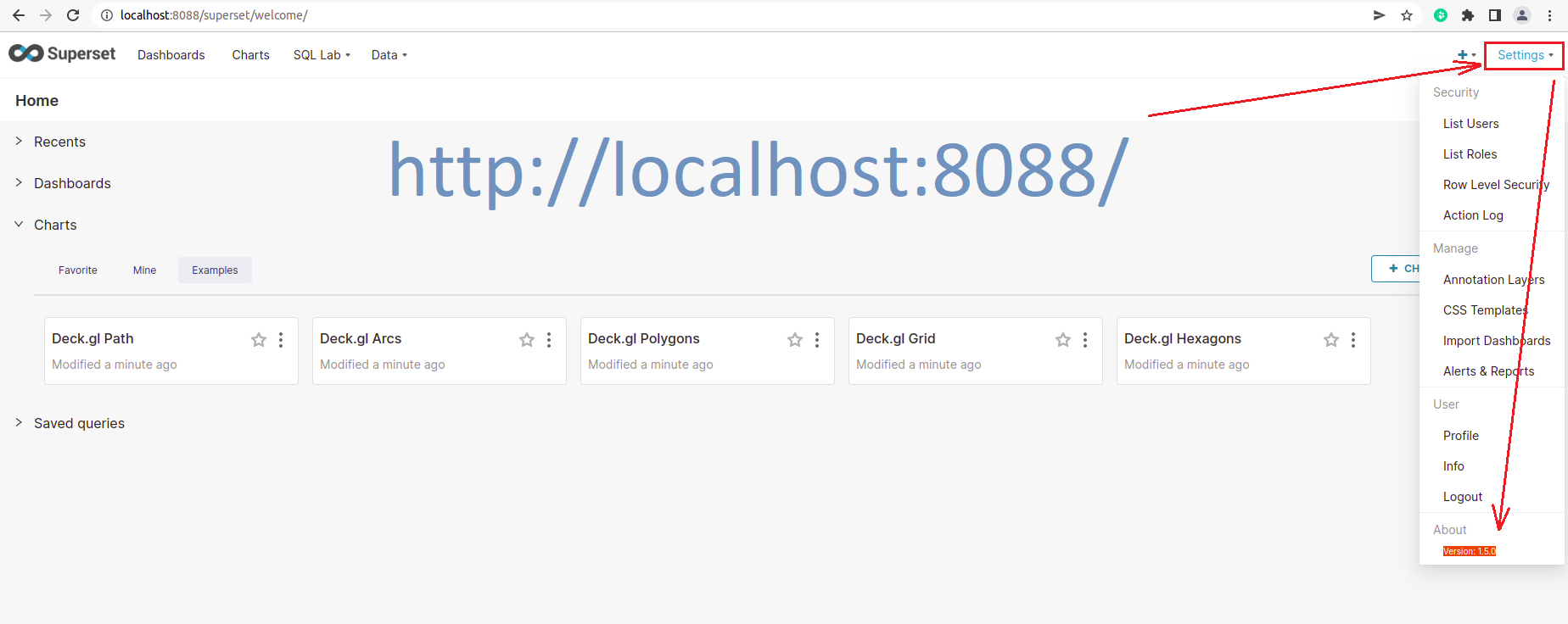
Шаг 5. Проверка установленной версии Apache Superset:
Какие файлы необходимо изучить для работы с Superset через Docker и Docker-Compose?
Директории и файлы, необходимые для:
- Сборки образа
- Установки Apache Superset с помощью docker-compose
- Настройки параметров инсталляции через docker-compose (пароли, порты и т.п.)
- Настройки параметров среды
Ниже представлены файлы, которые помогут Вам в настройке Apache Superset:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
[superset] │ ├──[docker] │ │ │ ├──[pythonpath_dev] │ │ ├── superset_config.py │ │ └── superset_config_local.example │ │ │ ├── .env │ ├── .env-non-dev │ ├── docker-bootstrap.sh │ ├── docker-ci.sh │ ├── docker-frontend.sh │ ├── docker-init.sh │ ├── frontend-mem-nag.sh │ ├── run-server.sh │ └── README.md │ ├── Dockerfile ├── docker-compose.yml └── docker-compose-non-dev.yml |
Описание последовательности действий при запуске docker-compose -f docker-compose-non-dev.yml up
- Сначала скачиваются все образы, которые необходимы для многоконтейнерной установки
- контейнер superset_app: образ apache/superset — версия 1.5.0 (1.59 GB)
- контейнер superset_cache: образ redis — версия latest (105.4 MB)
- контейнер superset_db: образ postgres — версия 10 (199.9 MB)
- контейнер superset_init: образ apache/superset — версия 1.5.0
- контейнер superset_worker: образ apache/superset — версия 1.5.0
- контейнер superset_worker_beat: образ apache/superset — версия 1.5.0
- Конфигурация для DB с метаданными (postgresql) берется из файла
docker/.env-non-dev - Далее запускается
/app/docker/docker-bootstrap.shиapp-gunicorn - Далее запускается скрипт
/app/docker/docker-init.sh - Далее запускается
/app/docker/docker-bootstrap.shиworker - Далее запускается
/app/docker/docker-bootstrap.shиbeat
Рекомендую сразу установить себе portainer, чтобы работать с docker (особенно для новичков будет полезно). В нем можно увидеть по stack = superset установленные контейнеры, сети и т.п. инфу:
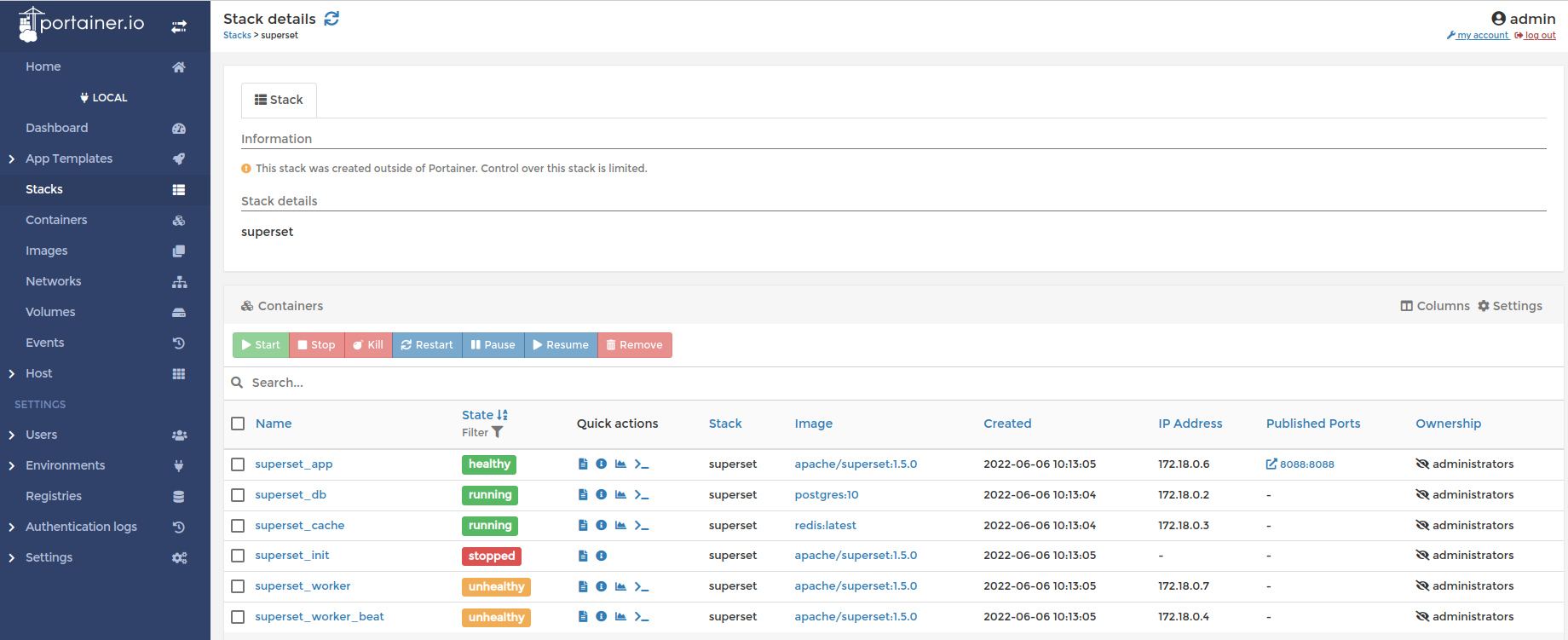
Например, можно посмотреть настройки, примененные к отдельному контейнеру:
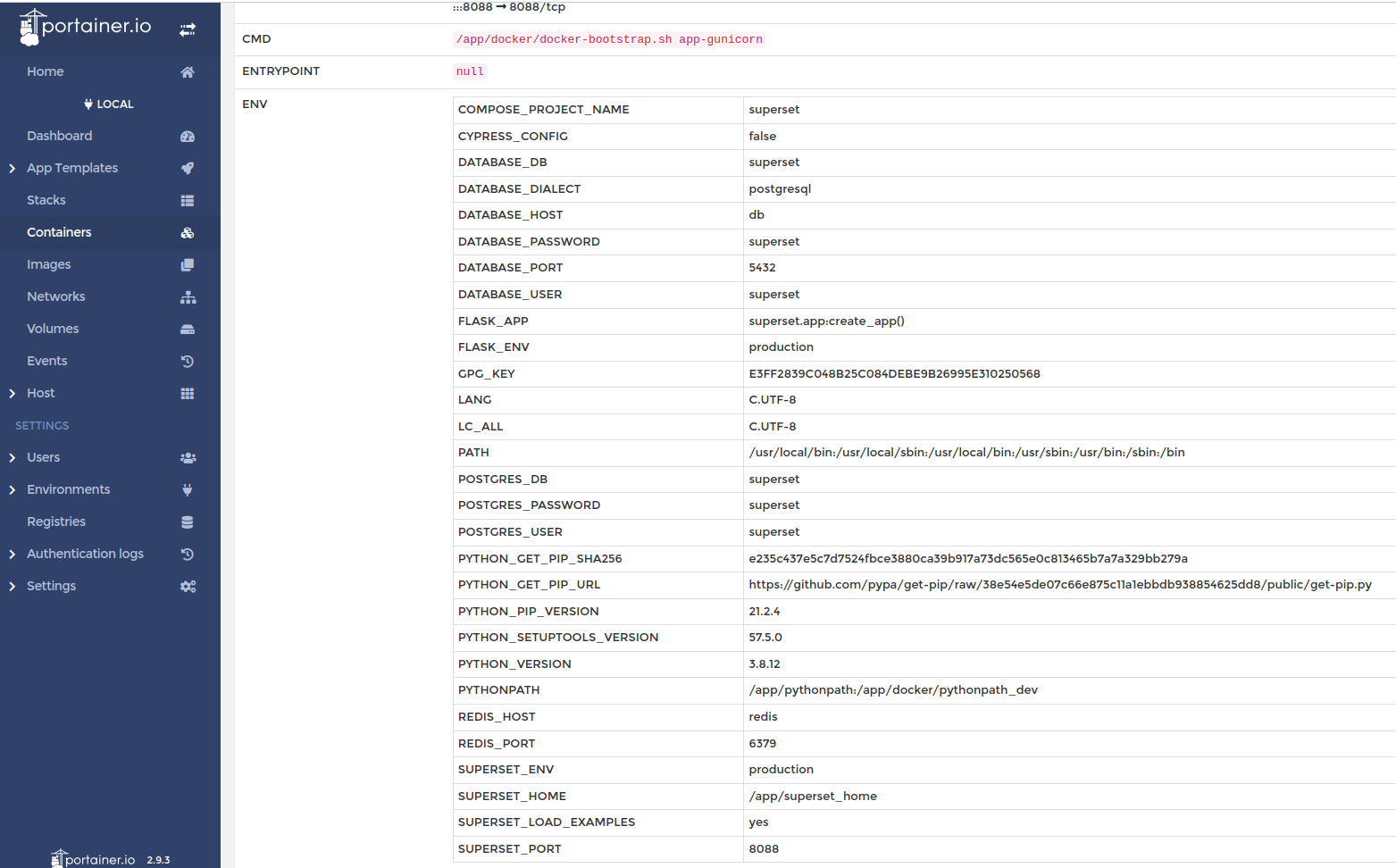
