
Contents
- 1 Что такое ClickHouse и какие есть в нем настройки
- 2 Как развернуть быстро Clickhouse с помощью Docker
- 2.1 Установка Clickhouse из официального образа с hub.docker.com
- 2.2 Видео «Установка базы данных ClickHouse в виде контейнера Docker»
- 2.3 Установка ClickHouse с помощью docker-compose
- 2.4 Пример установки ClickHouse с помощью Docker Compose #1
- 2.5 Пример установки ClickHouse с помощью Docker Compose #2
- 3 Подключаемся к ClickHouse с помощью DBeaver
- 4 Интерфейсы для доступа к Clickhouse
- 5 Как создать database в Clickhouse, таблицу и вставить тестовые данные
- 6 Как подключиться к Clickhouse с помощью Python
- 7 Как создать таблицу в Clickhouse и записать данные с помощью Python
- 8 Пример скрипта динамической вставки данных в ClickHouse
- 9 Как получить данные из таблицы Clickhouse в Python
Что такое ClickHouse и какие есть в нем настройки
ClickHouse — это мощная столбцовая база данных, написанная на C, которая генерирует аналитические и статистические отчеты в режиме реального времени с помощью операторов SQL!
Какие кейсы использования ClickHouse могут быть: сессионная и событийная аналитика, аналитика по бизнес-метрикам, генерация аналитических запросов по структурированным данным c минимальной задержкой, анализ операционных логов, анализ финансовых данных, Data Science, продуктовая аналитика и т.п.
Выполнение запросов в ClickHouse осуществляется значительно быстрее, чем в Big Data системах класса SQL-on-Hadoop (например, такие системы, как Apache Hive, Cloudera Impala, Presto и Spark) или при работе с данными в колоночных форматах, таких как Parquet или Kudu.
Файлы конфигурации сервера ClickHouse
Конфигурация сервера Clickhouse состоит из двух частей: настроек сервера (config.xml) и настроек пользователей (users.xml).
По умолчанию они хранятся в папке /etc/clickhouse-server/ в двух файлах config.xml и users.xml.
Рекомендуется никогда не изменять файлы vendor config и помещать ваши изменения в отдельные файлы .xml в подпапках. Этот способ проще в обслуживании и упрощает обновление Clickhouse.
/etc/clickhouse-server/users.d— подпапка для пользовательских настроек./etc/clickhouse-server/config.d— подпапка для настроек сервера./etc/clickhouse-server/conf.d— подпапка для любых (обоих) настроек.
Имена ваших файлов xml могут быть произвольными, но они применяются в алфавитном порядке.
Описание общих ключевых моментов по ClickHouse
Официальная документация — Configuration Files (En) & Конфигурационные файлы (Ru)
Конфигурационные файлы:
- Основной файл конфигурации сервера — config.xml (в /etc/clickhouse-server/config.xml ) — все настройки сервера, такие как порт прослушивания, регистратор, удаленный доступ, настройка кластера (shards и replicas), системные настройки (часовой пояс, umask и др.), мониторинг, журналы запросов, словари, сжатие и так далее.
Настройки сервера: Server Configuration Parameters -> Server Settings (En) - Основной файл конфигурации пользователя — users.xml (в /etc/clickhouse-server/users.xml ), в котором указаны профили, пользователи, пароли, ACL, квоты и т.д. Он также поддерживает конфигурацию пользователя на основе SQL.
Доступные настройки и параметры пользователей: User Settings (En) - По умолчанию есть пользователь root с правами администратора без пароля, который может подключаться к серверу только с localhost.
- Не редактируйте основные файлы конфигурации. Некоторые параметры могут быть объявлены устаревшими и удалеными, а измененный файл конфигурации может стать несовместимым с новыми выпусками.
- Каждый параметр конфигурации можно переопределить с помощью файлов конфигурации в config.d/ (о чем было указано выше).
users.xml — здесь описываются юзеры с паролями, также задается список сетей для пользователей, квоты, описываются профили пользователей. Можно установить на пользователя дефолтный фильтр на конкретную таблицу, задать readonly mode и т.д.
Порты ClickHouse по умолчанию:
- 8123 — порт HTTP — клиента (8443 — HTTPS). Клиент может подключаться к curl или wget или другим HTTP(S) — клиентам командной строки для управления и вставки данных в базы данных и таблицы.
- 9000 — это собственный клиентский порт TCP/IP (9440 — это порт с поддержкой TLS для этой службы) для управления и вставки данных в базы данных и таблицы.
- 9004 — это порт протокола MySQL. ClickHouse поддерживает проводной протокол MySQL.
- 9009 — это порт, который ClickHouse использует для обмена данными между серверами ClickHouse при использовании настройки кластера и реплик/шардов.
Другие описания:
- Существует каталог флагов , в котором файлы со специальными именами могут указывать ClickHouse для обработки команд. Например, создание пустого файла с именем: /var/lib/clickhouse/flags/force_restore_data даст указание ClickHouse начать процедуру восстановления сервера.
