
Contents
- 1 Что такое Apache Airflow?
- 2 Архитектура Apache Airflow
- 2.1 Обзор интерфейса Apache Airflow
- 2.2 Обзор основных сущностей Apache Airflow
- 2.3 Обзор компонентов Apache Airflow
- 3 Установка и настройка Apache Airflow
- 4 FAQ: Вопросы и ответы
- 4.1 Как переиспользовать функции Python между разными DAG? Как переиспользовать код в нескольких DAG?
- 4.2 Что такое модуль в Airflow? Как создать и подключить свой модуль в Airflow?
- 4.3 Как импортировать модули в Airflow, если Airflow развернут в контейнерах Docker?
- 4.4 Какие сложности часто возникают при работе в Airflow?
- 4.5 Как выполнить 2 задачи из одного DAG в разных контейнерах Docker?
- 4.6 Пример DAG отправки сообщения в Slack
- 4.7 Пример DAG с отправкой отчета Excel из Pandas Dataframe в канал Slack
- 4.8 Как указать в dag асинхронно или последовательно выполнять задачи? Пример асинхронного и последовательного dag
- 4.9 Отправка красивого письма с вложенным файлом excel через dag airflow
- 4.10 Как продать идею внедрения airflow руководству?
- 4.11 Как создать цепочку задач для выполнения etl в Apache PySpark
- 4.12 Как создать несколько задач и дождаться их выполнения в Apache Airflow
- 4.13 В чем разница между Apache NiFi vs Airflow?
- 4.14 Data Pipelines (пайплайны) внутри DAG. Пайплайн airflow
- 5 Подборка видео по тематике Airflow
- 5.1 Видео на русском
- 5.1.1 Что такое Apache Airflow («Школы Больших Данных» г. Москва)
- 5.1.2 Начало работы с apache Airflow — часть 1 («Школы Больших Данных» г. Москва)
- 5.1.3 ETL на airflow — часть 2 («Школы Больших Данных» г. Москва)
- 5.1.4 5 Оркестраторы и работа с Airflow (Канал Intellik)
- 5.1.5 ВВЕДЕНИЕ В AIRFLOW / ПОНЯТИЕ DAG’а / НАСТРОЙКА DAG’а В AIRFLOW (Канал DataLearn)
- 5.1.6 Airflow и MLFlow автоматизаций пайплайнов Machine Learning / MLOps (Канал miracl6)
- 5.2 Видео на английском
- 5.1 Видео на русском
Что такое Apache Airflow?
Apache Airflow — это платформа управления рабочими процессами обработки данных с открытым исходным кодом (фактически это инструмент для построения конвейеров обработки данных, либо оркестратор, который позволяет запускать процессы в сторонней системе). Он был запущен в Airbnb в октябре 2014 года (автор Maxime Beauchemin), как решение для управления все более сложными workflow компании. Создание Airflow позволило Airbnb программно создавать и планировать свои рабочие процессы и отслеживать их через встроенный пользовательский интерфейс Airflow. С самого начала исходный код проекта был открыт, в марте 2016 года он стал проектом Apache Incubator, а в январе 2019 года — проектом верхнего уровня Apache Software Foundation.
Airflow написан на Python, а рабочие процессы создаются с помощью скриптов Python. Apache Airflow спроектирован по принципу «конфигурация как код». В то время как существуют другие платформы рабочих процессов «конфигурация как код», использующие языки разметки, такие как XML, использование Python позволяет разработчикам импортировать библиотеки и классы.
Краткое описание функционала и предназначения
Apache Airflow — это планировщик задач, используемый для планирования, создания и отслеживания процессов. Он выходит за рамки управления надежным оркестратором данных.
Airflow — это фреймворк для оркестровки.
Что именно он может сделать?
- Запуск заданий ETL/ELT (например python скриптов)
- Обучение моделей машинного обучения
- Работа Airflow как Track system
- Создание рабочих процессов через DAGs
- Управление расписанием задач, в том числе во внешних системах (например, запуск задач в QMC QlikView/Qlik Sense)
- Настройка зависимостей событий/задач/рабочих процессов
- Управление программным рабочим процессом
- Airflow можно использовать для создания отчетов
- Резервное копирование и другие задачи DevOps
Однако важно помнить, что Apache Airflow не обрабатывает потоковые рабочие процессы в реальном времени.
В версии Airflow 2.0+ были сделаны улучшения:
- Горизонтальная масштабируемость. Если нагрузка задач на один планировщик увеличивается, пользователь теперь может запускать дополнительные «реплики» планировщика, чтобы увеличить пропускную способность своего развертывания воздушного потока.
- Уменьшена задержка выполнения задачи. В Airflow 2.0 даже один планировщик позволяет планировать задачи с гораздо большей скоростью при том же уровне загрузки ЦП и памяти.
- В Airflow 2.0 представлен новый комплексный REST API, который заложил прочную основу для нового пользовательского интерфейса и командной строки Airflow в будущем.
Плюсы Apache Airflow
- Открытый исходный код. AirFlow активно поддерживается сообществом и имеет хорошо описанную документацию.
- На основе Python. Python считается относительно простым языком для освоения и общепризнанным стандартом для специалистов в области Big Data и Data Science.
- Когда ETL-процессы определены как код, они становятся более удобными для разработки, тестирования и сопровождения. Также устраняется необходимость использовать JSON- или XML-конфигурационные файлы для описания пайплайнов.
- Богатый инструментарий и дружественный UI. Работа с AirFlow возможна при помощи CLI, REST API и веб-интерфейса, построенного на основе Python-фреймворка Flask.
- Интеграция со множеством источников данных и сервисов. AirFlow поддерживает множество баз данных и Big Data-хранилищ: MySQL, PostgreSQL, MongoDB, Redis, Apache Hive, Apache Spark, Apache Hadoop, объектное хранилище S3 и другие.
- Кастомизация. Есть возможность настройки собственных операторов.
- Масштабируемость. Допускается неограниченное число DAG за счет модульной архитектуры и очереди сообщений. Worker могут масштабироваться при использовании Celery или Kubernetes.
- Мониторинг и алертинг. Поддерживается интеграция с Statsd и FluentD — для сбора и отправки метрик и логов. Также доступен Airflow-exporter для интеграции с Prometheus.
- Возможность настройки ролевого доступа. По умолчанию AirFlow предоставляет 5 ролей с различными уровнями доступа: Admin, Public, Viewer, Op, User. Также допускается создание собственных ролей с доступом к ограниченному числу DAG.
- Дополнительно возможна интеграция с Active Directory и гибкая настройка доступов с помощью RBAC (Role-Based Access Control).
- Поддержка тестирования. Можно добавить базовые Unit-тесты, которые будут проверять как пайплайны в целом, так и конкретные задачи в них.
Минусы Apache Airflow
- При проектировании задач важно соблюдать идемпотентность: задачи должны быть написаны так, чтобы независимо от количества их запусков, для одних и тех же входных параметров возвращался одинаковый результат.
- Необходимо разобраться в механизмах обработки execution_date. Важно понимать, что корректировки кода задач будут отражаться на всех их запусках за предыдущее время. Это исключает воспроизводимость результатов, но, с другой стороны, позволяет получить результаты работы новых алгоритмов за прошлые периоды.
- Нет возможности спроектировать DAG в графическом виде, как это, например, доступно в Apache NiFi. Многие видят в этом, напротив, плюс, так как ревью кода проводится легче, чем ревью схем.
- Высокая кривая обучения: Поскольку у Apache Airflow крутая кривая обучения, пользователям, особенно новичкам, может быть сложно адаптироваться к среде и выполнять такие задачи, как написание тестовых примеров для конвейеров данных, обрабатывающих необработанные данные.
- Документация по Airflow сносная, но не очень хорошая, и трудно понять, каковы лучшие практики, когда вы начинаете, потому что существует так много разных способов сделать что-то, и большинство примеров, которые вы найдете, слишком упрощены.
- Проблемы с переименованием: каждый раз, когда вы изменяете интервалы расписания, Apache Airflow просит вас переименовать ваши DAG, чтобы гарантировать, что ваши предыдущие экземпляры задач соответствуют новому периоду времени.
- Удаляет метаданные: поскольку в конвейерах данных Apache Airflow отсутствует система контроля версий, если вы удаляете задание из своего кода DAG, а затем повторно развертываете его, все метаданные, связанные с транзакцией, автоматически удаляются.
Примеры за и против из книги Apache Airflow и конвейеры обработки данных
Причины выбрать Airflow
В этом разделе будут описаны ключевые функции, которые делают Airflow идеальным вариантом для реализации конвейеров пакетной обработки данных.
- возможность реализовывать конвейеры с использованием кода на языке Python позволяет создавать сколь угодно сложные конвейеры, используя все, что только можно придумать в Python;
- язык Python, на котором написан Airflow, позволяет легко расширять и добавлять интеграции со многими различными системами. Сообщество Airflow уже разработало богатую коллекцию расширений, которые дают возможность Airflow интегрироваться в множество различных типов баз данных, облачных сервисов и т.д.;
- обширная семантика планирования позволяет запускать конвейеры через равные промежутки времени и создавать эффективные конвейеры, использующие инкрементную обработку, чтобы избежать дорогостоящего пересчета существующих результатов;
- такие функции, как backfilling (обратное заполнение), дают возможность с легкостью (повторно) обрабатывать исторические данные, позволяя повторно вычислять любые производные наборы данных после внесения изменений в код;
- многофункциональный веб-интерфейс Airflow обеспечивает удобный просмотр результатов работы конвейера и отладки любых сбоев, которые могут произойти.