Описание последовательности процессов на основе лога Superset
Описание процесса запуска Superset из лога работы docker-compose:
- Attaching to superset_db, superset_cache, superset_init, superset_worker_beat, superset_worker, superset_app
- Starting web app (Redis is starting, Server initialized, Warning: no config file specified, using the default config. In order to specify a config file use redis-server /path/to/redis.conf)
- PostgreSQL Database
- Init Step 1/4 [Starting] — Applying DB migrations
- Starting Celery worker
- Starting Celery beat
- Starting gunicorn
- Using worker: gthread
- logging was configured successfully
- Loaded your LOCAL configuration at [/app/docker/pythonpath_dev/superset_config.py]
- celery beat v4.4.7 (cliffs) is starting
- Init Step 2/4 [Starting] — Setting up admin user ( admin / admin ) — логин и пароль по умолчанию
- Init Step 3/4 [Starting] — Setting up roles and perms
- Init Step 4/4 [Starting] — Loading examples
Схема зависимостей в инсталляции Apache Superset через docker-compose
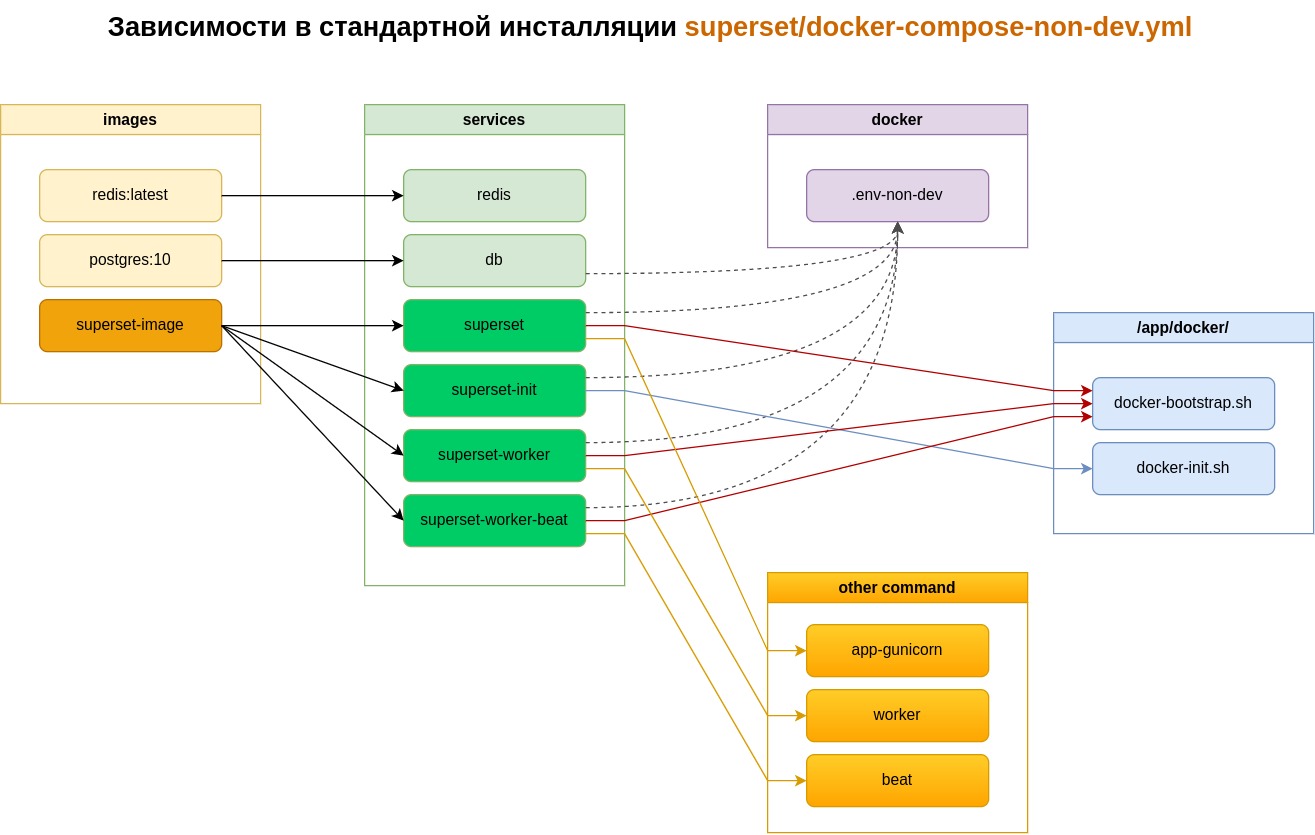
Описание файла docker-bootstrap.sh
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
set -eo pipefail REQUIREMENTS_LOCAL="/app/docker/requirements-local.txt" # If Cypress run – overwrite the password for admin and export env variables if [ "$CYPRESS_CONFIG" == "true" ]; then export SUPERSET_CONFIG=tests.integration_tests.superset_test_config export SUPERSET_TESTENV=true export ENABLE_REACT_CRUD_VIEWS=true export SUPERSET__SQLALCHEMY_DATABASE_URI=postgresql+psycopg2://superset:superset@db:5432/superset fi # # Make sure we have dev requirements installed # if [ -f "${REQUIREMENTS_LOCAL}" ]; then echo "Installing local overrides at ${REQUIREMENTS_LOCAL}" pip install -r "${REQUIREMENTS_LOCAL}" else echo "Skipping local overrides" fi if [[ "${1}" == "worker" ]]; then echo "Starting Celery worker..." celery --app=superset.tasks.celery_app:app worker -Ofair -l INFO elif [[ "${1}" == "beat" ]]; then echo "Starting Celery beat..." celery --app=superset.tasks.celery_app:app beat --pidfile /tmp/celerybeat.pid -l INFO -s "${SUPERSET_HOME}"/celerybeat-schedule elif [[ "${1}" == "app" ]]; then echo "Starting web app..." flask run -p 8088 --with-threads --reload --debugger --host=0.0.0.0 elif [[ "${1}" == "app-gunicorn" ]]; then echo "Starting web app..." /usr/bin/run-server.sh fi |