- Хорошей практикой является создание резервной копии всего каталога конфигурации, несмотря на то, что основные файлы конфигурации не изменены и находятся в исходном состоянии.
- Команды SQL, поддерживаемые сервером CickHouse : https://clickhouse.com/docs/en/sql-reference/ и https://clickhouse.com/docs/en/sql-reference/statements/
- Базовым и фундаментальным типом таблицы является MergeTree , который предназначен для вставки очень большого количества данных в таблицу — https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/mergetree/
- Имейте в виду, ClickHouse поддерживает синтаксис SQL и некоторые операторы SQL, но операторы UPDATE и DELETE не поддерживаются, только INSERT !
Основная идея ClickHouse — не изменять данные, а только добавлять! - Пакетные INSERT являются предпочтительным способом вставки данных! На самом деле в руководстве по ClickHouse есть рекомендация 1 INSERT в секунду.
Ряд описаний по параметрам запуска в Docker
Volumes
Как правило, вы можете смонтировать следующие папки внутри вашего контейнера для сохранения постоянства:
/var/lib/clickhouse/— основная папка, в которой ClickHouse хранит данные;/var/log/clickhouse-server/— logs;/etc/clickhouse-server/config.d/*.xml— файлы с настройками конфигурации сервера;/etc/clickhouse-server/users.d/*.xml— файлы с настройками использования;/docker-entrypoint-initdb.d/— папка со скриптами инициализации базы данных;/var/lib/clickhouse/user_files/— файлы со словарями (пользовательские csv files).
Основная терминология по ClickHouse
- Партиционирование данных — разбивка данных 1 большой таблицы на множество частей по какому-то признаку (например по периоду — по месяцам).
- Шардирование — это стратегия горизонтального масштабирования кластера, при которой части одной базы данных ClickHouse размещаются на разных шардах. Шард состоит из одного или нескольких хостов-реплик. Запрос на запись или чтение в шард может быть отправлен на любую его реплику, выделенного мастера нет. При вставке данных они будут скопированы с реплики, на которой был выполен INSERT-запрос, на другие реплики шарда в асинхронном режиме.
- Репликация — синхронизация данных между хостами-репликами в рамках одной шарды (в рамках одного кластера).
- ClickHouse-кластер (или шард) — это один или несколько хостов базы данных, между которыми настраивается репликация.
- Apache Zookeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services.
- Материальные вьюхи (Materialized View) — хранят данные, преобразованные соответствующим запросом SELECT. Материализованные представления в ClickHouse больше похожи на after insert триггеры. Если в запросе материализованного представления есть агрегирование, оно применяется только к вставляемому блоку записей. Любые изменения существующих данных исходной таблицы (например обновление, удаление, удаление раздела и т.д.) не изменяют материализованное представление.
- Внешние словари — Существует возможность подключать собственные словари из различных источников данных. Источником данных для словаря может быть локальный текстовый/исполняемый файл, HTTP(s) ресурс или другая СУБД.
-
Engine — Движок таблицы (тип таблицы) определяет:
-
- Как и где хранятся данные, куда их писать и откуда читать.
- Какие запросы поддерживаются и каким образом.
- Конкурентный доступ к данным.
- Использование индексов, если есть.
- Возможно ли многопоточное выполнение запроса.
- Параметры репликации данных.
Clickhouse использует последовательные чтение и запись на диск.
Суть шардирования: взяли данные и разделили частями на разные шарды (на разные кластеры/серверы). Это нужно для хранения огромного числа данных. Заправшиваются данные с каждого шарда (запрос sql), затем результаты склеиваются и обрабатываются, после итоговый результат отдается юзеру.
Zookeeper — используется для хранения состояний репликации. В случае сбоя реплика пойдет в Zookeeper, получит инфу о данных, далее пойдет в соседнюю реплику и заберет нужный кусок данных. Потом, после обновления данных, реплика идет в Zookeeper и ставит пометку об обновлении.
Схема, поясняющая, что такое шард и реплика:

Репликация и шардирование настраивается на уровне таблиц. Т.е. можно сделать таблицы с разной конфигурацией (какие-то таблицы можно разнести на несколько шард, какие-то оставить на одной, аналогично настраивается реплицирование на уровне каждой отдельной таблицы).
Зачем нужна реплика:
- Отказоустойчивость
- Распараллеливание чтения
Важно: Рекомендуется создавать реплицируемые таблицы на всех хостах кластера, иначе после восстановления кластера из резервной копии может произойти потеря данных.
Как развернуть быстро Clickhouse с помощью Docker
Установка Clickhouse из официального образа с hub.docker.com
Официальная инструкция как задеплоить образ находится здесь https://hub.docker.com/r/clickhouse/clickhouse-server/.