Дополнительное преимущество Airflow состоит в том, что это фреймворк с открытым исходным кодом. Это гарантирует, что вы можете использовать Airflow для своей работы без какой-либо привязки к поставщику. У некоторых компаний также есть управляемые решения (если вам нужна техническая поддержка), что дает больше гибкости относительно того, как вы запускаете и управляете своей установкой Airflow.
Причины не выбирать Airflow
Хотя у Airflow имеется множество мощных функций, в определенных случаях это, возможно, не то, что вам нужно. Вот некоторые примеры, когда Airflow – не самый подходящий вариант:
- обработка потоковых конвейеров, поскольку Airflow в первую очередь предназначен для выполнения повторяющихся или задач по пакетной обработке данных, а не потоковых рабочих нагрузок;
- реализация высокодинамичных конвейеров, в которых задачи добавляются или удаляются между каждым запуском конвейера. Хотя Airflow может реализовать такое динамическое поведение, веб-интерфейс будет показывать только те задачи, которые все еще определены в самой последней версии DAG. Таким образом, Airflow отдает предпочтение конвейерам, структура которых не меняется каждый раз при запуске;
- команды с небольшим опытом программирования (Python) или вообще не имеющие его, поскольку реализация DAG в Python может быть сложной задачей для тех, у кого малый опыт работы с Python. В таких командах использование диспетчера рабочих процессов с графическим интерфейсом (например, Azure Data Factory) или определение статического рабочего процесса, возможно, имеет больше смысла;
- точно так же код Python в DAG может быстро стать сложным в более масштабных кейсах. Таким образом, внедрение и поддержка DAG в Airflow требуют должной строгости, чтобы поддерживать возможность сопровождения в долгосрочной перспективе.
Кроме того, Airflow – это в первую очередь платформа для управления рабочими процессами и конвейерами, и (в настоящее время) она не включает в себя более обширные функции, такие как data lineages, управление версиями данных и т.д. Если вам потребуются эти функции, то вам, вероятно, придется рассмотреть возможность объединения Airflow с другими специализированными инструментами, которые предоставляют эти функции.
Конкуренты Apache Airflow
Luigi
Luigi — это пакет Python, который выполняет длительную пакетную обработку. Это означает, что он управляет автоматическим выполнением процессов обработки данных для нескольких объектов в пакете. Задание обработки данных можно определить как серию зависимых задач в Luigi. Луиджи выясняет, какие задачи ему нужно выполнить, чтобы завершить задачу. Он обеспечивает основу для создания конвейеров обработки данных и управления ими в целом. Он был создан Spotify , чтобы помочь им управлять группами заданий, требующих извлечения и обработки данных из ряда источников.
Apache NiFi
Apache NiFi — это бесплатное приложение с открытым исходным кодом , которое автоматизирует передачу данных между системами. Приложение поставляется с пользовательским веб-интерфейсом для управления масштабируемыми ориентированными графами маршрутизации данных, преобразования и логики посредничества системы. Это сложная и надежная система обработки и распространения данных. Для редактирования данных во время выполнения он предоставляет очень гибкий и адаптируемый метод потока данных.
Dagster
Dagster — это машинное обучение , аналитика и оркестратор данных ETL . Поскольку он выполняет основную функцию планирования, эффективного упорядочивания и мониторинга вычислений, Dagster можно использовать в качестве альтернативы или замены для Airflow (и других классических механизмов рабочего процесса). Однако он выходит за рамки обычного определения оркестратора, заново изобретая весь сквозной процесс разработки и развертывания приложений для работы с данными.
Kedro
Kedro — это платформа Python с открытым исходным кодом для написания повторяемого, управляемого и модульного кода Data Science. Модульность, разделение задач и управление версиями относятся к числу идей, заимствованных из лучших практик разработки программного обеспечения и применяемых к алгоритмам машинного обучения.
Apache Oozie
Одним из сервисов/приложений планировщика рабочих процессов, работающих в кластере Hadoop, является Apache Oozie . Он используется для обработки задач Hadoop, таких как Hive, Sqoop, SQL, MapReduce и операций HDFS, таких как distcp. Это система, которая управляет рабочим процессом работ, которые зависят друг от друга. Здесь пользователи могут создавать направленные ациклические графы процессов, которые могут выполняться в Hadoop параллельно или последовательно.
Apache Oozie также вполне адаптируется . Задания можно просто запускать, останавливать, приостанавливать и перезапускать. Повторный запуск сбойных процессов с Oozie очень прост. Можно даже полностью обойти отказавший узел.
Таблица с характеристиками конкурентов (не всех вышеперечисленных)

Архитектура Apache Airflow
Обзор интерфейса Apache Airflow
Airflow поставляется с пользовательским интерфейсом, который позволяет вам видеть, что делают DAG и их задачи, запускать задачи DAG, просматривать журналы и выполнять некоторую ограниченную отладку и решение проблем с вашими DAG.
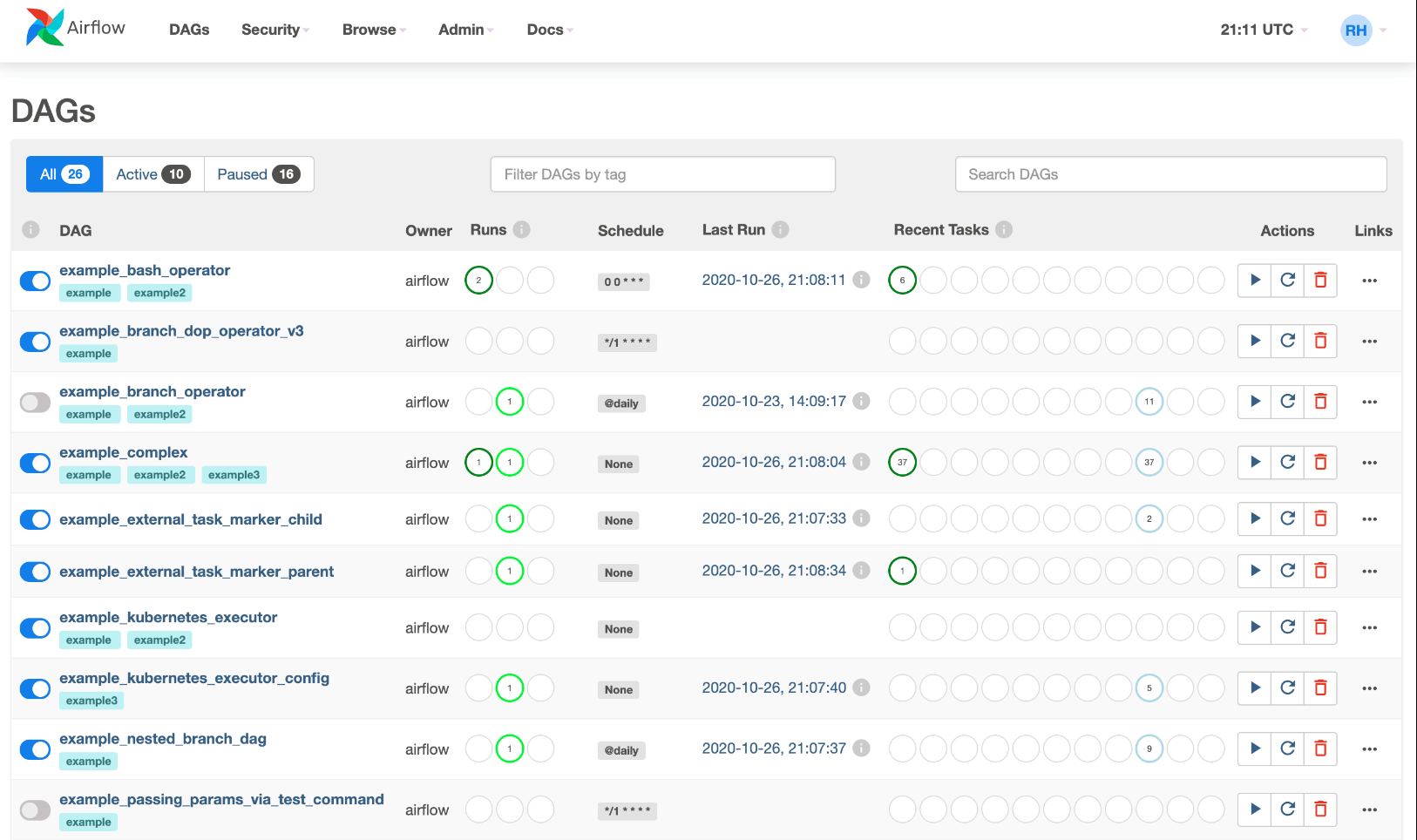
Краткий обзор меню Apache Airflow
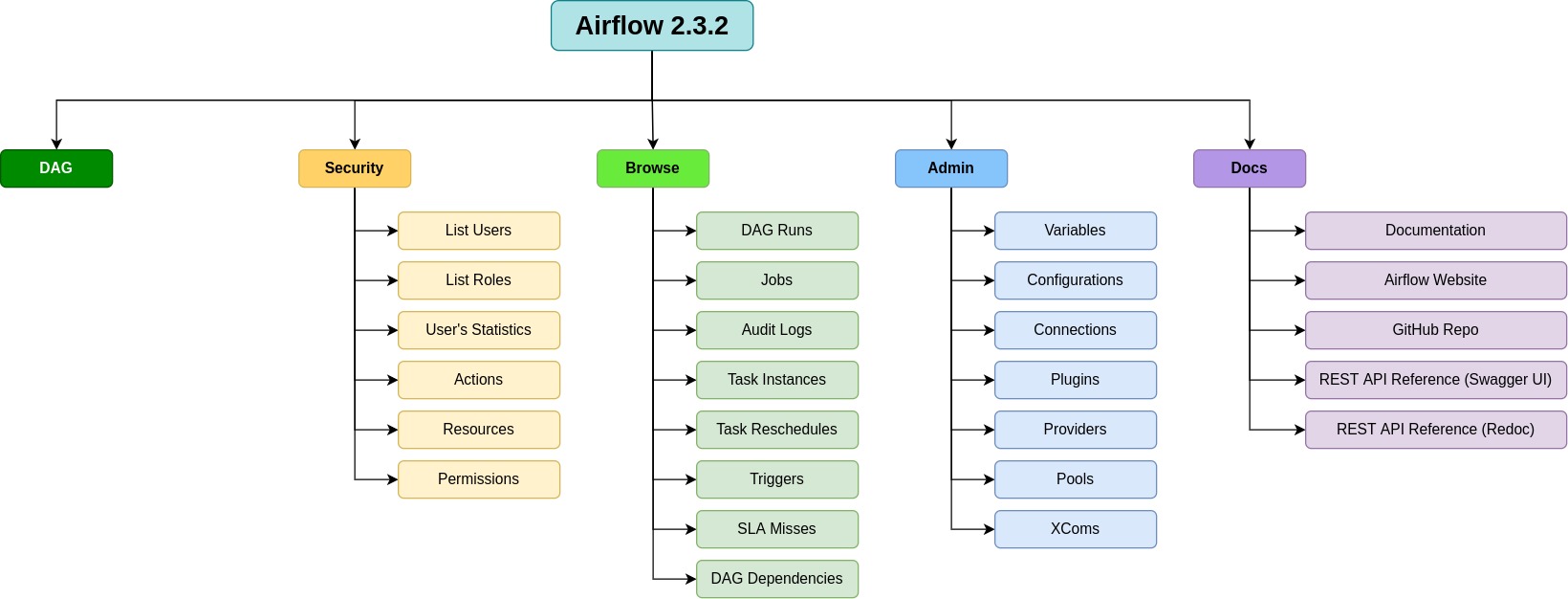
Меню Apache Airflow версии 2.5 содержит следующие пункты:
- DAGs — Это пункт меню, который открывает страницу управления DAGs (Directed Acyclic Graphs) или графов, которые представляют собой структуру циклических зависимостей между задачами.