Описание файла docker-init.sh
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
set -e # # Always install local overrides first # /app/docker/docker-bootstrap.sh STEP_CNT=4 echo_step() { cat <<EOF ###################################################################### Init Step ${1}/${STEP_CNT} [${2}] -- ${3} ###################################################################### EOF } ADMIN_PASSWORD="admin" # If Cypress run – overwrite the password for admin and export env variables if [ "$CYPRESS_CONFIG" == "true" ]; then ADMIN_PASSWORD="general" export SUPERSET_CONFIG=tests.integration_tests.superset_test_config export SUPERSET_TESTENV=true export ENABLE_REACT_CRUD_VIEWS=true export SUPERSET__SQLALCHEMY_DATABASE_URI=postgresql+psycopg2://superset:superset@db:5432/superset fi # Initialize the database echo_step "1" "Starting" "Applying DB migrations" superset db upgrade echo_step "1" "Complete" "Applying DB migrations" # Create an admin user echo_step "2" "Starting" "Setting up admin user ( admin / $ADMIN_PASSWORD )" superset fab create-admin \ --username admin \ --firstname Superset \ --lastname Admin \ --email admin@superset.com \ --password $ADMIN_PASSWORD echo_step "2" "Complete" "Setting up admin user" # Create default roles and permissions echo_step "3" "Starting" "Setting up roles and perms" superset init echo_step "3" "Complete" "Setting up roles and perms" if [ "$SUPERSET_LOAD_EXAMPLES" = "yes" ]; then # Load some data to play with echo_step "4" "Starting" "Loading examples" # If Cypress run which consumes superset_test_config – load required data for tests if [ "$CYPRESS_CONFIG" == "true" ]; then superset load_test_users superset load_examples --load-test-data else superset load_examples fi echo_step "4" "Complete" "Loading examples" fi |
Архитектура Apache Superset
Superset использует React и TypeScript во внешнем интерфейсе и Python в бэкэнде. Для улучшения производительности используется трёхуровневое кэширование через Flask-Cache.