Запускаем команду:
sudo docker pull clickhouse/clickhouse-server
Скачается официальный докер образ (но пока еще не запустится):
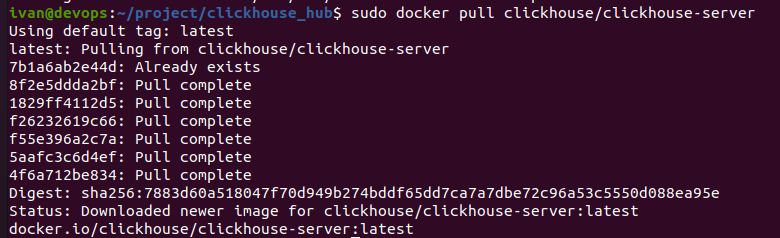
Далее необходимо запустить из образа контейнер:
sudo docker run -d --name some-clickhouse-server -p 8123:8123 --ulimit nofile=262144:262144 yandex/clickhouse-server
Чтобы проверить, что у Вас запустился контейнер с Clickhouse — запустите команду:
sudo docker ps
![]()
Проверить работу Clickhouse-server можно перейдя по url http://localhost:8123/:

Далее запускаем команду:
sudo docker run -it --rm --link some-clickhouse-server:clickhouse-server yandex/clickhouse-client --host clickhouse-server
С помощью этой команды мы подключимся к Clickhouse через native client:

Клиент командной строки
ClickHouse предоставляет собственный клиент командной строки: clickhouse-client. Клиент поддерживает запуск с аргументами командной строки и с конфигурационными файлами.
Клиент устанавливается пакетом clickhouse-client и запускается командой clickhouse-client.
Установка на Ubuntu:
sudo apt install clickhouse-client
Запуск клиента для подключения к локальной базе ClickHouse (localhost, default port 9000):
$ clickhouse-client ClickHouse client version 20.13.1.5273 (official build). Connecting to localhost:9000 as user default. Connected to ClickHouse server version 20.13.1 revision 54442. :)
Клиенты и серверы различных версий совместимы, однако если клиент старее сервера, то некоторые новые функции могут быть недоступны. Рекомендуется использовать одинаковые версии клиента и сервера.
Подключиться к удаленному серверу ClickHouse можно с помощью команды:
clickhouse-client -h 63.21.103.142 --port 9000 -u datauser --password ovOIhfl73Nfk21Jlv -d default
В результате должны получить ответ:
ClickHouse client version 18.16.1. Connecting to database default at 63.21.103.142:9000 as user datauser. Connected to ClickHouse server version 20.13.1 revision 54442.
Видео «Установка базы данных ClickHouse в виде контейнера Docker»
Установка ClickHouse с помощью docker-compose
Пример установки ClickHouse с помощью Docker Compose #1
Конфигурация ClickHouse в Docker Compose может выглядеть так:
version: '3'
services:
clickhouse:
image: yandex/clickhouse-server
restart: always
ports:
- "8123:8123" # HTTP-порт для запросов к ClickHouse
- "9000:9000" # Native-порт для запросов к ClickHouse
volumes:
- ./config.xml:/etc/clickhouse-server/config.d/config.xml # Файл конфигурации
environment:
- CLICKHOUSE_USER=<username> # Имя пользователя
- CLICKHOUSE_PASSWORD=<password> # Пароль пользователя
- CLICKHOUSE_CONFIG=/etc/clickhouse-server/config.d # Путь к файлам конфигурации
networks:
- clickhouse-network
networks:
clickhouse-network:
driver: bridge
ipam:
driver: default
config:
- subnet: 172.25.0.0/16 # Подсеть для контейнеров
В этом примере мы определяем контейнер ClickHouse, который будет доступен на портах 8123 и 9000 на хостовой машине. Мы также монтируем файл конфигурации config.xml, который может содержать пользовательские настройки и разрешения портов и IP.
Кроме того, мы определяем переменные среды CLICKHOUSE_USER и CLICKHOUSE_PASSWORD для настройки пользователя. Вы можете использовать эти переменные, чтобы задать имя пользователя и пароль для доступа к ClickHouse.
Мы также определяем сеть clickhouse-network, чтобы установить соединение между контейнерами. Как видите, мы указываем подсеть 172.25.0.0/16, которую можно изменить в соответствии с вашими потребностями.