- Admin — Этот пункт меню содержит инструменты для управления пользовательскими учетными записями, настройками соединений, конфигурацией и мониторингом системы.
- Variables — Этот пункт меню позволяет задавать переменные, используемые в DAG-ах или задачах.
- Connections — Этот пункт меню обеспечивает доступ к настройкам соединений с внешними системами, такими как базы данных, хранилища данных и т. д.
- Plugins — Этот пункт меню предоставляет доступ к различным плагинам, которые могут использоваться в DAG-ах.
- Code — Этот пункт меню открывает страницу, на которой можно просмотреть и редактировать Python-код, используемый в DAG-ах или задачах.
- Docs — Этот пункт меню содержит документацию по Apache Airflow и различным инструментам, которые используются в системе.
- About — Этот пункт меню предоставляет информацию о версии Apache Airflow и разработчиках системы.
Эти пункты меню представляют собой основные инструменты для управления и настройки Apache Airflow версии 2, которые помогают пользователям создавать, отслеживать и управлять рабочими процессами и задачами.
Обзор основных сущностей Apache Airflow
- Процессы обработки данных, или пайплайны, в Airflow описываются при помощи DAG (Directed Acyclic Graph). DAG — это сущность, объединяющая ваши задачи в цепочку задач, в которой явно видны зависимости между узлами.
- В качестве узлов DAG выступают задачи (Task) — операции, применяемые к данным.
- За реализацию задач отвечают операторы (Operator) — это шаблоны для выполнения задач.
- Особую группу операторов составляют сенсоры (Sensor), позволяющие создавать триггер на событие.
- Существует возможность добавления пользовательского оператора через расширение базового класса BaseOperator.
- Hooks (Хуки) — это внешние интерфейсы для работы с различными сервисами: базы данных, внешние API ресурсы, распределенные хранилища типа S3, redis, memcached и т.д. Hooks являются строительными блоками операторов и берут на себя всю логику по взаимодействию с хранилищем конфигов и доступов.
- XCom (кросс-коммуникация) обеспечивает способ обмена сообщениями или данными между различными задачами (или между операторами). Xcom по своей сути представляет собой таблицу, в которой хранятся пары ключ-значение, а также отслеживаются, какая пара была предоставлена какой задачей и dag.
Перечень операторов
В Apache Airflow есть множество операторов, которые позволяют запускать различные задачи. Ниже приведены некоторые из них:
| Оператор | Назначение оператора (что делает Airflow Operator)? |
| Python Operator | Исполнение Python-кода |
| BranchPythonOperator | Выполняет функцию Python и в зависимости от результата переходит к определенной ветке |
| BashOperator | Запуск Bash-скриптов |
| SimpleHttpOperator | Отправка HTTP-запросов |
| MySqlOperator | Отправка SQL-запросов к базе данных MySQL |
| PostgresOperator | Отправка SQL-запросов к базе данных PostgreSQL |
| S3FileTransformOperator | Загрузка данных из S3 во временную директорию в локальной файловой системе, преобразование согласно указанному сценарию и сохранение результатов обработки в S3 |
| DockerOperator | Запуск Docker-контейнера под выполнение задачи |
| KubernetesPodOperator | Создание отдельного Pod под выполнение задачи. Используется совместно с K8s |
| SqlSensor | Проверка выполнения SQL-запроса |
| SlackAPIOperator | Отправка сообщений в Slack |
| EmailOperator | Отправка электронных писем |
| DummyOperator | «Пустой» оператор, который можно использовать для группировки задач (ничего не делает) |
| SubDagOperator | запускает поддаг |
| TriggerDagRunOperator | запускает другой DAG |
| SQLOperator | выполняет SQL-запрос в базе данных |
| TimeDeltaSensor | ждет определенный промежуток времени, прежде чем продолжить выполнение DAG |
| ExternalTaskSensor | ждет, пока другой DAG не завершится, прежде чем продолжить выполнение текущего DAG |
| FileSensor | ждет, пока файл не появится в определенном месте, прежде чем продолжить выполнение DAG |
| HttpSensor | ждет, пока HTTP-запрос не вернет определенный статус код, прежде чем продолжить выполнение DAG |
Описание основных параметров PythonOperator
task_id: уникальный идентификатор задачи в DAGpython_callable: функция Python, которая будет вызываться при выполнении задачиop_args: список аргументов, передаваемых в функциюpython_callableop_kwargs: словарь именованных аргументов, передаваемых в функциюpython_callableprovide_context: если установлено в True, то в функциюpython_callableбудут передаваться контекстные переменные Airflow (например, дата выполнения задачи)dag: объект DAG, к которому принадлежит задача
DAG (Directed Acyclic Graph)
DAG (Направленный ациклический граф) — это основная концепция Airflow, объединяющая задачи вместе, организованная через настроенные зависимости и отношения, которые определяют как должна отработать цепочка задач (или data pipeline). Задачи, входящие в состав DAG, в Apache Airflow называются операторами(Operator).
Классическая схема DAG:
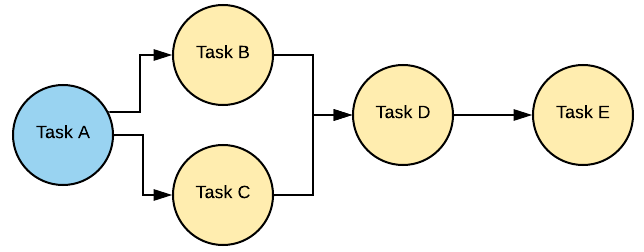
Пример DAG показан на диаграмме
Что такое subdag в airflow? Основные подходы к использованию
SubDAG в Apache Airflow — это специальный тип DAG, который может быть включен в другой DAG в качестве поддага. Он позволяет создавать более сложные DAG, разбивая их на более мелкие и управляемые единицы.
Основные подходы к использованию SubDAG в Apache Airflow:
- Разбиение больших задач на более мелкие: SubDAG позволяет разбить сложную задачу на более мелкие и управляемые единицы, что упрощает управление и отслеживание выполнения задач.
- Повторное использование кода: SubDAG можно использовать несколько раз в разных DAG, что позволяет повторно использовать код и сокращает время разработки.
- Улучшение читаемости и понимания DAG: SubDAG позволяет разбить большой DAG на более мелкие и понятные единицы, что улучшает читаемость и понимание кода.
- Управление зависимостями: SubDAG может быть использован для управления зависимостями между задачами в DAG, что позволяет легче контролировать порядок выполнения задач.
- Управление ресурсами: SubDAG может быть использован для управления ресурсами, такими как CPU и память, что позволяет более эффективно использовать ресурсы и ускорить выполнение задач.
Tasks и Task Instances (Экземпляр задачи)
Любой экземпляр оператора называется задачей. Каждая задача представлена как узел в DAG.
Экземпляр задачи — это запуск задачи. В то время как мы определяем задачи в DAG, запуск DAG создается при выполнении DAG, он содержит идентификатор dag и дату выполнения DAG для идентификации каждого уникального запуска. Каждый запуск DAG состоит из нескольких задач, и каждый запуск этих задач называется экземпляром задачи.