Фреймворк Flask выполняет задачи CRUD и работу с ролями Roles, Authentication и т.д. Pandas выполняет преобразования данных, полученных из БД. Для подключения к базе данных и выполнения запросов используется библиотека SQLAlchemy.
Superset также является облачным в том смысле, что он гибкий и позволяет вам выбирать:
- веб-сервер (Gunicorn, Nginx, Apache);
- механизм базы данных метаданных (MySQL, Postgres, MariaDB и т.д.);
- очередь сообщений (Redis, RabbitMQ, SQS и т.д.);
- серверная часть результатов (S3, Redis, Memcached и т.д.);
- уровень кэширования (Memcached, Redis и т.д.).
Superset также хорошо работает с такими сервисами, как NewRelic, StatsD и DataDog, и может выполнять аналитические рабочие нагрузки для большинства популярных технологий баз данных.
Apache Superset включает следующие компоненты:
- Веб-сервер (может работать несколько экземпляров)
- База данных метаданных
- Кэш-слой
- Очередь сообщений для асинхронных запросов
- Серверная часть результатов
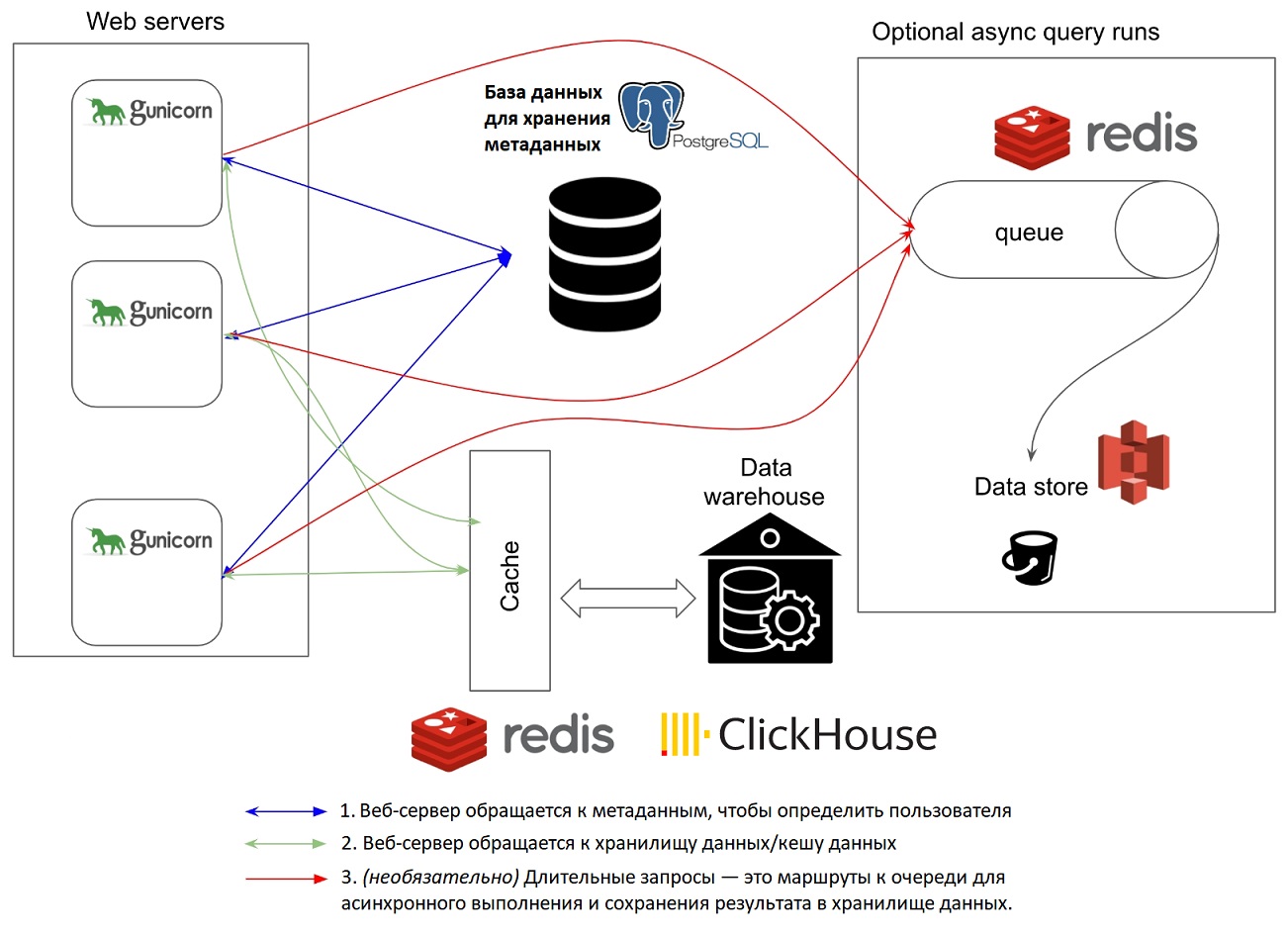
Apache Superset состоит из множества компонентов, которые отвечают за функционирование Frontend и Backend. Для Frontend использованы технологии node.js, javascript, React. Для Backend — Python (Flask, Pandas, SQLAlchemy).