Пример установки ClickHouse с помощью Docker Compose #2
Во втором примере мы определяем контейнер ClickHouse, который будет доступен на портах 8123 и 9000 на хостовой машине. Также я монтирую каталоги config.d и users.d, которые содержат файлы конфигурации и настроек пользователей соответственно:
version: '3'
services:
clickhouse:
image: yandex/clickhouse-server
restart: always
ports:
- "8123:8123" # HTTP-порт для запросов к ClickHouse
- "9000:9000" # Native-порт для запросов к ClickHouse
volumes:
- ./config.d:/etc/clickhouse-server/config.d # Файлы конфигурации
- ./users.d:/etc/clickhouse-server/users.d # Файлы настроек пользователей
environment:
- CLICKHOUSE_CONFIG=/etc/clickhouse-server/config.d # Путь к файлам конфигурации
networks:
- clickhouse-network
networks:
clickhouse-network:
driver: bridge
ipam:
driver: default
config:
- subnet: 172.25.0.0/16 # Подсеть для контейнеров
Пример файла config.d для ClickHouse, который можно использовать в качестве шаблона:
<?xml version="1.0"?>
<yandex>
<listen_host>::</listen_host>
<http_port>8123</http_port>
<tcp_port>9000</tcp_port>
<max_session_timeout>60</max_session_timeout>
<max_query_size>10485760</max_query_size>
<max_result_rows>100000</max_result_rows>
<max_execution_time>300</max_execution_time>
<max_memory_usage>10000000000</max_memory_usage>
<timezone>UTC</timezone>
<query_log>
<database>default</database>
<table>query_log</table>
</query_log>
<query_thread_log>
<database>default</database>
<table>query_thread_log</table>
</query_thread_log>
<compression>
<case>
<min_part_size>1000000000</min_part_size>
<method>lz4</method>
<use_for_all_types>true</use_for_all_types>
</case>
</compression>
<dictionaries_config>
<include_from>/etc/clickhouse-server/dicts/</include_from>
</dictionaries_config>
<users_config>
<include_from>/etc/clickhouse-server/users.d/</include_from>
</users_config>
</yandex>
Этот файл содержит настройки для ClickHouse, такие как порты для HTTP- и Native-протоколов, максимальное время выполнения запроса, максимальное количество строк в результате запроса и т.д.
Обратите внимание на элементы <compression> и <dictionaries_config>, которые позволяют задать настройки сжатия данных и словарей соответственно. Также в этом примере используется элемент <users_config>, который указывает ClickHouse на путь к файлам с настройками пользователей.
Это только пример файла конфигурации, и вы можете изменить его в соответствии с вашими потребностями и требованиями.
Также вы можете создать файлы настроек пользователей в каталоге users.d. Например, вы можете создать файл myuser.xml с таким содержимым:
<users>
<user>
<name>myuser</name>
<password>mypassword</password>
<profile>default</profile>
</user>
</users>
Теперь при запуске контейнера ClickHouse будут использоваться настройки из файлов в каталогах config.d и users.d
Подключаемся к ClickHouse с помощью DBeaver
Установить dbeaver в Ubuntu можно через Ubuntu Software:
Выбираем коннектор к Clickhouse:

Настройки подключения с дефолтным юзером:
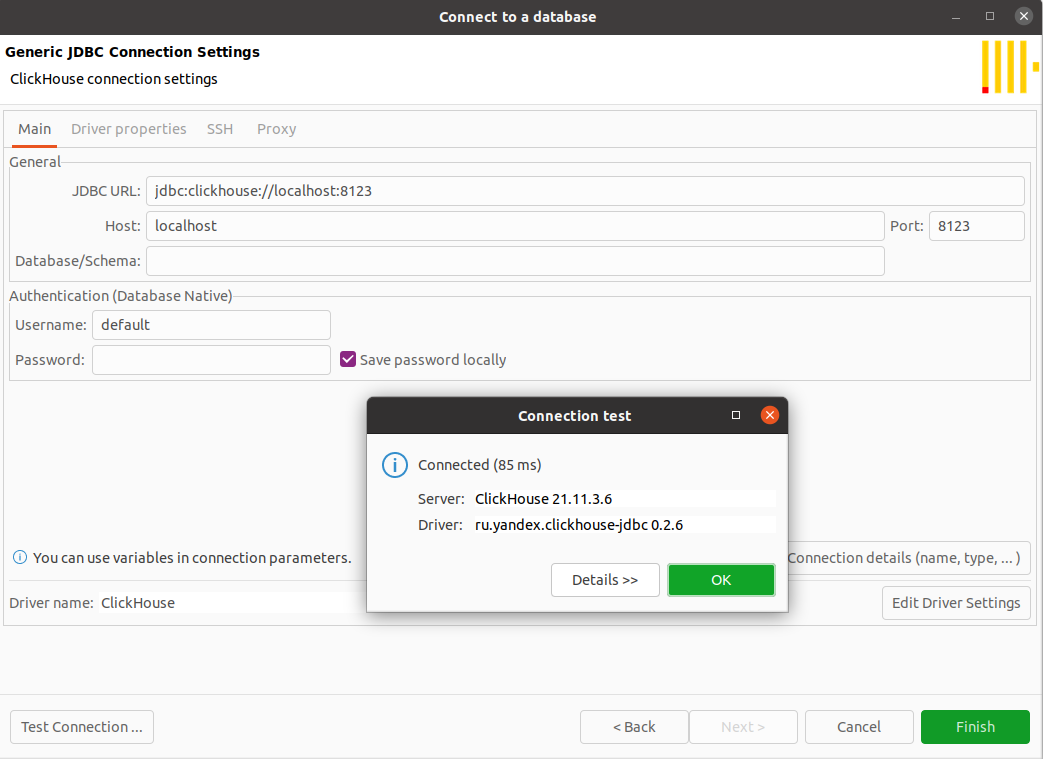
show databases — проверочный запрос к clickhouse:

Интерфейсы для доступа к Clickhouse
ClickHouse имеет богатый набор функций для управления сетевыми подключениями для клиентов, а также для других серверов в кластере. Тем не менее, новым пользователям может быть сложно проработать возможные варианты, а опытным пользователям может быть сложно обеспечить полный доступ к развернутым системам для приложений и их надлежащую защиту.