Экземпляр задачи проходит через несколько состояний при запуске. Обычно поток состоит из следующих этапов:
- No status (scheduler created empty task instance) — Нет статуса (планировщик создал пустой экземпляр задачи)
- Scheduled (scheduler determined task instance needs to run) — Запланировано (необходим запуск определенного планировщиком экземпляра задачи)
- Queued (scheduler sent the task to the queue – to be run) — В очереди (планировщик отправил задачу в очередь для выполнения)
- Running (worker picked up a task and is now executing it) — Выполняется (работник взял задачу и теперь выполняет ее)
- Success (task completed) — Успех (задача выполнена)
Жизненный цикл задачи:
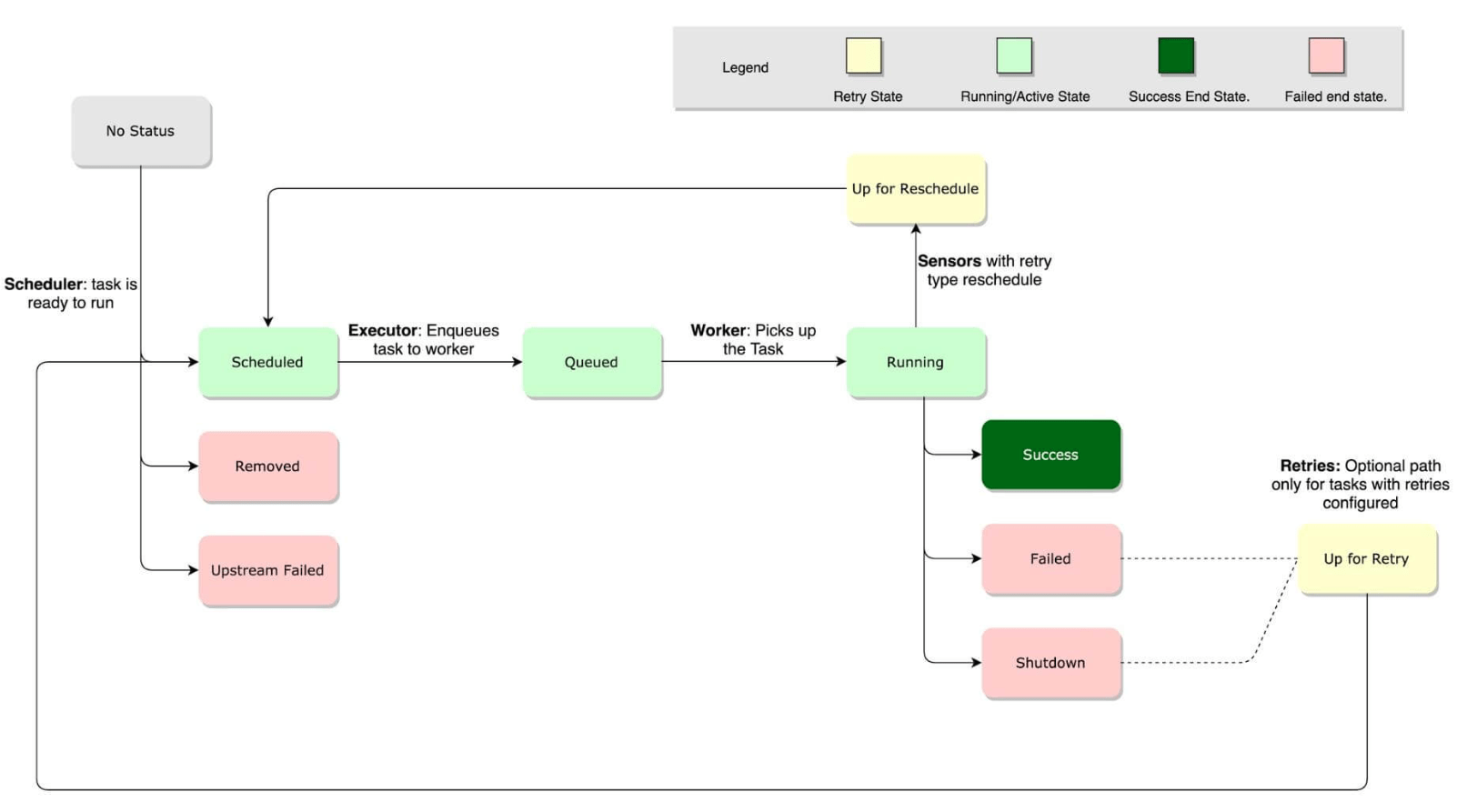
Обзор компонентов Apache Airflow
При работе с Airflow важно понимать основные компоненты его инфраструктуры. Даже если вы в основном взаимодействуете с Airflow как автор DAG, знание того, какие компоненты находятся «под капотом» и зачем они нужны, может быть полезно для разработки ваших DAG, отладки и успешного запуска в Airflow.
Обратите внимание, что в этой статье описаны компоненты и функции Airflow 2.0+. Некоторые из упомянутых здесь компонентов и функций недоступны в более ранних версиях Airflow.
Основные компоненты Airflow
Apache Airflow имеет четыре основных компонента, которые работают постоянно:
- Webserver (Веб-сервер): сервер Flask, работающий с Gunicorn, который обслуживает пользовательский интерфейс Airflow.
- Scheduler (Планировщик): демон, отвечающий за планирование заданий. Это многопоточный процесс Python, который определяет, какие задачи нужно запускать, когда их нужно запускать и где они выполняются.
- Database(База данных): база данных, в которой хранятся все метаданные DAG и задач. Обычно это база данных Postgres, но также поддерживаются MySQL, MsSQL и SQLite.
- Executor: механизм запуска задач. Исполнитель запускается в планировщике всякий раз, когда Airflow работает.
- Папка с файлами DAG, прочитанная планировщиком и исполнителем (и любыми рабочими процессами, имеющимися у исполнителя)
В дополнение к этим основным компонентам есть несколько ситуационных компонентов, которые используются только для запуска задач или использования определенных функций:
- Worker(Рабочий): процесс, который выполняет задачи, определенные исполнителем. В зависимости от того, какого исполнителя вы выберете, у вас могут быть или не быть рабочие как часть вашей инфраструктуры Airflow.
- Trigger (Триггер): Отдельный процесс, поддерживающий отложенные операторы. Этот компонент является необязательным и должен запускаться отдельно. Он нужен только в том случае, если вы планируете использовать отложенные (или «асинхронные») операторы.
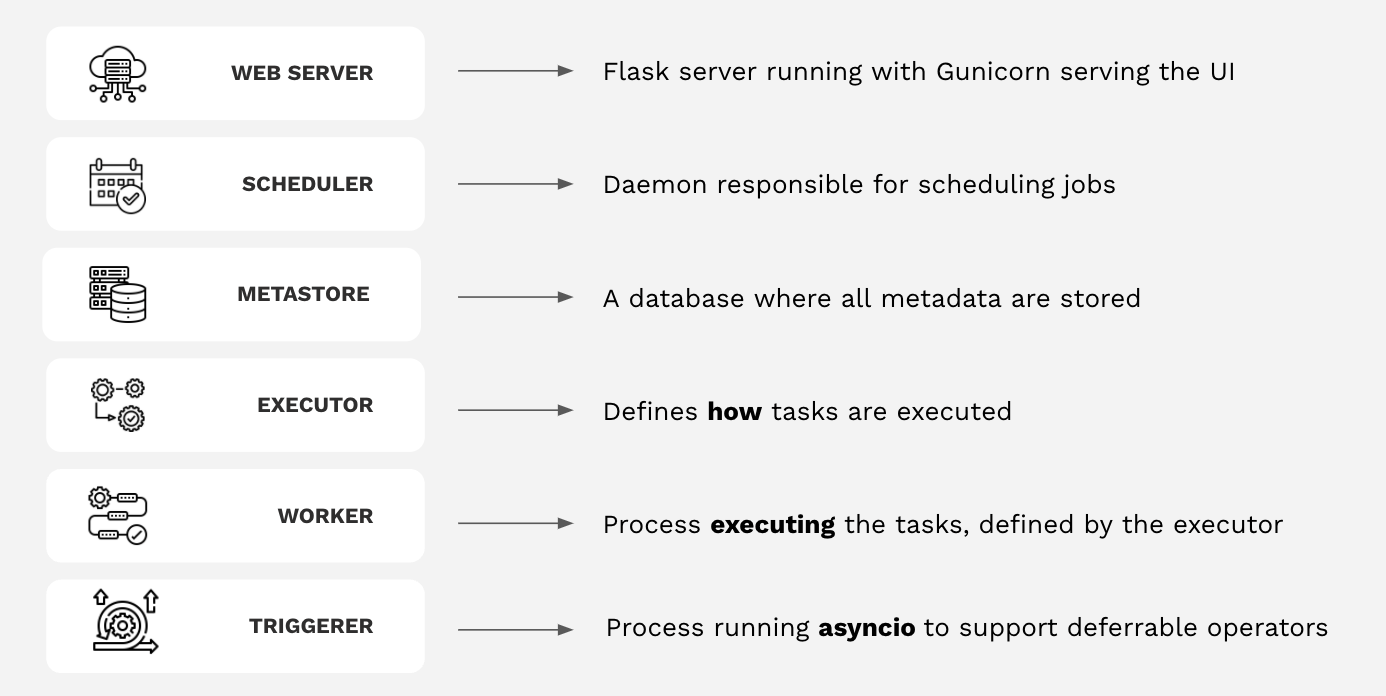
На следующей схеме указано, как все эти компоненты работают вместе:
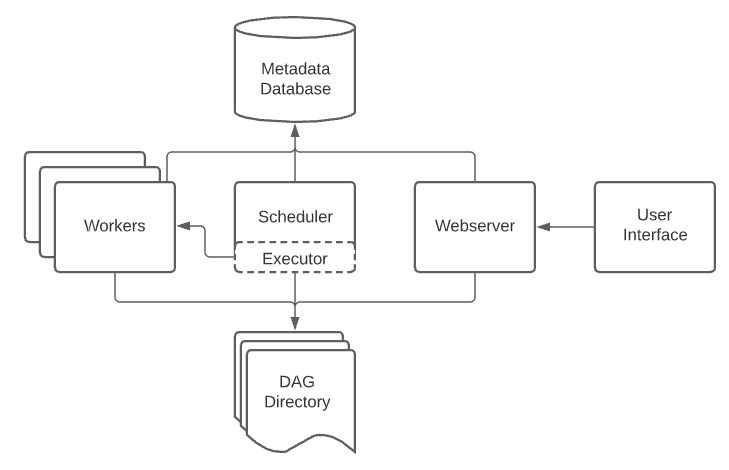

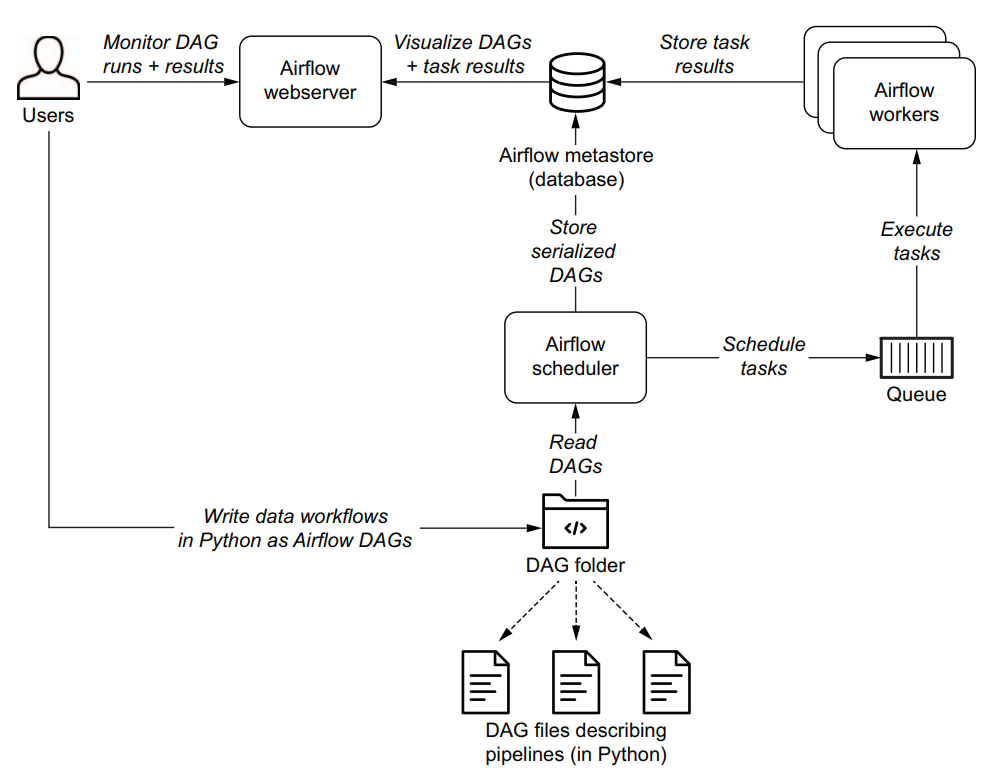
Схема работы Apache Airflow, изображенная на диаграмме, состоит из нескольких ключевых компонентов, каждый из которых играет важную роль в работе системы.
Вот описание работы Apache Airflow на основе этой схемы:
Data Engineer (Инженер по данным):
Инженер по данным отвечает за создание и написание DAGs (Directed Acyclic Graphs), которые описывают рабочие процессы. Эти DAGs сохраняются в специальной папке — DAG folder.
DAG folder (Папка DAG):
Папка, в которой хранятся все DAGs, написанные инженером по данным. Эти DAGs содержат информацию о последовательности задач, которые должны быть выполнены.
Scheduler (Планировщик):
Scheduler считывает DAGs из папки и отвечает за планирование выполнения задач в соответствии с определенными расписаниями.
Планировщик передает задачи на исполнение Executor и следит за тем, чтобы они выполнялись в правильной последовательности.
Executor (Исполнитель):
Executor получает задачи от планировщика и назначает их для выполнения различным Worker (Рабочим).
Он контролирует выполнение задач и отправляет результаты обратно в базу данных метаданных.
Worker (Рабочий):
Worker выполняет назначенные задачи, после чего результаты выполнения сохраняются в Metadata database (База данных метаданных).
Metadata database (База данных метаданных):
Эта база данных хранит результаты выполнения задач, информацию о запусках DAGs и другую метаинформацию, необходимую для работы всей системы.
Webserver (Веб-сервер):
Веб-сервер взаимодействует с базой данных метаданных, чтобы получать результаты выполнения задач и запусков DAGs.
Он также передает эти данные в Airflow UI для визуализации.
Airflow UI (Пользовательский интерфейс Airflow):
Интерфейс, через который инженеры по данным могут мониторить выполнение DAGs и результаты выполнения задач. Это основной способ взаимодействия пользователя с системой.
Таким образом, общая схема работы Apache Airflow выглядит следующим образом:
- Инженер по данным пишет DAGs и сохраняет их в папке DAG.
- Планировщик считывает эти DAGs и планирует выполнение задач.
