<<< Вернуться в основной раздел «QlikView — краткий учебник»
Contents
- 1 Разница между Join и Concatenate?
- 2 Что такое Synthetic key (синтетический ключ)? Хорошо или плохо когда синтетический ключ есть в модели?
- 3 Что такое No Concatenate?
- 4 Что такое P() и E() в Анализе множеств (Set analysis)?
- 5 Что такое сравнительный анализ (Comparative analysis)?
- 6 Что такое Mekko chart? И в чем разница между Bar и Mekko chart?
- 7 Кратко объясните как хранит данные QlikView внутри себя?
- 8 В чем разница между Internal Table View и Source Table View?
- 9 В чем разница между элементами Pivot, Straight and Table box?
- 10 Что такое cross table (кросс-таблица)?
- 11 Способы подключения к различным источникам данных в QlikView?
- 12 Что такое частичная перезагрузка (partial reloading)?
- 13 Какие различные join доступны в QlikView?
- 14 В чем разница между Star и Snoflake схемами?
- 15 Как и для чего используются макросы (Macro) в QlikView?
- 16 Что такое Peek, Previous, Apply map, Interval Match?
- 17 Какие пути оптимизации дашбордов (dashboards) существуют в QlikView?
- 18 Что такое Slowly Changing Dimensions (SCD)?
- 19 В чем разница между Pick и Match?
- 20 Что такое нечеткий поиск (fuzzy search)?
В данной статье я постарался ответить на наиболее часто встречающиеся практические вопросы по QlikVIew. Надеюсь, что собранные и систематизированные примеры будут полезны как новичкам в бизнес-аналитике, так и профессионалам в сфере Business Intelligence. Если у Вас возникли вопросы или замечания по статье, то прошу внизу оставить Ваш комментарий. Буду рад помочь или, в случае недочетов в статье, внести исправления. Все ответы на вопросы были опробованы на практике и перепроверены на простых и понятных примерах.

Разница между Join и Concatenate?
Concatenate – Объединяет таблицы со схожими полями.
Join – добавляет поля (столбцы) к предыдущей загруженной таблице.
Пример 1 (по умолчанию Concatenate)
Если у нас в таблицах имена полей одинаковые, то данные объединяются в одну таблицу:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
[table1]: LOAD * Inline [ Key, field1, field2 1, Петр, Бондарчук 3, Надежда, Филипова 4, Сергей, Михайлов ]; [table2]: LOAD * Inline [ Key, field1, field2 1, удочка, хлеб 2, крючки, колбаса 4, нож, сыр ]; |
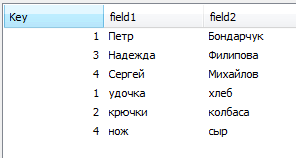
Пример 2 – разные поля
Если у нас в таблицах имена полей разные, то создаются две самостоятельные таблицы:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
[table1]: LOAD * Inline [ Key, field1, field2 1, Петр, Бондарчук 3, Надежда, Филипова 4, Сергей, Михайлов ]; [table2]: LOAD * Inline [ Key, field3, field4 1, удочка, хлеб 2, крючки, колбаса 4, нож, сыр ]; |
Пример 3 (NoConcatenate)
Таблица table2 создастся, если использовать NoConcatenate (в случае одинаковых полей у таблиц). Так можно в модели делать промежуточные таблицы (или временные таблицы), в нашем случае это table2:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
[table1]: LOAD * Inline [ Key, field1, field2 1, Петр, Бондарчук 3, Надежда, Филипова 4, Сергей, Михайлов ]; NoConcatenate [table2]: LOAD * Inline [ Key, field1, field2 1, удочка, хлеб 2, крючки, колбаса 4, нож, сыр ]; [table3]: Load Key, field1 as field3, field2 as field4 Resident [table2]; DROP Table [table2]; |
Таблица table2 не создастся, а все данные пойдут в table1, если использовать Concatenate (или не использовать, т.к. по умолчанию используется concatenate):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