Следующий кусок взят из официальной документации раздела «Интерфейсы»:
ClickHouse предоставляет три сетевых интерфейса (они могут быть обернуты в TLS для дополнительной безопасности):
- HTTP, который задокументирован и прост для использования напрямую;
- Native TCP, который имеет меньше накладных расходов;
- gRPC.
В большинстве случаев рекомендуется использовать подходящий инструмент или библиотеку, а не напрямую взаимодействовать с ClickHouse. Официально поддерживаемые Яндексом:
Существует также широкий спектр сторонних библиотек для работы с ClickHouse:
Что такое http-интерфейс
HTTP интерфейс позволяет использовать ClickHouse на любой платформе, из любого языка программирования. HTTP интерфейс более ограничен по сравнению с родным интерфейсом, но является более совместимым. По умолчанию clickhouse-server слушает HTTP на порту 8123. Запрос отправляется в виде URL параметра с именем query. Или как тело запроса при использовании метода POST. Или начало запроса в URL параметре query, а продолжение POST-ом. Размер URL ограничен 16KB, это следует учитывать при отправке больших запросов.
Порт 8123 является конечной точкой интерфейса HTTP по умолчанию. Вы будете использовать этот порт, если используете команды curl для отправки запросов серверу. Кроме того, ряд библиотек, таких как JDBC-драйвер Yandex ClickHouse, скрытно используют HTTP-запросы, так что вы можете использовать http-интерфейс, даже не подозревая об этом.
Что такое Native TCP (Родной интерфейс)
Нативный протокол используется в клиенте командной строки, для взаимодействия между серверами во время обработки распределенных запросов, а также в других программах на C++. К сожалению, у родного протокола ClickHouse пока нет формальной спецификации.
Порт 9000 является конечной точкой Native TCP интерфейса (по-умолчанию). Он широко используется клиентами, как показано на следующих примерах.
- Clickhouse-client, стандартный клиент командной строки для ClickHouse, использует собственный протокол TCP/IP.
- Точно так же механизм ClickHouse Distributed использует собственный протокол TCP/IP для отправки подзапросов в базовые таблицы. В редких случаях он также используется реплицированными таблицами при отправке запросов ведущей реплике.
- Наконец, драйверы, такие как драйвер Python clickhouse или драйвер Golang, общаются с ClickHouse, используя собственный протокол TCP/IP.
Что такое gRPC
ClickHouse поддерживает интерфейс gRPC. Это система удаленного вызова процедур с открытым исходным кодом, которая использует HTTP/2 и Protocol Buffers.
gRPC — мощный фреймворк для работы с удаленными вызовами процедур. RPC позволяют писать код так, как если бы он был запущен на локальном компьютере, даже если он может выполняться на другом компьютере.
Как правило, gRPC считается лучшей альтернативой протоколу REST для микросервисной архитектуры. Букву g в gRPC можно отнести к компании Google, которая изначально разработала эту технологию. gRPC создан для преодоления ограничений REST в связи с микросервисами.
gRPC — это новейшая структура, созданная на основе протокола RPC. Он использует свои преимущества и пытается исправить проблемы традиционного RPC. gRPC использует буферы протокола в качестве языка определения интерфейса для сериализации и связи вместо JSON/XML.
Буферы протокола могут описывать структуру данных, и на основе этого описания может быть сгенерирован код для генерации или анализа потока байтов, представляющего структурированные данные. По этой причине gRPC предпочтительнее для многоязычных веб-приложений (реализованных с использованием различных технологий). Формат двоичных данных позволяет облегчить общение. gRPC также можно использовать с другими форматами данных, но предпочтительным является буфер протокола.
Кроме того, gRPC построен на основе HTTP/2, который поддерживает двунаправленную связь наряду с традиционным запросом/ответом. gRPC допускает слабую связь между сервером и клиентом. На практике клиент открывает долговременное соединение с сервером gRPC, и новый поток HTTP/2 открывается для каждого вызова RPC.
В отличие от REST, который использует JSON (в основном), gRPC использует буферы протокола, которые являются лучшим способом кодирования данных. Поскольку JSON — это текстовый формат, он будет намного тяжелее, чем сжатые данные в формате protobuf.