Описание функциональности компонентов:
- Celery — это библиотека Python, используемая для обработки трудоемких задач и делегирования их отдельным процессам или распределенным сетевым хостам, чтобы снизить нагрузку на веб-серверы / серверные службы. Celery — хорошее решение для планирования выполнения задач в архитектуре микросервисов.
- celery beat — планировщик, который запускает задачи через равные промежутки времени, которые затем выполняются доступными рабочими узлами в кластере.
- Celery реализует Workers с помощью пула выполнения, поэтому количество задач, которые может выполнить каждый worker, зависит от количества процессов в пуле выполнения.
Дашборд Apache Superset состоит из Charts, которые связаны с заранее созданными datasets, которые подключены к хранилищам данных или базам данных с заранее подготовленными витринами данных.

Правильный HTTP-сервер WSGI
Вы можете настроить Superset для работы на Nginx или Apache, однако многие используют Gunicorn, который является предпочтителен для использования в асинхронном режиме (обеспечивает параллелизм в работе).
Конфигурация Python для Apache Superset (superset_config.py)
Чтобы настроить ваше приложение, вам нужно создать файл (модуль) superset_config.py и убедиться, что он находится в вашем PYTHONPATH.
Все параметры и значения по умолчанию, определенные в https://github.com/apache/superset/blob/master/superset/config.py , можно изменить в вашем локальном файле superset_config.py. Администраторы захотят прочитать файл, чтобы понять, что можно настроить локально, а также значения по умолчанию.
Поскольку superset_config.py действует как модуль конфигурации Flask, его можно использовать для изменения настроек самого Flask, а также расширений Flask, таких как flask-wtf, flask-caching, flask-migrateи flask-appbuilder. Flask App Builder, веб-фреймворк, используемый Superset, предлагает множество настроек конфигурации. Пожалуйста, обратитесь к документации Flask App Builder для получения дополнительной информации о том, как его настроить.
Обязательно измените:
SQLALCHEMY_DATABASE_URI: по умолчанию он хранится в~/.superset/superset.dbSECRET_KEY: в длинную случайную строку
Кэширование в Superset
Superset использует Flask-Caching для кэширования. Настроить кеширование так же просто, как предоставить пользовательскую конфигурацию кеша superset_config.py, которая соответствует спецификациям Flask-Caching. Flask-Caching поддерживает различные механизмы кэширования, включая Redis, Memcached, SimpleCache (в памяти) или локальную файловую систему. Также поддерживаются настраиваемые серверные части кэша. Подробности смотрите здесь.
Можно настроить следующие конфигурации кэша:
- Кэш метаданных (необязательно):
CACHE_CONFIG - Данные диаграммы, запрашиваемые из наборов данных (необязательно):
DATA_CACHE_CONFIG - Результаты запроса лаборатории SQL (необязательно):
RESULTS_BACKEND. - Состояние фильтра панели мониторинга (обязательно):
FILTER_STATE_CACHE_CONFIG. - Изучите данные формы диаграммы (обязательно):
EXPLORE_FORM_DATA_CACHE_CONFIG
Обратите внимание, что требуется кэширование Dashboard и Explore. Если эти кэши не определены, Superset возвращается к использованию встроенного кэша, который хранит данные в базе данных метаданных. Хотя рекомендуется использовать выделенный кэш, встроенный кэш также можно использовать для кэширования других данных.
Библиотеки для кеширования:
- Redis (рекомендуется): пакет Redis Python
- Memcached: рекомендуется использовать клиентскую библиотеку pylibmc т.к.
python-memcachedне поддерживает правильное хранение двоичных данных.
Прогрев кеша дашбордов
В Superset есть задача Celery, которая может периодически запускаться и прогревать кеш на основе разных стратегий.
Например:
|
1 2 3 4 5 6 7 8 9 10 11 |
CELERYBEAT_SCHEDULE = { 'cache-warmup-hourly': { 'task': 'cache-warmup', 'schedule': crontab(minute=0, hour='*'), # hourly 'kwargs': { 'strategy_name': 'top_n_dashboards', 'top_n': 5, 'since': '7 days ago', }, }, } |
будет кэшировать все диаграммы в топ-5 самых популярных информационных панелей каждый час.
Стратегии прогрева кеша Superset находятся в директории: superset/tasks/cache.py
Что такое Flower и зачем он нужен?
Flower — это веб-инструмент для мониторинга кластера Celery, который вы можете установить из pip:
|
1 |
pip install flower |
Вы можете запустить Flower, используя:
|
1 |
celery --app=superset.tasks.celery_app:app flower |
Также с помощью Flower UI можно управлять асинхронными выполнениями запросов через Celery-based executors.