[table1]: LOAD * Inline [ Key, field1, field2 1, Петр, Бондарчук 3, Надежда, Филипова 4, Сергей, Михайлов ]; Concatenate [table2]: LOAD * Inline [ Key, field1, field2 1, удочка, хлеб 2, крючки, колбаса 4, нож, сыр ]; [table3]: Load Key, field1 as field3, field2 as field4 Resident [table2]; DROP Table [table2]; |
И тогда при создании таблицы table3 мы получим ошибку (т.к. таблицы table2 не существует):
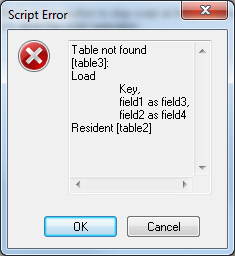
А таблица table1 будет выглядеть следующим образом:

Пример 4 (Concatenate)
Если объединить таблицы с разными полями при помощи concantenate, то получим следующий результат:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
[table1]: LOAD * Inline [ Key, field1, field2 1, Петр, Бондарчук 3, Надежда, Филипова 4, Сергей, Михайлов ]; Concatenate [table2]: LOAD * Inline [ Key, field3, field4 1, удочка, хлеб 2, крючки, колбаса 4, нож, сыр ]; |

Пример 5 – JOIN
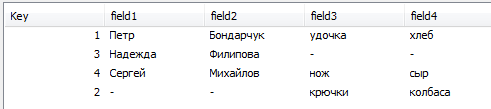
Если сделать JOIN таблиц с разными полями (и одним общим), то получится следующая картинка:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
[table1]: LOAD * Inline [ Key, field1, field2 1, Петр, Бондарчук 3, Надежда, Филипова 4, Сергей, Михайлов ]; JOIN(table1) [table2]: LOAD * Inline [ Key, field3, field4 1, удочка, хлеб 2, крючки, колбаса 4, нож, сыр ]; |
По умолчанию применится OUTER JOIN:
Пример 6 – JOIN по двум полям
Если у нас два одинаковых поля, то join сделается по двум полям:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
[table1]: LOAD * Inline [ Key, field1, field2 1, Петр, Бондарчук 3, Надежда, Филипова 4, Сергей, Михайлов ]; JOIN(table1) [table2]: LOAD * Inline [ Key, field2, field3 1, Бондарчук, хлеб 2, Оксёнова, колбаса 3, Филипова, яйца 4, Сергеева, сыр ]; |
По умолчанию применится OUTER JOIN:
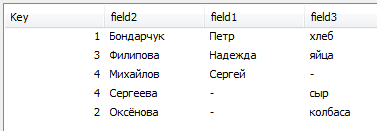
Пример 7 – INNER JOIN
Если применить INNER JOIN при одном одинаковом поле, то получим следующий результат:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
[table1]: LOAD * Inline [ Key, field1, field2 1, Петр, Бондарчук 3, Надежда, Филипова 4, Сергей, Михайлов ]; INNER JOIN(table1) [table2]: LOAD * Inline [ Key, field3, field4 1, удочка, хлеб 2, крючки, колбаса 4, нож, сыр ]; |

Что такое Synthetic key (синтетический ключ)? Хорошо или плохо когда синтетический ключ есть в модели?
В QlikView таблицы соединяются по одинаково названным полям. Поэтому, если две или несколько внутренних таблиц имеют два или несколько общих полей, то это предполагает взаимосвязь составного ключа. В QlikView эта операция выполняется с помощью синтетических ключей. Эти ключи представляют собой анонимные поля, включающие все возможные сочетания составного ключа. Если количество составных ключей увеличивается в зависимости от количеств данных, структуры таблиц и других факторов, в QlikView они могут или не могут быть полноценно обработаны. Для работы QlikView может потребоваться дополнительное количество времени и/или памяти. К сожалению, текущие ограничения фактически невозможно предсказать, поэтому для их определения остается только использовать практический путь проб и ошибок.
В связи с этим рекомендуется выполнять полный анализ предполагаемой структуры таблиц разработчиком приложений. Рассмотрим пример, в котором возникает составной ключ.