Network Listener Configuration
ClickHouse позволяет легко включать и отключать порты слушателей, а также назначать им новые номера. Для каждого типа порта существуют простые теги config.xml, как показано в следующей таблице. Столбец обычных значений показывает номер порта, который большинство клиентов предполагает для определенного соединения. Если вы измените значение, вам может потребоваться соответствующее изменение клиентов.
| Тег | Описание | Условное значение |
| http_port | Порт для незашифрованных HTTP-запросов | 8123 |
| https_port | Порт для зашифрованных запросов HTTPS | 8443 |
| interserver_http_port | Порт для незашифрованного трафика HTTP-репликации | 9009 |
| interserver_https_port | Порт для зашифрованного трафика репликации HTTPS | |
| tcp_port | Порт для незашифрованных собственных запросов TCP/IP | 9000 |
| tcp_port_secure | Порт для зашифрованных TLS собственных запросов TCP/IP | 9440 |
Как создать database в Clickhouse, таблицу и вставить тестовые данные
Идем в dbeaver и запускаем скрипты.
1. Создаем базу данных в Clickhouse
CREATE DATABASE db_superset ENGINE = Memory COMMENT 'The temporary database to test Clickhouse and Apache Superset';
2. Проверяем, что база данных создалась:
SELECT name, comment FROM system.databases WHERE name = 'db_superset';
3. Создаем таблицу в Clickhouse:
CREATE TABLE IF NOT EXISTS db_superset.facts ( id UInt32, product String, datetime DateTime, customer Nullable(String), amount Nullable(Float32) ) ENGINE = Log;
4. Вставляем первую строку данных:
INSERT INTO db_superset.facts (*) VALUES (1, 'product 1', '2021-10-01', 'Customer 1', 10);
5. Проверяем, что в Clickhouse данные вставились:
SELECT id, product, datetime, customer, amount
FROM db_superset.facts;
Далее попробуем вставить еще 1 строку с помощью разных вариантов.
Как подключиться к Clickhouse с помощью Python
Вариант 1 — clickhouse_connect
Другие примеры в официальном репозитории ClickHouse
https://github.com/ClickHouse/clickhouse-connect/tree/main/examples
#!/usr/bin/env python3 -u
import pandas as pd
import clickhouse_connect
create_table_sql = """
CREATE TABLE pandas_example
(
timeseries DateTime('UTC'),
int_value Int32,
str_value String,
float_value Float64
)
ENGINE = MergeTree
ORDER BY timeseries
"""
def write_pandas_df():
client = clickhouse_connect.get_client(host='localhost', port='8123', user='default', password= '')
client.command('DROP TABLE IF EXISTS pandas_example')
client.command(create_table_sql)
df = pd.DataFrame({'timeseries': ['04/03/2022 10:00:11', '05/03/2022 11:15:44', '06/03/2022 17:14:00'],
'int_value': [16, 19, 11],
'str_value': ['String One', 'String Two', 'A Third String'],
'float_value': [2344.288, -73002.4444, 3.14159]})
df['timeseries'] = pd.to_datetime(df['timeseries'])
client.insert_df('pandas_example', df)
result_df = client.query_df('SELECT * FROM pandas_example')
print()
print(result_df.dtypes)
print()
print(result_df)
if __name__ == '__main__':
write_pandas_df()
Вариант 2 — clickhouse-driver (Python Driver with native interface)
- https://github.com/mymarilyn/clickhouse-driver — ClickHouse Python Driver with native interface support
- Подробная документация по clickhouse-driver >>>
Установка:
pip install clickhouse-driver
Краткое описание: clickhouse-driver работает через 9000 порт, поэтому он должен быть открыт и должен быть настроен listener. По умолчанию 9000 порт в образе докера открыт, но может не настроен listener. Делается это через config файл для clickhouse server — по-умолчанию лежит тут etc/clickhouse-server/config.xml.