- Исполнитель назначает задачи для выполнения рабочим.
- Рабочие выполняют задачи и сохраняют результаты в базе данных метаданных.
- Веб-сервер извлекает результаты из базы данных и отображает их через пользовательский интерфейс Airflow, где инженеры по данным могут их просматривать и анализировать.
Executors (Исполнители)
Пользователи Airflow могут выбрать один из нескольких доступных Executors или написать собственный. Каждый Executor имеет преимущества в определенных ситуациях:
- SequentialExecutor: последовательно выполняет задачи внутри процесса планировщика без параллелизма. Этот исполнитель редко используется на практике, но он используется по умолчанию в конфигурации Airflow.
- LocalExecutor: выполняет задачи локально внутри процесса планировщика, но поддерживает параллелизм и гиперпоточность. Этот исполнитель хорошо подходит для тестирования Airflow на локальном компьютере или на одном узле.
- CeleryExecutor: использует серверную часть Celery (например, Redis, RabbitMq или другую систему очередей сообщений) для координации задач между предварительно настроенными рабочими процессами. Этот исполнитель идеально подходит, если у вас есть большое количество более коротких задач или более постоянная загрузка задач.
- KubernetesExecutor: вызывает API Kubernetes для создания отдельного модуля для каждой выполняемой задачи, что позволяет пользователям передавать настраиваемые конфигурации для каждой из своих задач и эффективно использовать ресурсы. Этот исполнитель хорош в нескольких различных контекстах:
- У вас есть длительные задачи, которые вы не хотите прерывать развертыванием кода или обновлениями Airflow.
- Ваши задачи требуют очень специфических конфигураций ресурсов
- Ваши задачи выполняются нечасто, и вы не хотите нести расходы на рабочие ресурсы, когда они не выполняются.
Обратите внимание, что есть также несколько других исполнителей, которые мы здесь не рассматриваем, в том числе CeleryKubernetes Executor и Dask Executor. Они считаются более экспериментальными и не так широко распространены, как другие описанные здесь исполнители.
Обзор процесса обработки Airflow DAGs
Чтобы увидеть, как Airflow выполняет DAG, давайте кратко рассмотрим общий процесс, связанный с разработкой и запуском Airflow DAG. На высоком уровне Airflow состоит из трех основных компонентов:
- Airflow Scheduler — анализирует DAG, проверяет интервал их расписания и (если расписание DAG прошло) начинает планировать выполнение задач DAG, передавая их рабочим процессам Airflow.
- Airflow Workers — берут задачи, запланированные для выполнения, и выполняют их. Таким образом, workers несут ответственность за фактическое «выполнение работы».
- Airflow Webserver — визуализирует DAGs, проанализированные Scheduler, и предоставляет пользователям основной интерфейс для наблюдения за запусками DAGs и их результатами.
Сердцем Airflow, возможно, является планировщик, так как именно здесь происходит большая часть волшебства, которое определяет, когда и как выполняются ваши конвейеры.
Типы переменных в Airflow
Переменная Airflow — это пара ключ-значение, которую можно использовать для хранения информации в вашей среде Airflow. Они обычно используются для хранения информации на уровне экземпляра, которая редко меняется, включая секреты, такие как API key или путь к файлу конфигурации.
Существует два различных типа переменных Airflow:
- regular values (обычные значения) и
- JSON serialized values (сериализованные значения JSON).

Лучшие практики хранения информации в переменных Airflow
Переменные Airflow хранят пары ключ-значение или короткие объекты JSON, которые должны быть доступны во всем вашем экземпляре Airflow. Они являются концепцией конфигурации среды выполнения Airflow и определяются с помощью airflow.model.variable объекта.
При использовании переменных Airflow следует учитывать некоторые рекомендации:
- Переменные Airflow следует использовать для информации, которая зависит от времени выполнения, но не меняется слишком часто.
- Вам следует избегать использования переменных Airflow вне задач в коде DAG верхнего уровня, поскольку они будут создавать соединение с метахранилищем Airflow каждый раз при разборе DAG, что может привести к проблемам с производительностью.
- Если вы используете переменные Airflow в коде DAG верхнего уровня, используйте синтаксис шаблона Jinja, чтобы переменные Airflow отображались только при выполнении задачи.
- Переменные Airflow шифруются с помощью Fernet при записи в метахранилище Airflow. Чтобы скрыть переменные Airflow в пользовательском интерфейсе и журналах, включите подстроку, указывающую на конфиденциальное значение, в имя переменной Airflow.
Существует несколько способов создания переменных Airflow:
- Использование пользовательского интерфейса (Airflow UI)
- Использование интерфейса командной строки (Airflow CLI).
- Использование переменной среды (environment variable).
- Программно из задачи Airflow.
Какие ограничения существуют для XCom в Airflow?