Предположим у нас есть скрипт, который создает две таблицы:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
table1: LOAD * INLINE [ Key1, Key2, field1, field2 1, 101, Петр, Бондарчук 3, 103, Надежда, Филипова 4, 104, Сергей, Михайлов ]; table2: LOAD * INLINE [ Key1, Key2, field3, field4 1, 101, удочка, хлеб 2, 102, крючки, колбаса 4, 104, нож, сыр ]; |
Результатом работы скрипта будет следующая картинка модели данных:
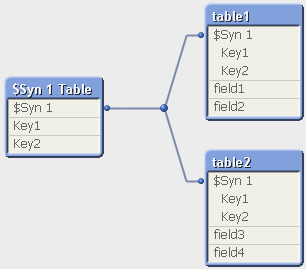
$Syn 1 Table создается автоматически и содержит следующие поля:
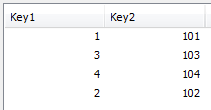
Table1 содержит поля:

Table2 содержит поля:
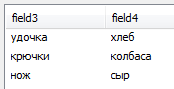
При этом синтетические ключи фактически являются внутренним связующим элементом между двумя таблицами. В самой же таблице никакого ключа фактически нет, он скрыт.
Как избавиться от синтетического ключа в QlikView?
Избежать возникновение синтетического ключа можно прибегнув к следующим приемам:
1) QUALIFY
Автоматическое объединение полей с одинаковыми именами в разных таблицах можно отключить с помощью оператора qualify, который уточняет имя поля с именем таблицы. В случае уточнения имена полей будут изменены после их нахождения в таблице. Новое имя будет иметь вид имя_таблицы.имя_поля. Имя_таблицы соответствует метке текущей таблицы или при отсутствии метки — имени после слова from в операторах load и select.
Когда запускается сценарий, функция уточнения всегда отключена по умолчанию. Уточнение имени поля можно включить в любое время с помощью оператора qualify. Уточнение можно выключить в любое время с помощью оператора Unqualify.
- Qualify *; — Уточняет все поля во всех таблицах.
- Qualify “*_Name”; — Уточняются поля, которые заканчиваются на “_Name”.
- Qualify “Name_*”; — Уточняются поля, которые начинаются на “Name_”.
- Qualify “Amt*”,Profit; — Уточняются все поля, начинающиеся на “Amt”, а также поле Profit.
- Qualify S???; — Уточняются все поля из четырех символов, которые начинаются с “S”.
Иллюстрация работы:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
Qualify Key2; table1: LOAD * INLINE [ Key1, Key2, field1, field2 1, 101, Петр, Бондарчук 3, 103, Надежда, Филипова 4, 104, Сергей, Михайлов ]; table2: LOAD * INLINE [ Key1, Key2, field3, field4 1, 101, удочка, хлеб 2, 102, крючки, колбаса 4, 104, нож, сыр ]; |

Примечание: Оператор qualify запрещается использовать в контексте частичной загрузки!
2) Создание комбинированного ключа при помощи функций Autonumber и Hash
Autonumber — возвращает уникальное значение целого для каждого определенного значения expression, возникающего в процессе выполнения скрипта.
|
1 |
autonumber(Region&Year&Month) |
Autonumberhash128 — вычисляет 128-битные случайные данные значений выражений комбинированного ввода и возвращает уникальное значение целого.
|
1 |
autonumberhash128 (Region, Year, Month) |
Autonumberhash256 — вычисляет 256-битные случайные данные значений выражений комбинированного ввода и возвращает уникальное значение целого.
|
1 |
Autonumberhash256 (Region, Year, Month) |
Hash128 — возвращает 128-разрядный хэш сочетания значений входного выражения. Результат — зашифрованная строка.
|
1 |
Hash128 ( Region, Year, Month ) |
Hash160 — возвращает 160-разрядный хэш сочетания значений входного выражения. Результат — зашифрованная строка.
|
1 |
Hash160 (Region, Year, Month) |
Hash256 — возвращает 256-разрядный хэш сочетания значений входного выражения. Результат — зашифрованная строка.
|
1 |
Hash256 (Region, Year, Month) |
3) Переименование полей
Иногда требуется переименовать поля, чтобы обеспечить необходимые связи. Два поля могут иметь разные имена, хотя они обозначают одно и то же, например ID в таблице Customers (клиенты) и ID_Customer в таблице Orders (заказы). Очевидно, что оба имени обозначают определенный идентификационный код клиента и должны иметь вид ID клиента или аналогичный. Кроме того, два поля с одинаковыми именами могут в действительности иметь разные значения, например Date в таблице Invoices и Date в таблице Orders. Эти поля предпочтительнее переименовать в Date_Invoice и Date_Order или аналогичным образом. В базе данных могут также встречаться обычные опечатки или использоваться разные правила в отношении букв в верхнем и нижнем регистрах. Поскольку QlikView учитывает состояние регистра букв, важно внести исправления.