Пример запроса Show Databases:
from clickhouse_driver import Client
client = Client('63.123.91.237') #логин пароль порт по умолчанию, дефолтная БД тоже по умолчанию
result = client.execute("SHOW DATABASES")
print(result)
Пример Select запроса к ClickHouse
from clickhouse_driver import Client
client = Client('63.123.91.237') #логин пароль порт по умолчанию, дефолтная БД тоже по умолчанию
result = client.execute("SELECT * FROM db_superset.facts")
print(result)
Вставка 1 команды Insert через Execute
from clickhouse_driver import Client
import pandas as pd
client = Client('63.123.91.237')
client.execute("INSERT INTO db_superset.facts (*) VALUES (1, 'product 1', '2021-10-01', 'Customer 1', 10)")
Вставка dataframe pandas в ClickHouse
Подробности по настройкам можно почитать в документации в разделе NumPy/Pandas support >>>
from clickhouse_driver import Client
import pandas as pd
client = Client('63.123.91.237', settings={'use_numpy': True})
# Creating Dataframe
df = pd.DataFrame([
[152, 'product 152', '2021-10-04', 'Customer 1', 4],
[153, 'product 153', '2021-10-06', 'Customer 1', 5],
[154, 'product 154', '2021-10-07', 'Customer 1', 7]
],
columns =['id', 'product', 'datetime', 'customer', 'amount'])
print(df)
client.insert_dataframe(f'INSERT INTO db_superset.facts VALUES', df)
Еще 1 пример вставки данных в ClickHouse с помощью библиотеки clickhouse-driver
from clickhouse_driver import Client
# Создаем клиент для подключения к ClickHouse
client = Client(host='localhost', port=9000)
# Создаем таблицу в ClickHouse, если она еще не существует
client.execute('CREATE TABLE IF NOT EXISTS my_table (column1 Int32, column2 String, column3 Float64, column4 Date, column5 DateTime, column6 Array(Int32), column7 Tuple(String, Int32), column8 UInt64, column9 Decimal(18,2), column10 Nullable(String)) ENGINE = MergeTree() ORDER BY (column1)')
# Генерируем данные для таблицы (это просто пример, можно использовать свои данные)
data = [(1, 'row1', 1.0, '2022-01-01', '2022-01-01 00:00:01', [1, 2, 3], ('value', 10), 100, 10.5, 'value1'),
(2, 'row2', 2.0, '2022-01-02', '2022-01-02 00:00:02', [4, 5, 6], ('value', 20), 200, 20.5, 'value2'),
(3, 'row3', 3.0, '2022-01-03', '2022-01-03 00:00:03', [7, 8, 9], ('value', 30), 300, 30.5, None)]
# Вставляем данные в таблицу
client.execute('INSERT INTO my_table (column1, column2, column3, column4, column5, column6, column7, column8, column9, column10) VALUES', data)
Вариант 3 — sqlalchemy-clickhouse (ClickHouse dialect for SQLAlchemy)
https://github.com/cloudflare/sqlalchemy-clickhouse — этот коннектор рекомендуется для использования в superset. Строка подключения выглядит как:
clickhouse+native://<user>:<password>@<host>:<port>/<database>[?options…]clickhouse://{username}:{password}@{hostname}:{port}/{database}
Установка:
pip install sqlalchemy-clickhouse
Пример Select запроса
Пример полного скрипта Python для получения данных из ClickHouse:
from sqlalchemy import create_engine
import pandas as pd
engine = create_engine('clickhouse://your_clickhouse_user:your_clickhouse_password@your_clickhouse_host:your_clickhouse_port/your_clickhouse_database')
query = 'SELECT * FROM your_table'
df = pd.read_sql(query, engine)
print(df.head())
Вставка данных в ClickHouse с помощью библиотеки sqlalchemy-clickhouse
Создадим таблицу, если ее еще не существует, используя функцию execute:
create_table_query = ''' CREATE TABLE IF NOT EXISTS your_table ( id UInt64, name String ) ENGINE = MergeTree() ORDER BY id ''' engine.execute(create_table_query)
Пример полного скрипта Python для вставки данных в ClickHouse:
from sqlalchemy import create_engine
import pandas as pd
engine = create_engine('clickhouse://your_clickhouse_user:your_clickhouse_password@your_clickhouse_host:your_clickhouse_port/your_clickhouse_database')
create_table_query = '''
CREATE TABLE IF NOT EXISTS your_table (
id UInt64,
name String
) ENGINE = MergeTree()
ORDER BY id
'''
engine.execute(create_table_query)
data = {'id': [1, 2, 3], 'name': ['John', 'Jane', 'Bob']}
df = pd.DataFrame(data)
table_name = 'your_table'
df.to_sql(table_name, engine, if_exists='append', index=False)
Вариант 4 — pandahouse (Pandas interface for Clickhouse database)
Github проект Pandahouse — https://github.com/kszucs/pandahouse
Установка:
pip install pandahouse
Пример Select запроса
Для того чтобы получить данные из ClickHouse с помощью библиотеки pandahouse в Python, необходимо выполнить следующие шаги:
-
Установить библиотеку pandahouse с помощью pip:
pip install pandahouse -
Импортировать библиотеку и создать соединение с базой данных ClickHouse:
import pandahouse as ph
connection = {'host': 'your_clickhouse_host',
'database': 'your_clickhouse_database',
'user': 'your_clickhouse_user',
'password': 'your_clickhouse_password'}
- Выполнить запрос SELECT с помощью функции
read_clickhouseи сохранить результат в объект DataFrame:
query = 'SELECT * FROM your_table' df = ph.read_clickhouse(query, connection=connection)
Пример полного скрипта Python для получения данных из ClickHouse:
import pandahouse as ph
connection = {'host': 'your_clickhouse_host',
'database': 'your_clickhouse_database',
'user': 'your_clickhouse_user',
'password': 'your_clickhouse_password'}
query = 'SELECT * FROM your_table'
df = ph.read_clickhouse(query, connection=connection)
print(df.head())
Пример вставки данных в ClickHouse с помощью pandahouse
import pandahouse as ph
import pandas as pd
connection = {'host': 'your_clickhouse_host',
'database': 'your_clickhouse_database',
'user': 'your_clickhouse_user',
'password': 'your_clickhouse_password'}
df = pd.DataFrame({'column1': [1, 2, 3], 'column2': ['a', 'b', 'c']})
table_name = 'your_table'
ph.to_clickhouse(df, table_name, connection=connection, index=False, if_exists='append')
Как создать таблицу в Clickhouse и записать данные с помощью Python
Условие:
Как создать таблицу в Clickhouse и записать 1 миллион строк данных с помощью Python. Нужно использовать библиотеку Pandas. Данные необходимо отправлять пакетно по 50 тысяч строк.