Настройка Superset Config файла
todo
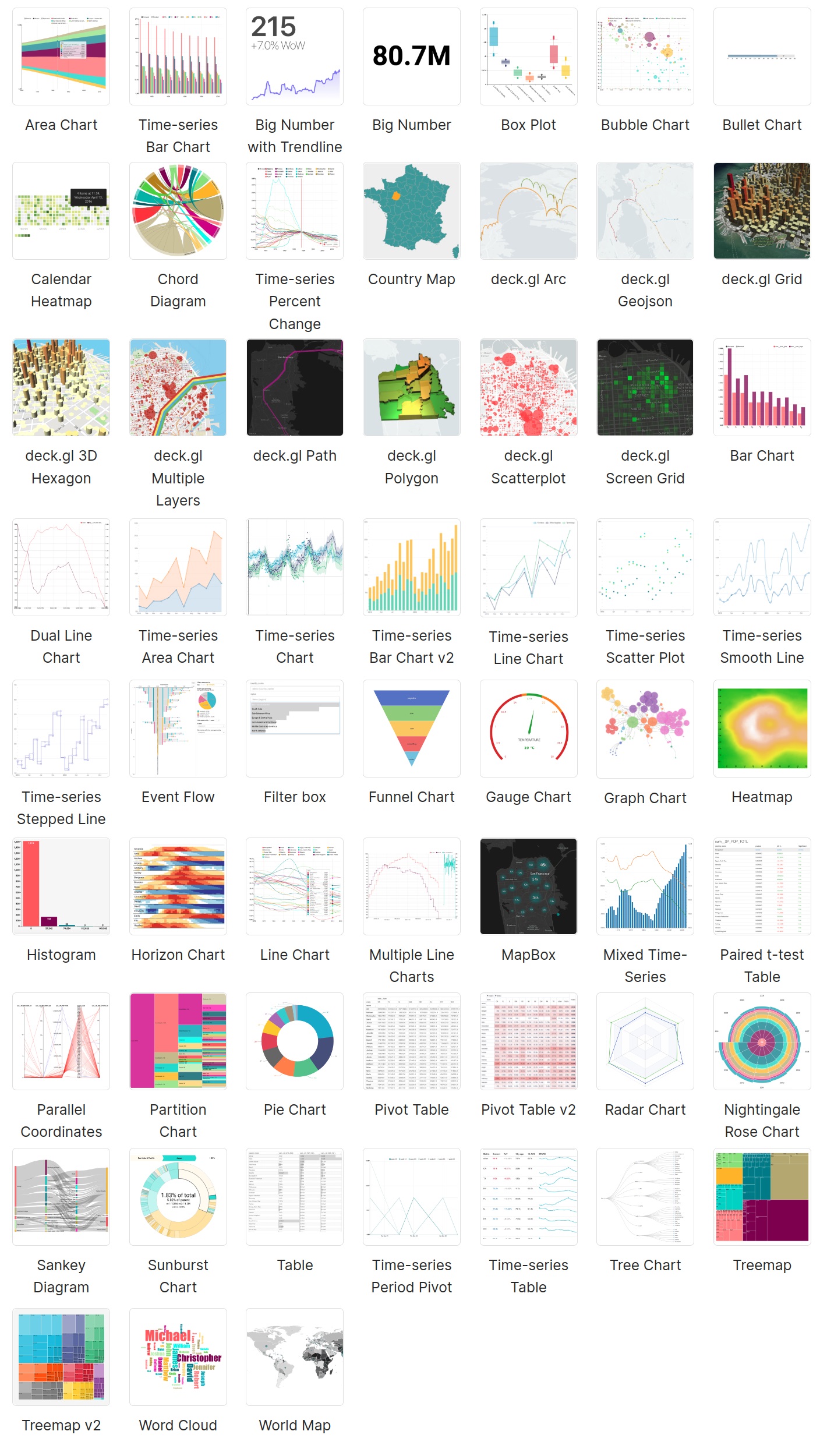
Список доступных визуализаций в версии Apache Superset 1.5.0
Канал в телеграме Apache Superset BI:
Примеры дашбордов Apache Superset
Ниже представлены примеры дашбордов из демо-примеров, которые загружаются в стандартной конфигурации при установке через docker-compose.
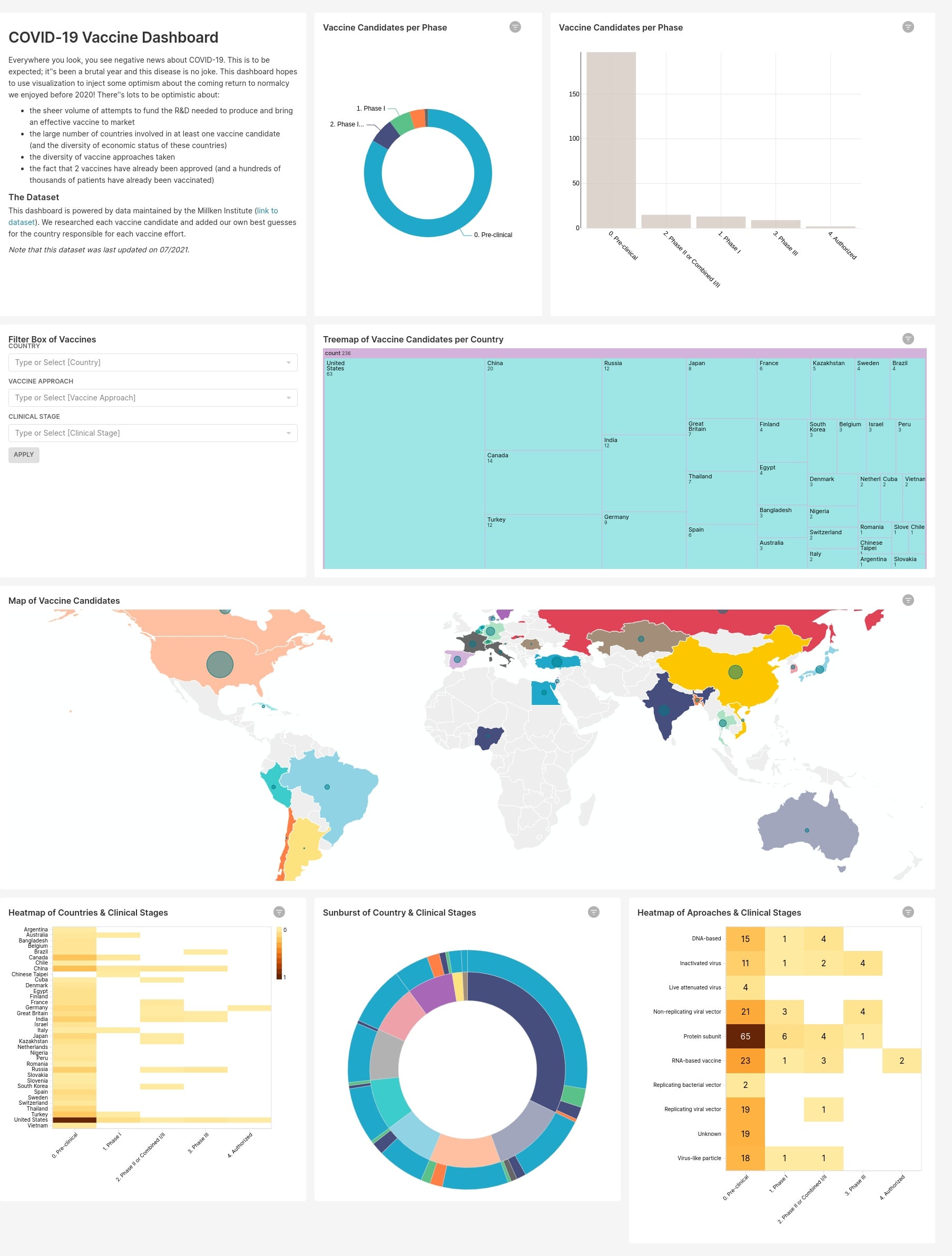

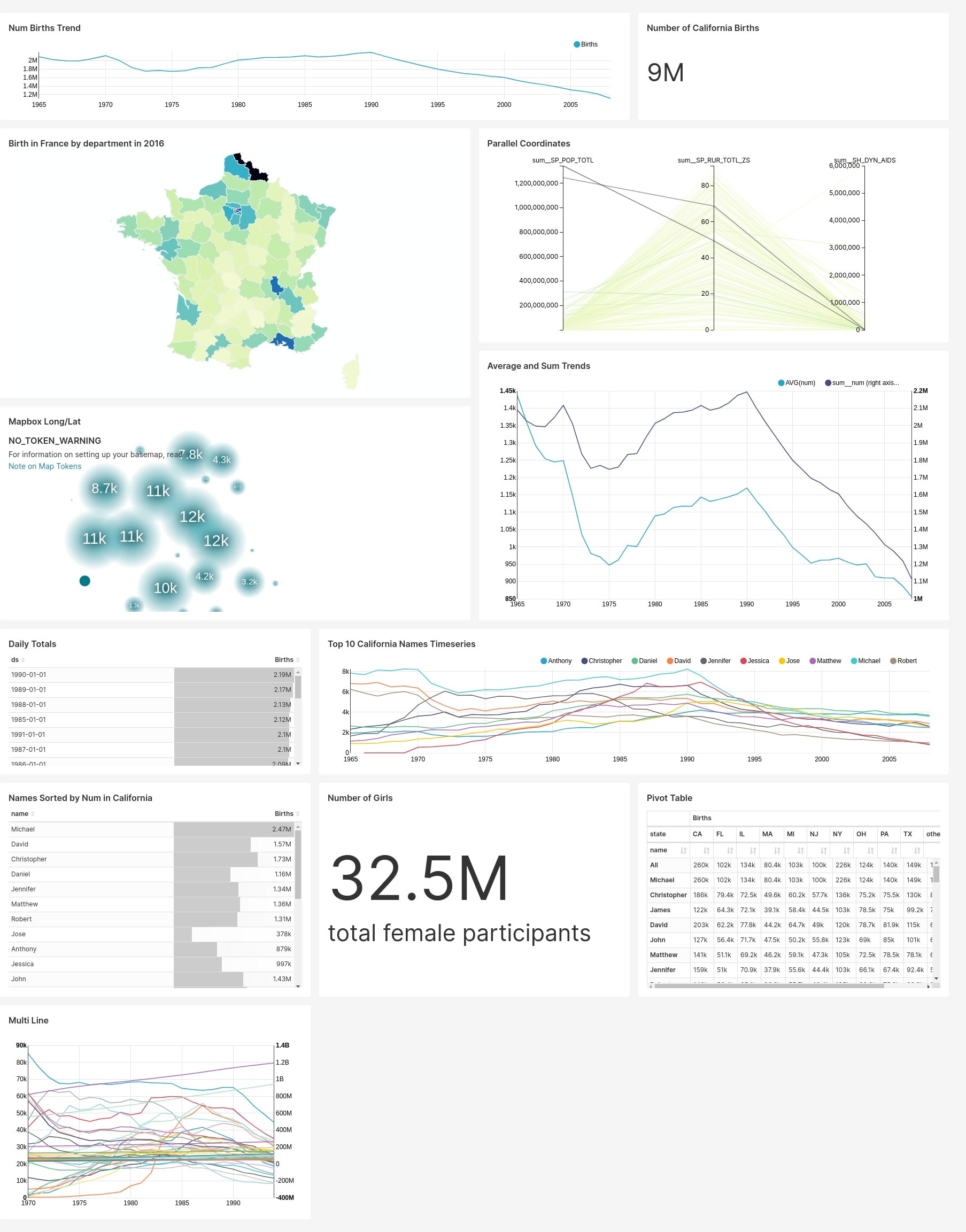

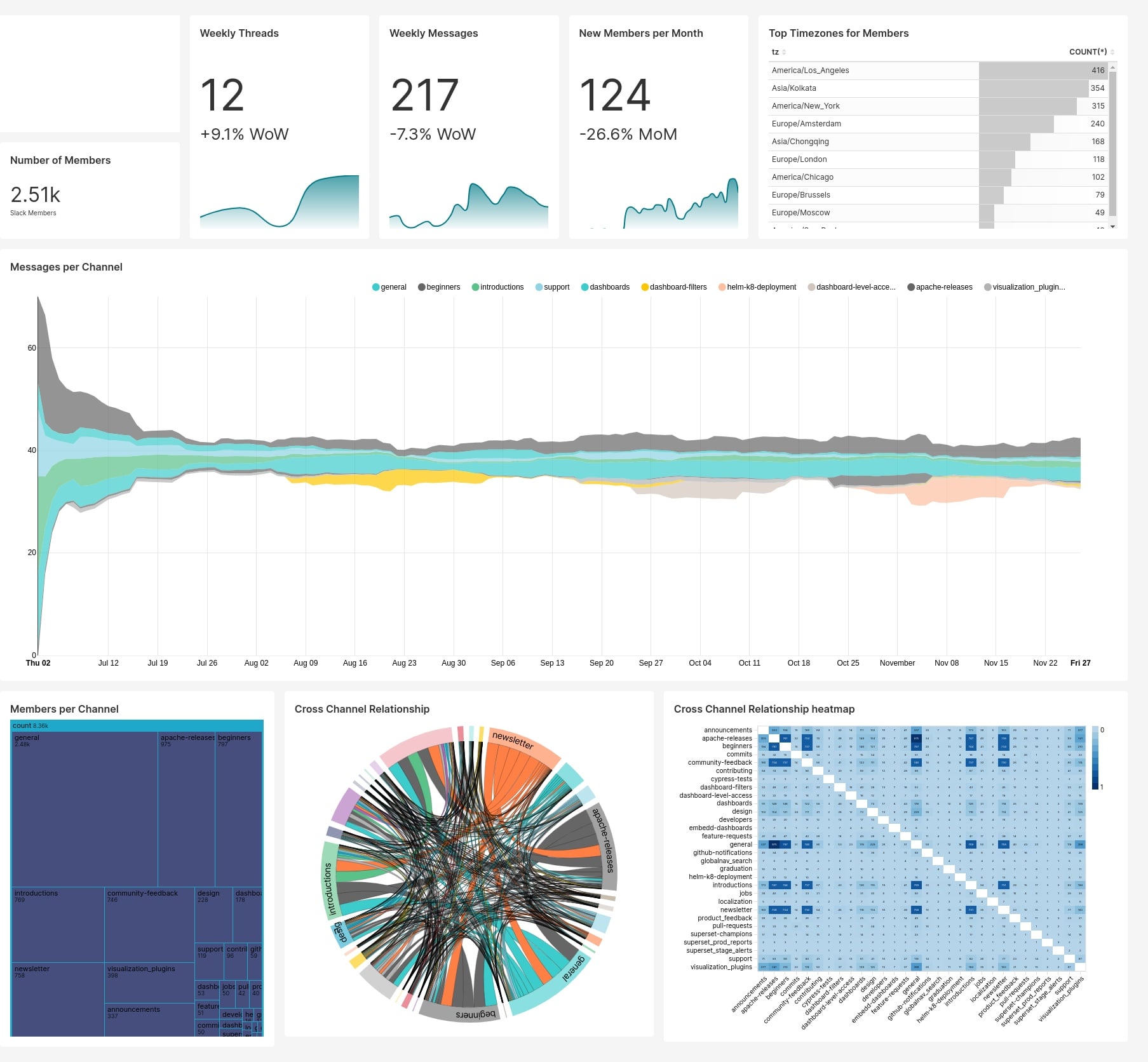

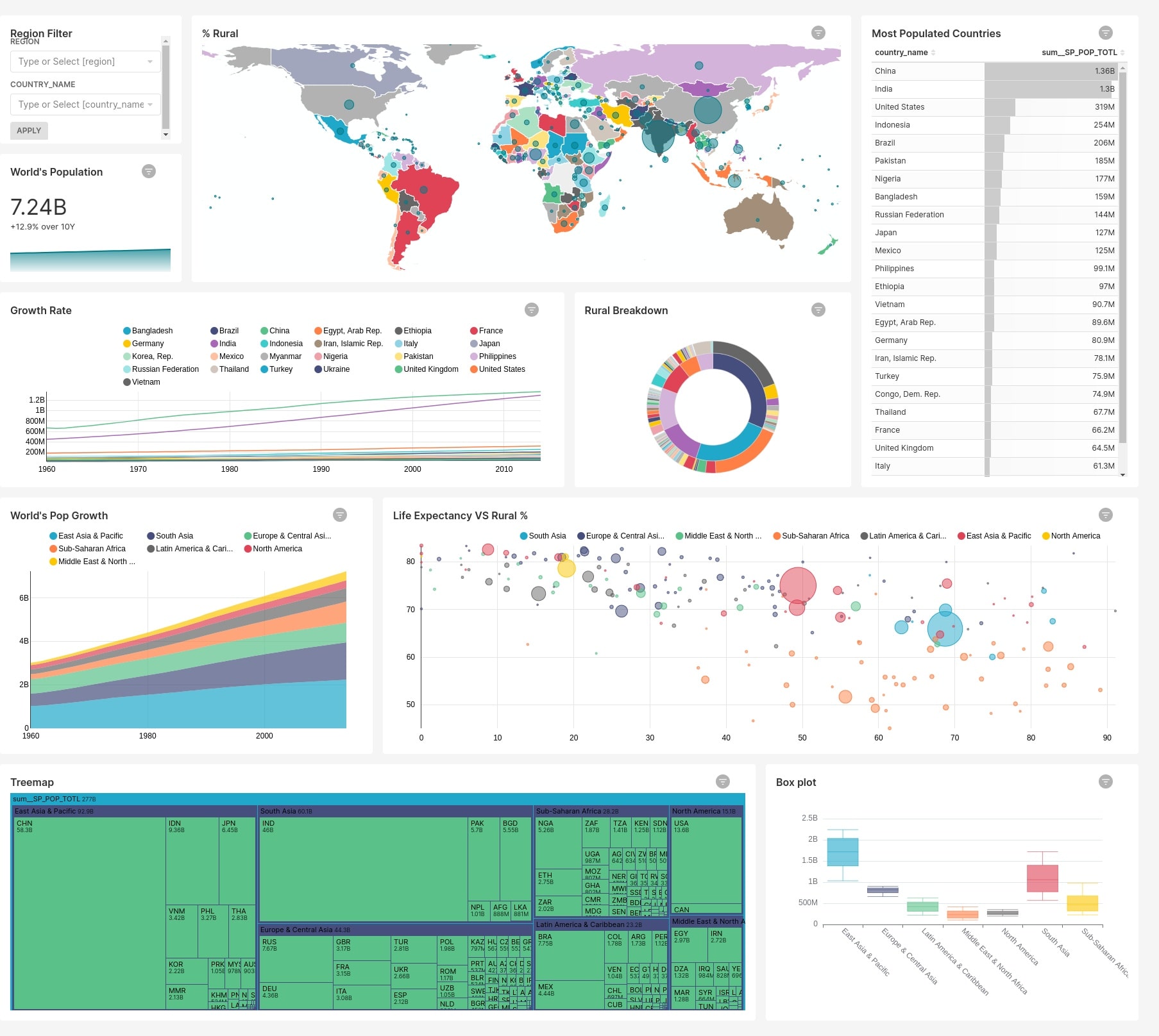
Сборник примеров архитектур BI-систем на базе Apache Superset
ВкусВилл — Архитектура BI-системы

Полное видео
Платформа данных в Леруа Мерлен
Источник: habr.com Платформа данных в Леруа Мерлен. Part 2. Обновления 2021 года: Flink и Superset

Подборка материалов по Apache Superset для дальнейшего развития навыков разработки
Сборка и деплой кастомной визуализации в Apache Superset
- Build & Deploy Custom Superset Viz Plugin
- Building Custom Viz Plugins in Superset v2 (Updated for Monorepo)
ClickHouse
- Connecting to Databases — ClickHouse (official documentation)
- Connect Superset to ClickHouse (Altinity Documentation)
- Connect Superset to ClickHouse (ClickHouse Documentation)
- Preset.io: Visualizing ClickHouse Data — ClickHouse SQLAlchemy
Выгрузка в Excel из Superset
Dynamic Imports Example Plugin
Dynamic Imports Example Plugin (фича не опробована лично мной, но функционал присутствует в настройках)
Динамический импорт плагинов означает, что весь ваш код хранится на каком-то сервисе cdn и вам не нужно при каждом изменении плагина билдить образ и деплоить снова и снова superset.
- An example plugin to demonstrate dynamic import
- Indicator chart plugin for Apache Superset — пытался этот пример поднять в окружении, но не заработало (на основе dynamic imports example plugin).