XCom от Apache Airflow — это мощная функция, которая позволяет задачам взаимодействовать, отправляя и забирая сообщения. Однако важно понимать ограничения по размеру, связанные с XCom, чтобы обеспечить эффективное выполнение рабочего процесса.
Вот некоторые рекомендации и соображения:
- Используйте XCom экономно для небольших сообщений: XCom разработан для небольших фрагментов данных. Обработка больших объемов данных должна быть выгружена на внешние системы хранения, такие как S3 или HDFS.
- Избегайте конфиденциальных данных в XCom: Никогда не храните конфиденциальную информацию, такую как пароли или токены, в XCom. Используйте Airflow Connections для безопасного управления учетными данными.
- Пользовательские бэкэнды XCom: для особых случаев использования можно реализовать пользовательские бэкэнды XCom, создав подклассы BaseXCom и переопределив методы сериализации.
- TaskFlow API: в Airflow 2.0 TaskFlow API упрощает передачу данных между задачами с помощью неявных XComs, уменьшая необходимость в явных вызовах xcom_push и xcom_pull.
- Соображения по поводу базы данных: помните о нагрузке на базу данных, так как Airflow может быть требовательным к соединениям с базой данных, особенно с Postgres. Рекомендуется использовать решения для пула соединений, такие как PGBouncer.
- Мониторинг и регулировка: Динамичный характер воздушного потока требует постоянного мониторинга и регулировки конфигураций для поддержания оптимальной производительности.
- Безопасность и контроль доступа: обеспечьте принятие надлежащих мер безопасности, включая TLS, ограничение скорости, аутентификацию и авторизацию для защиты вашего экземпляра Airflow.
XComs следует использовать для передачи небольших объемов данных между задачами. Например, метаданные задач, даты, точность модели или результаты запроса с одним значением — все это идеальные данные для использования с XCom.
Как реализуется последовательность выполнения задач и ассинхронное выполнения задач в airflow?
Последовательность выполнения задач в Airflow определяется зависимостями между задачами в DAG (Directed Acyclic Graph). Каждая задача имеет список зависимостей, которые должны быть выполнены перед ее запуском. Airflow использует эту информацию для определения порядка выполнения задач в DAG.
Асинхронное выполнение задач в Airflow реализуется с помощью Celery Executor. Celery Executor позволяет выполнять задачи асинхронно на удаленных рабочих узлах. Это позволяет распараллеливать выполнение задач и ускорять обработку данных. Кроме того, Celery Executor поддерживает масштабирование, что позволяет обрабатывать большие объемы данных.
Установка и настройка Apache Airflow
Установка Apache Airflow с помощью Docker-Compose на Ubuntu 20.04
Подробная официальная документация по развертыванию Apache Airflow с помощью docker-compose: https://airflow.apache.org/docs/apache-airflow/stable/start/docker.html
Моя краткая инструкция с шагами, которые у меня заработали на Ubuntu 20.04:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# Создаем директорию проекта airflow и переходим в нее mkdir airflow cd airflow # Проверка памяти, должно быть минимум 8Гб docker run --rm "debian:bullseye-slim" bash -c 'numfmt --to iec $(echo $(($(getconf _PHYS_PAGES) * $(getconf PAGE_SIZE))))' # Скачиваем последний docker-compose.yaml файл # Актуальную версию файла можно найти на странице https://airflow.apache.org/docs/apache-airflow/stable/start/docker.html curl -LfO 'https://airflow.apache.org/docs/apache-airflow/2.3.2/docker-compose.yaml' # Далее необходимо создать директории: # ./dags- вы можете разместить свои файлы DAG здесь. # ./logs- содержит журналы выполнения задач и планировщика. # ./plugins- здесь вы можете разместить свои собственные плагины. mkdir -p ./dags ./logs ./plugins # Создаем файл .env с параметром AIRFLOW_UUID echo -e "AIRFLOW_UID=$(id -u)" > .env # Инициализируем базу данных sudo docker-compose up airflow-init # Запуск Apache Airflow с помощью docker-compose sudo docker-compose up |
После установки нужно зайти по адресу http://localhost:8080/
Логин/Пароль по умолчанию: airflow/airflow
Используемый при развертывании выше файл docker-compose.yaml содержит несколько сервисов:
- airflow-scheduler — Планировщик отслеживает все задачи и DAG, а затем запускает экземпляры задач после завершения их зависимостей.
- airflow-webserver — Веб-сервер доступен по адресу http://localhost:8080.
- airflow-worker — Выполняет задачи, определенные планировщиком.
- airflow-init — Служба инициализации.
- postgres — База данных.
- redis — брокер, который пересылает сообщения от планировщика к воркеру.
Примерное потребление ресурсов контейнерами Airflow (без нагрузки):
Airflow довольно требователен к ресурсам.

Я бы указал 4 Gb Ram как минимум (в документации минимальная планка 4Gb RAM), но на мой взгляд на прод лучше сразу запросить 8 Гб RAM.
Процесс установки также описан в видео «Running Airflow 2.0 in 5 mins with Docker»:
Минимальные требования для установки Apache Airflow следующие:
- Операционная система Linux (CentOS 7 или Ubuntu 18.04)
- Python 3.6+ (рекомендуется использовать 3.7+)
- База данных PostgreSQL 9.6+ или MySQL 5.7
- Хранилище сообщений (message broker) Apache Celery
- Веб-сервер Nginx (рекомендуется)
- Рекомендуемый объем оперативной памяти: 256 МБ или больше.
Таким образом, одна из рекомендованных конфигураций сервера для установки Apache Airflow может быть следующей:
- Операционная система: CentOS 7 или Ubuntu 18.04
- Процессор: Intel Core i5 или эквивалентный
- Оперативная память: 4 ГБ или больше
- Хранилище сообщений (message broker): Apache Celery (должен быть установлен и настроен отдельно)
- База данных: PostgreSQL 9.6+ или MySQL 5.7
- Веб-сервер: Nginx (рекомендуется).
Однако, если вы планируете запускать большое число DAG-файлов, которые будут выполняться одновременно, то может потребоваться более мощное железо. Например, в таком случае вы можете рассматривать использование многопроцессорной системы с большим объемом оперативной памяти и быстрым хранилищем сообщений.
Настройка Apache Airflow
Обязательно проверьте в docker-compose.yaml какие директории привязаны к volume. В новой версии используются переменные и если они не сработают, то DAG, размещенный в соответствующей директории, не подтянется.
|
1 2 3 4 |
volumes: - ${AIRFLOW_PROJ_DIR:-.}/dags:/opt/airflow/dags - ${AIRFLOW_PROJ_DIR:-.}/logs:/opt/airflow/logs - ${AIRFLOW_PROJ_DIR:-.}/plugins:/opt/airflow/plugins |
Если не знаете как настроить переменные, то можно отредактировать docker-compose.yaml:
|
1 2 3 4 |
volumes: - ./dags:/opt/airflow/dags - ./logs:/opt/airflow/logs - ./plugins:/opt/airflow/plugins |
Основные параметры Airflow.cfg
Airflow.cfg — это конфигурационный файл Apache Airflow, который используется для определения параметров и настроек для организации рабочих процессов.
Основные параметры Airflow.cfg включают:
1. core:
- airflow_home: каталог домашней директории, в которой сохраняются все файлы, связанные с работой Airflow.
- dags_folder: определяет путь до папки, которая содержит DAG-файлы.
- executor: определяет тип исполнителя, который будет использоваться для запуска задач (SequentialExecutor, LocalExecutor, CeleryExecutor, DaskExecutor).
- load_examples: определяет, нужно ли загружать примеры DAG-файлов (True или False).
- pid_location: определяет местоположение файла PID для процесса управления.
2. webserver:
- web_server_host: адрес хоста, на котором запускается веб-сервер Airflow.
- web_server_port: номер порта, на котором будет доступен веб-сервер Airflow.
- web_server_worker_timeout: время тайм-аута (в секундах) для веб-сервера Airflow.
- secret_key: секретный ключ, используемый веб-сервером Airflow для защиты сессий пользователя.
3. scheduler:
- dag_dir_list_interval: интервал обновления списка файлов DAG (в секундах).
- max_threads: максимальное количество потоков, которые могут использоваться при запуске задач.
- statsd_on: включить или выключить источник метрик statsd.
4. email:
- email_backend: тип бэкэнда, используемого для отправки почты.
- email_from_name: имя отправителя электронной почты.
- email_from_address: адрес электронной почты отправителя.
5. logging:
- logging_config_class: класс конфигурации логирования.
- remote_logging: включить или выключить удаленное логирование.
- remote_log_conn_id: идентификатор соединения для удаленного логирования.
Эти параметры могут быть настроены в Airflow.cfg в соответствии с требованиями конкретного проекта или приложения.
FAQ: Вопросы и ответы
Как переиспользовать функции Python между разными DAG? Как переиспользовать код в нескольких DAG?
Для переиспользования функций Python между разными DAG в Apache Airflow можно использовать модули Python. Модуль содержит функции и переменные, которые могут быть использованы в других модулях и DAG.
Для переиспользования кода в нескольких DAG можно создать отдельный файл с функциями и импортировать его в каждый DAG, где эти функции нужны. Это позволяет избежать дублирования кода и сократить время разработки.
Например, можно создать файл с названием utils.py, который содержит функции, используемые в нескольких DAG. Затем, в каждом DAG можно импортировать этот файл и вызывать нужные функции:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
from datetime import datetime from airflow import DAG from utils import my_function default_args = { 'owner': 'airflow', 'start_date': datetime(2021, 1, 1), } dag = DAG('my_dag', default_args=default_args) task = PythonOperator( task_id='my_task', python_callable=my_function, dag=dag, ) |
В данном примере мы импортируем функцию my_function из файла utils.py и вызываем ее в задаче my_task в DAG my_dag. Таким образом, мы переиспользуем код и избегаем дублирования.