from clickhouse_driver import Client
import pandas as pd
# Создаем клиент для подключения к ClickHouse
client = Client(host='localhost', port=9000)
# Определяем схему таблицы
schema = {
'id': 'Int32',
'name': 'String',
'value': 'Float64'
}
# Создаем пустой DataFrame
df = pd.DataFrame(columns=schema.keys())
# Генерируем данные для таблицы и добавляем их в DataFrame
for i in range(1000000):
row = {
'id': i,
'name': f'row{i}',
'value': i * 0.1
}
df = df.append(row, ignore_index=True)
# Создаем таблицу в ClickHouse
client.execute('CREATE TABLE IF NOT EXISTS my_table (id Int32, name String, value Float64) ENGINE = MergeTree() ORDER BY (id)')
# Отправляем данные по пакетам по 50 тысяч строк
batch_size = 50000
num_batches = len(df) // batch_size + 1
for i in range(num_batches):
start = i * batch_size
end = (i + 1) * batch_size
batch = df[start:end]
data = [tuple(row) for _, row in batch.iterrows()]
client.execute('INSERT INTO my_table (id, name, value) VALUES', data)
В этом примере мы создаем клиент для подключения к ClickHouse, определяем схему таблицы и создаем пустой DataFrame для хранения данных. Затем мы генерируем 1 миллион строк данных и добавляем их в DataFrame.
Мы создаем таблицу my_table в ClickHouse и отправляем данные пакетно по 50 тысяч строк с помощью цикла и команды INSERT INTO.
Обратите внимание на использование метода iterrows() для преобразования DataFrame в список кортежей, который может быть отправлен в ClickHouse.
Также важно установить правильный порядок сортировки в таблице при её создании, чтобы данные были хранились в правильном порядке и можно было использовать индекс.
Пример скрипта динамической вставки данных в ClickHouse
from clickhouse_driver import Client
import pandas as pd
# Создаем клиент для подключения к ClickHouse
client = Client(host='localhost', port=9000)
# Загружаем данные в Pandas
df = pd.read_csv('my_data.csv')
# Определяем столбцы и их типы в соответствии с DataFrame
columns = df.columns
dtypes = df.dtypes
schema = ','.join([f'{col} {dtype.name}' for col, dtype in zip(columns, dtypes)])
# Создаем таблицу в ClickHouse
client.execute(f'CREATE TABLE IF NOT EXISTS my_table ({schema}) ENGINE = MergeTree() ORDER BY (id)')
# Отправляем данные по пакетам по 100 тысяч строк
batch_size = 100000
num_batches = len(df) // batch_size + 1
for i in range(num_batches):
start = i * batch_size
end = (i + 1) * batch_size
batch = df.iloc[start:end]
data = [tuple(row) for _, row in batch.iterrows()]
client.execute(f'INSERT INTO my_table ({",".join(columns)}) VALUES', data)
В этом примере мы загружаем данные из CSV-файла в Pandas, определяем столбцы и их типы в соответствии с DataFrame и создаем таблицу my_table в ClickHouse.
Затем мы отправляем данные пакетно по 100 тысяч строк с помощью цикла и команды INSERT INTO.
Как получить данные из таблицы Clickhouse в Python
Пример #1
from clickhouse_driver import Client
import pandas as pd
# Создаем клиент для подключения к ClickHouse
client = Client(host='localhost', port=9000)
# Выполняем запрос и получаем результаты
query = 'SELECT * FROM my_table'
result = client.execute(query)
# Вставляем результаты в DataFrame
df = pd.DataFrame(result, columns=[col[0] for col in client.execute('DESCRIBE my_table')])
# Выводим первые 5 строк DataFrame
print(df.head())
В этом примере мы создаем клиент для подключения к ClickHouse, выполняем запрос SELECT * FROM my_table и получаем результаты с помощью метода execute() клиента. Затем мы создаем DataFrame из результатов с помощью конструктора pd.DataFrame() и задаем имена столбцов DataFrame с помощью команды DESCRIBE my_table. После этого мы можем использовать полученный DataFrame для дальнейшей обработки данных.
Обратите внимание, что результаты запроса представляют собой список кортежей. Каждый кортеж представляет собой одну строку данных из таблицы ClickHouse. Мы преобразовали этот список в DataFrame с помощью конструктора pd.DataFrame(), передав ему список кортежей и список имен столбцов.