Поля можно переименовать в скрипте, поэтому не требуется изменять исходные данные. Это можно сделать двумя способами:
Способ 1 — В скрипте задать псевдоним полю при помощи фразы ‘as’:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
table2: LOAD * INLINE [ Key1, Key2, field3, field4 1, 101, удочка, хлеб 2, 102, крючки, колбаса 4, 104, нож, сыр ]; table3: Load Key1, Key2 as Key2_newName, field3, field4 Resident table2; DROP table table2; |
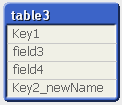
Способ 2 — Использовать оператор ALIAS:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
table1: LOAD * INLINE [ Key1, Key2, field1, field2 1, 101, Петр, Бондарчук 3, 103, Надежда, Филипова 4, 104, Сергей, Михайлов ]; ALIAS Key2 as Key2_newName; table2: LOAD * INLINE [ Key1, Key2, field3, field4 1, 101, удочка, хлеб 2, 102, крючки, колбаса 4, 104, нож, сыр ]; |
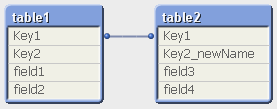
Оператор ALIAS используется для установки псевдонима, по которому будет переименовано поле при включении в скрипт. Синтаксис:
|
1 |
Alias ID_N as NameID; |
|
1 |
Alias A as Name, B as Number, C as Date; |
4) Составной ключ при помощи объединения полей
Составной ключ можно создать также при помощи склеивания двух полей:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
table1: LOAD * INLINE [ Key1, Key2, field1, field2 1, 101, Петр, Бондарчук 3, 103, Надежда, Филипова 4, 104, Сергей, Михайлов ]; table3: LOAD Key1&Key2 as GeneralKey, field1, field2 Resident table1; DROP Table table1; |
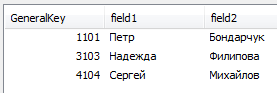
Что такое No Concatenate?
Префикс NoConcatenate определяет, что две таблицы с идентичными наборами полей (т.е. такие, которые были автоматически concatenated) должны обрабатываться как две отдельные внутренние таблицы. Синтаксис имеет следующий вид:
|
1 2 3 |
Load A,B from file1.csv; Noconcatenate Load A,B from file2.csv; |
Что такое P() и E() в Анализе множеств (Set analysis)?
Анализ Множеств (Set Analysis) — одна из основ для построения сложных приложений QlikView. Set Analysis содержит в себе подходы выделения области модели данных, к которым будут применяться вычислительные механизмы. Например, мы можем для конкретной диаграммы выделить область данных приложения, в которой содержатся покупки с продуктом «Йогурт Активия».
В тех случаях, когда множество значений нужно задать не явно, можно использовать функции P() и E().
P() — это множество возможных значений поля, для которых определена дополнительная вложенная выборка.
E() — множество исключенных значений поля, для которых определена дополнительная вложенная выборка.
- sum( {$} Customer)>} Sales ) — возвращает продажи для текущей выборки, но только клиентов, покупавших когда-либо продукт ‘Shoe’. Здесь функция элемента P( ) возвращает список возможных клиентов, подразумеваемых выборкой ‘Shoe’ в поле Product.
- sum( {$} Supplier)>} Sales ) — возвращает продажи для текущей выборки, но только клиентов, поставлявших когда-либо продукт ‘Shoe’. Здесь функция элемента P( ) возвращает список возможных поставщиков (supplier), подразумеваемых выборкой ‘Shoe’ в поле Product. Список поставщиков затем используется в качестве выборки в поле Customer.
- sum( {$})>} Sales ) — возвращает продажи для текущей выборки, но только клиентов, никогда не покупавших продукт ‘Shoe’. Здесь функция элемента E( ) возвращает список клиентов, исключенных выборкой ‘Shoe’ в поле Product.
Что такое сравнительный анализ (Comparative analysis)?
Сравнительный анализ — это механизм быстрого сопоставления нескольких выборок (альтернативных состояний), что позволяет легко выявлять тенденции, различия и аномальные значения, шаблоны и модели поведения, анализировать возможности и угрозы.