Что такое модуль в Airflow? Как создать и подключить свой модуль в Airflow?
Модуль в Apache Airflow — это файл с расширением .py, который содержит функции, классы и переменные, которые могут быть использованы в других модулях и DAG. Создание и подключение своего модуля в Airflow позволяет переиспользовать код и избежать дублирования.
Для создания модуля в Airflow нужно создать файл с расширением .py и определить в нем нужные функции, классы и переменные. Затем, этот файл можно импортировать в другие модули и DAG.
Например, мы можем создать файл utils.py со следующим содержимым:
|
1 2 |
def my_function(): print('Hello World!') |
Затем, мы можем импортировать этот модуль в другой файл или DAG следующим образом:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
from datetime import datetime from airflow import DAG from utils import my_function default_args = { 'owner': 'airflow', 'start_date': datetime(2021, 1, 1), } dag = DAG('my_dag', default_args=default_args) task = PythonOperator( task_id='my_task', python_callable=my_function, dag=dag, ) |
В данном примере мы импортируем функцию my_function из файла utils.py и вызываем ее в задаче my_task в DAG my_dag. Таким образом, мы переиспользуем код и избегаем дублирования.
Как импортировать модули в Airflow, если Airflow развернут в контейнерах Docker?
Если Airflow развернут в контейнерах Docker, то для импорта модулей нужно убедиться, что они находятся в правильном месте внутри контейнера. Обычно модули располагаются в папке dags, которая монтируется в контейнер с помощью Docker volume.
Например, если мы хотим импортировать модуль utils.py из папки dags, то нужно использовать следующий путь:
|
1 |
from dags.utils import my_function |
Важно также убедиться, что все зависимости и библиотеки, необходимые для работы модуля, установлены в контейнере. Это можно сделать с помощью Dockerfile и requirements.txt файла.
Пример Dockerfile для контейнера Airflow с установкой дополнительных библиотек:
|
1 2 3 4 5 6 7 8 9 |
FROM apache/airflow:2.1.2 USER root COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt USER airflow |
В данном примере мы копируем файл requirements.txt в контейнер и устанавливаем все необходимые библиотеки перед переключением на пользователя airflow. Таким образом, мы гарантируем, что все зависимости будут установлены в контейнере и доступны для использования в модулях Airflow.
Какие сложности часто возникают при работе в Airflow?
При работе в Airflow могут возникать следующие сложности:
- Ошибки импорта модулей: если модули не находятся в правильном месте или не установлены все необходимые зависимости, то может возникнуть ошибка импорта.
- Неправильно настроенные подключения к базам данных: если подключения к базам данных не настроены правильно, то задачи, которые используют эти подключения, могут завершаться с ошибкой.
- Неправильно настроенные переменные окружения: если переменные окружения не настроены правильно, то задачи могут завершаться с ошибкой или не запускаться вовсе.
- Проблемы с расписанием выполнения задач: если расписание выполнения задач не настроено правильно, то задачи могут запускаться слишком часто или слишком редко, что может привести к нежелательным последствиям.
- Проблемы с масштабированием: если Airflow используется для обработки большого объема данных, то может возникнуть проблема с масштабированием. В этом случае необходимо настроить кластер Airflow для распределения задач на несколько узлов.
- Проблемы с безопасностью: при работе в Airflow необходимо обеспечить безопасность данных и защиту от несанкционированного доступа к системе. Для этого можно использовать различные инструменты, такие как SSL-шифрование, аутентификацию и авторизацию пользователей и т.д.
Как выполнить 2 задачи из одного DAG в разных контейнерах Docker?
Для выполнения двух задач из одного DAG в разных контейнерах Docker можно использовать операторы DockerOperator и BashOperator.
Пример кода DAG:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
from airflow import DAG from airflow.operators.bash_operator import BashOperator from airflow.operators.docker_operator import DockerOperator from datetime import datetime default_args = { 'owner': 'airflow', 'depends_on_past': False, 'start_date': datetime(2022, 1, 1), 'email_on_failure': False, 'email_on_retry': False, 'retries': 1 } dag = DAG('docker_dag', default_args=default_args, schedule_interval='@daily') # Оператор DockerOperator для запуска контейнера с задачей 1 task_1 = DockerOperator( task_id='task_1', image='my_image:latest', command='/bin/bash -c "python /app/task_1.py"', docker_url='tcp://localhost:2375', network_mode='bridge', dag=dag ) # Оператор BashOperator для запуска задачи 2 в отдельном контейнере task_2 = BashOperator( task_id='task_2', bash_command='docker run my_image:latest python /app/task_2.py', dag=dag ) # Задача 2 должна выполниться только после успешного выполнения задачи 1 task_1 >> task_2 |
В данном примере мы используем DockerOperator для запуска контейнера с задачей 1 и BashOperator для запуска задачи 2 в отдельном контейнере. Обратите внимание, что мы используем команду docker run для запуска задачи 2 в отдельном контейнере, а также указываем имя образа и путь к файлу с задачей.
Также мы указываем, что задача 2 должна выполниться только после успешного выполнения задачи 1, используя оператор >>. Это означает, что Airflow будет ждать успешного завершения задачи 1, прежде чем запустить задачу 2.
Пример DAG отправки сообщения в Slack
Для отправки сообщения в Slack через API можно использовать оператор PythonOperator и библиотеку Slack SDK.
Пример кода DAG:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
from airflow import DAG from airflow.operators.python_operator import PythonOperator from slack_sdk import WebClient from slack_sdk.errors import SlackApiError from datetime import datetime default_args = { 'owner': 'airflow', 'depends_on_past': False, 'start_date': datetime(2022, 1, 1), 'email_on_failure': False, 'email_on_retry': False, 'retries': 1 } dag = DAG('slack_dag', default_args=default_args, schedule_interval='@daily') # Функция для отправки сообщения в Slack def send_slack_message(): client = WebClient(token='your_slack_token') try: response = client.chat_postMessage( channel='#general', text='Hello, Airflow!' ) print(response) except SlackApiError as e: print("Error sending message: {}".format(e)) # Оператор PythonOperator для вызова функции отправки сообщения в Slack send_message_task = PythonOperator( task_id='send_message', python_callable=send_slack_message, dag=dag ) |
В данном примере мы создаем функцию send_slack_message(), которая использует WebClient из библиотеки Slack SDK для отправки сообщения в канал #general. В функции мы указываем ваш токен доступа к Slack API.
Затем мы используем оператор PythonOperator для вызова функции send_slack_message() в DAG. Обратите внимание, что мы не используем оператор >>, так как задача отправки сообщения не зависит от выполнения других задач.
Данный DAG будет отправлять сообщение в Slack каждый день в соответствии с расписанием, указанным в параметре schedule_interval.
Пример DAG с отправкой отчета Excel из Pandas Dataframe в канал Slack
Для отправки отчета Excel из Pandas Dataframe в канал Slack через API можно использовать оператор PythonOperator и библиотеки Slack SDK и Pandas.
Пример кода DAG:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
from airflow import DAG from airflow.operators.python_operator import PythonOperator from slack_sdk import WebClient from slack_sdk.errors import SlackApiError import pandas as pd from datetime import datetime default_args = { 'owner': 'airflow', 'depends_on_past': False, 'start_date': datetime(2022, 1, 1), 'email_on_failure': False, 'email_on_retry': False, 'retries': 1 } dag = DAG('slack_excel_report', default_args=default_args, schedule_interval='@daily') # Функция для отправки сообщения с отчетом в Slack def send_excel_report(): client = WebClient(token='your_slack_token') try: # Создаем датафрейм с данными для отчета data = {'Name': ['John', 'Jane', 'Bob'], 'Age': [25, 30, 35]} df = pd.DataFrame(data) # Создаем Excel-файл из датафрейма excel_file = df.to_excel('report.xlsx', index=False) # Отправляем сообщение в Slack с прикрепленным Excel-файлом response = client.files_upload( channels='#general', file='report.xlsx', title='Daily report' ) print(response) except SlackApiError as e: print("Error sending message: {}".format(e)) # Оператор PythonOperator для вызова функции отправки отчета в Slack send_report_task = PythonOperator( task_id='send_report', python_callable=send_excel_report, dag=dag ) |
В данном примере мы создаем функцию send_excel_report(), которая использует WebClient из библиотеки Slack SDK и Pandas для создания Excel-файла из датафрейма и отправки его в канал #general. В функции мы указываем ваш токен доступа к Slack API.
Затем мы используем оператор PythonOperator для вызова функции send_excel_report() в DAG. Обратите внимание, что мы не используем оператор >>, так как задача отправки отчета не зависит от выполнения других задач.
Данный DAG будет отправлять отчет в Slack каждый день в соответствии с расписанием, указанным в параметре schedule_interval.
Как указать в dag асинхронно или последовательно выполнять задачи? Пример асинхронного и последовательного dag
В DAG можно указать порядок выполнения задач с помощью операторов PythonOperator и BashOperator, которые позволяют вызывать асинхронные или синхронные функции и скрипты.
Пример последовательного DAG:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
from airflow import DAG from airflow.operators.bash_operator import BashOperator from datetime import datetime default_args = { 'owner': 'airflow', 'start_date': datetime(2021, 1, 1), } dag = DAG('sequential_dag', default_args=default_args) task1 = BashOperator( task_id='task1', bash_command='echo "Task 1"', dag=dag, ) task2 = BashOperator( task_id='task2', bash_command='echo "Task 2"', dag=dag, ) task3 = BashOperator( task_id='task3', bash_command='echo "Task 3"', dag=dag, ) task1 >> task2 >> task3 |
В этом примере задачи task1, task2 и task3 будут выполнены последовательно, так как задача task2 зависит от выполнения задачи task1, а задача task3 зависит от выполнения задачи task2.
Пример асинхронного DAG:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
from airflow import DAG from airflow.operators.python_operator import PythonOperator from datetime import datetime import time default_args = { 'owner': 'airflow', 'start_date': datetime(2021, 1, 1), } dag = DAG('async_dag', default_args=default_args) def my_function(): print('Starting my function') time.sleep(5) print('Finishing my function') task1 = PythonOperator( task_id='task1', python_callable=my_function, dag=dag, ) task2 = PythonOperator( task_id='task2', python_callable=my_function, dag=dag, ) task3 = PythonOperator( task_id='task3', python_callable=my_function, dag=dag, ) task1 >> [task2, task3] |
В этом примере задачи task1, task2 и task3 будут выполнены асинхронно, так как задачи task2 и task3 не зависят от выполнения задачи task1.
Отправка красивого письма с вложенным файлом excel через dag airflow
Для отправки письма с вложенным файлом excel через DAG Airflow можно использовать оператор EmailOperator.
Пример DAG:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
from airflow import DAG from airflow.operators.email_operator import EmailOperator from datetime import datetime default_args = { 'owner': 'airflow', 'start_date': datetime(2021, 1, 1), } dag = DAG('email_dag', default_args=default_args) send_email = EmailOperator( task_id='send_email', to='recipient@example.com', subject='Airflow email with attachment', html_content='<p>Dear recipient,</p><p>Please find attached the excel file.</p>', files=['/path/to/file.xlsx'], dag=dag, ) |
Как продать идею внедрения airflow руководству?
- Подготовьте анализ бизнес-процессов вашей компании и определите, где можно автоматизировать задачи с помощью DAG Airflow. Например, это может быть автоматическая отправка отчетов по электронной почте, запуск ETL-процессов для обработки данных или мониторинг работы приложений.
- Подготовьте презентацию, в которой покажите, как автоматизация задач с помощью DAG Airflow поможет увеличить эффективность работы и снизить затраты на ручное выполнение задач.
- Подготовьте демонстрационный проект, который покажет преимущества DAG Airflow. Например, это может быть DAG для автоматической отправки отчетов по электронной почте или DAG для мониторинга работы приложений.
- Подготовьте список преимуществ DAG Airflow, таких как возможность параллельного выполнения задач, удобный интерфейс для управления задачами и логирования выполнения задач.
- Объясните, какие затраты будут необходимы для внедрения DAG Airflow и какие выгоды они принесут в долгосрочной перспективе.
- Объясните, какую поддержку и обучение будут предоставлены сотрудникам, которые будут использовать DAG Airflow.
- Предложите план внедрения DAG Airflow, который будет учитывать потребности и возможности компании. Например, это может быть поэтапное внедрение DAG Airflow в различных бизнес-процессах компании.
- Подготовьте список возможных рисков и способов их уменьшения при внедрении DAG Airflow.
- Предложите план обновления и поддержки DAG Airflow после его внедрения.
- Проведите презентацию руководству компании и ответьте на все их вопросы. Дайте им время для обдумывания и принятия решения.
Как создать цепочку задач для выполнения etl в Apache PySpark
Для создания цепочки задач для выполнения ETL в Apache PySpark можно использовать библиотеку Apache Airflow. Вот пример создания такой цепочки:
1. Создайте DAG (Directed Acyclic Graph) — это граф, который определяет порядок выполнения задач.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
from airflow import DAG from datetime import datetime, timedelta default_args = { 'owner': 'airflow', 'depends_on_past': False, 'start_date': datetime(2022, 1, 1), 'email_on_failure': False, 'email_on_retry': False, 'retries': 1, 'retry_delay': timedelta(minutes=5), } dag = DAG( 'etl_pipeline', default_args=default_args, description='ETL pipeline with PySpark', schedule_interval=timedelta(days=1), ) |
2. Определите задачи, которые нужно выполнить. В этом примере мы будем использовать две задачи: первая загружает данные из источника данных (например, базы данных), а вторая обрабатывает эти данные с помощью PySpark.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
from airflow.operators.python_operator import PythonOperator from pyspark.sql import SparkSession def load_data(): # код для загрузки данных из источника данных def process_data(): spark = SparkSession.builder.appName('ETL').getOrCreate() # код для обработки данных с помощью PySpark load_data_task = PythonOperator( task_id='load_data', python_callable=load_data, dag=dag, ) process_data_task = PythonOperator( task_id='process_data', python_callable=process_data, dag=dag, ) |
3. Определите порядок выполнения задач. В этом примере мы будем выполнять задачи последовательно: сначала загрузка данных, затем обработка данных.
|
1 |
load_data_task >> process_data_task |
4. Запустите DAG в Apache Airflow. После запуска DAG задачи будут выполняться автоматически в заданном порядке.
|
1 |
airflow trigger_dag etl_pipeline |
Это простой пример создания цепочки задач для выполнения ETL в Apache PySpark с помощью Apache Airflow. В зависимости от требований проекта можно добавлять новые задачи и настраивать порядок их выполнения.
Как создать несколько задач и дождаться их выполнения в Apache Airflow
Для создания нескольких задач в Apache Airflow, вы можете создать несколько операторов (operators) в вашем DAG файле. Каждый оператор соответствует отдельной задаче.
Например, для создания трех задач — task1, task2 и task3, вам нужно определить три оператора:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
from airflow import DAG from airflow.operators.bash_operator import BashOperator from datetime import datetime dag = DAG(dag_id='my_dag', start_date=datetime.now()) task1 = BashOperator( task_id='task1', bash_command='echo "Hello from task1"', dag=dag, ) task2 = BashOperator( task_id='task2', bash_command='echo "Hello from task2"', dag=dag, ) task3 = BashOperator( task_id='task3', bash_command='echo "Hello from task3"', dag=dag, ) |
Затем вы можете установить правила зависимости между задачами, используя методы set_upstream и set_downstream.
|
1 2 |
task1.set_downstream(task2) task2.set_downstream(task3) |
В этом примере task1 будет зависеть от ничего, task2 будет зависеть от task1, и task3 будет зависеть от task2.
Чтобы дождаться выполнения всех задач, вы можете использовать метод wait_for_completion, который блокирует выполнение кода, пока все задачи не будут завершены:
|
1 2 3 |
from airflow.utils.trigger_rule import TriggerRule task3.set_downstream(wait_for_completion=True, trigger_rule=TriggerRule.ALL_DONE) |
Здесь задача task3 будет дожидаться, пока все предшествующие задачи завершатся, прежде чем выполниться.
В чем разница между Apache NiFi vs Airflow?
Ниже приведены некоторые из основных различий между Apache NiFi и Apache Airflow:
1. Назначение
Apache NiFi был разработан, чтобы обеспечить интеграцию данных и автоматизацию потоков данных, основанных на событиях. С другой стороны, Apache Airflow был разработан для управления процессами обработки данных в рамках конвейера обработки данных.
2. Функциональность
NiFi имеет встроенные функции обработки и интеграции данных, такие как маршрутизация, преобразование и фильтрация данных. Airflow же предоставляет возможность для создания и управления рабочими процессами, которые могут включать задачи и зависимости между ними.
3. Операционный процесс
NiFi обрабатывает потоки данных в реальном времени и может осуществлять масштабирование горизонтально. В то время как Airflow концентрируется на обработке задач на основе конвейера обработки данных и может использоваться для управления батч-процессами.
4. Язык программирования
NiFi использует язык программирования Java, в то время как Airflow использует Python.
5. Экосистема
NiFi имеет большую экосистему, включающую в себя множество плагинов и интеграций с различными технологиями. Airflow также имеет экосистему, но в несколько меньшем объеме.
В целом, NiFi и Airflow предоставляют различные функциональности и рассчитаны на разные типы задач. NiFi больше подходит для интеграции и обработки данных в режиме реального времени, а Airflow подходит для управления конвейерами обработки данных в контексте батч-процессов.
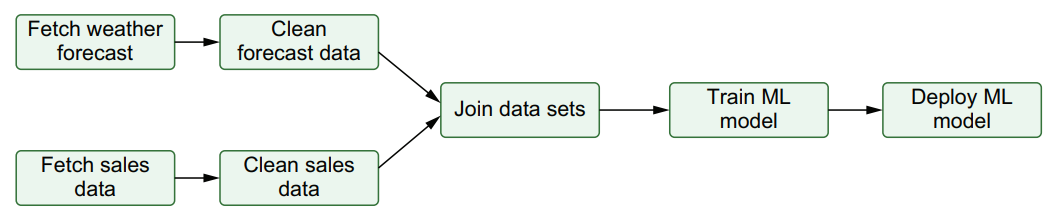
Data Pipelines (пайплайны) внутри DAG. Пайплайн airflow
DAG (Directed Acyclic Graph) — это графическая модель, которая позволяет определить зависимости между задачами и выполнить их в нужном порядке для достижения цели.
Pipeline — это конвейер, который позволяет передавать данные между различными этапами выполнения.
Пайплайны внутри DAG используются для определения шагов и логических зависимостей между этапами выполнения. Каждый пайплайн может быть представлен в виде отдельной задачи и выполняться в определенной последовательности.
Примером может служить DAG, в котором есть задачи: загрузка данных, предобработка данных, обучение модели и тестирование модели. Здесь можно использовать пайплайны для определения зависимостей между этими задачами. Например, задача предобработки данных может зависеть от задачи загрузки данных, а задача обучения модели может зависеть от задачи предобработки данных.
Таким образом, пайплайны внутри DAG помогают определить порядок выполнения задач и повышают эффективность и качество работы системы.