Сравнительный анализ — это создание диаграммы и списков, которые связаны с «Альтернативными состояниями». Диаграмма выполняет агрегирование по выборкам каждого альтернативного состояния. Таким образом у нас образуется гибкий инструмент сравнения N выборок. Можно сделать несколько групп в виде списков и настроить диаграмму на эти несколько списков.
Иллюстрация реализованного сравнительного анализа:
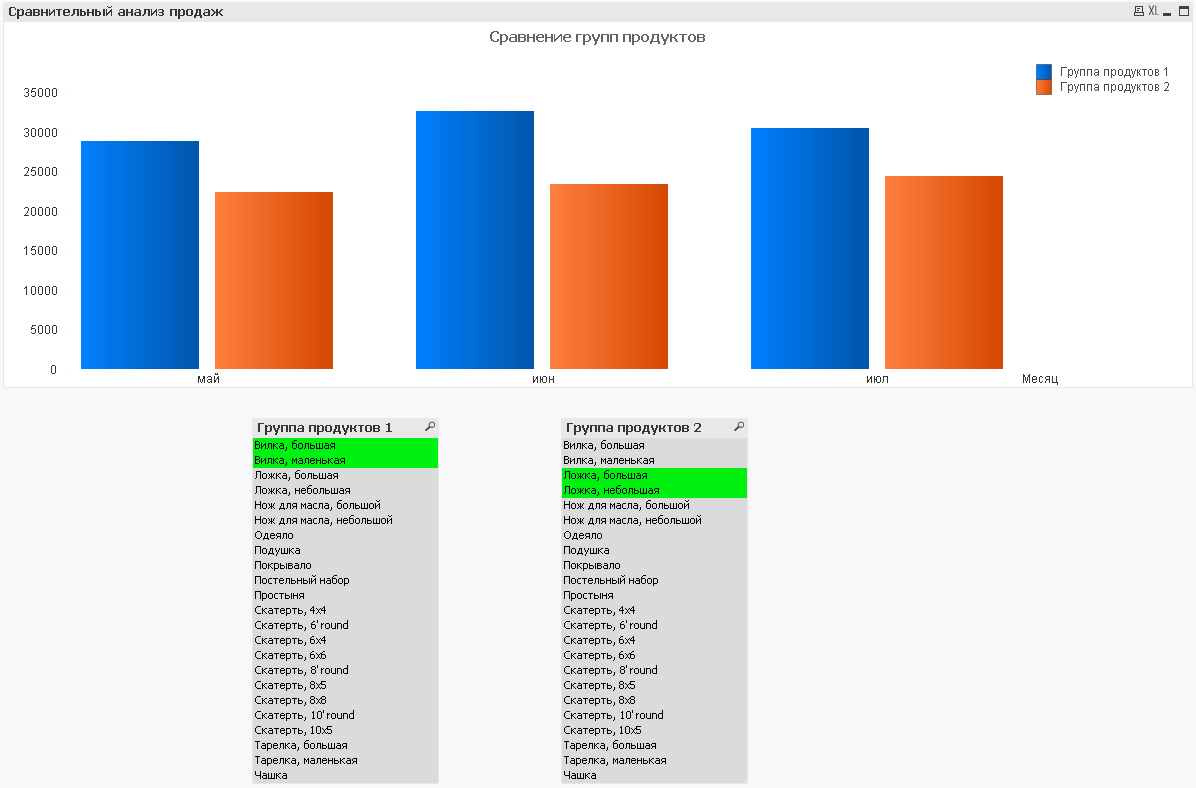
Подробнее смотрите информацию здесь: https://ivan-shamaev.ru/comparative-analysis-in-qlikview/
Что такое Mekko chart? И в чем разница между Bar и Mekko chart?
Диаграмма Мекко показывает распределение значений Expression по измерениям. Суммарное значение равно единице или 100%. При этом диаграмма визуально показывает распределение величин и по оси X и по оси Y.
На диаграмме Bar распределение характеризуется лишь по одной оси.
Пример:
|
1 2 3 4 5 6 7 8 9 10 11 |
[MarketRevenue]: Load * Inline [ "Бренд", "Выручка в России", "Выручка в Европе", "Выручка в США" Nike,1500,2700,1700 Reebok,2100,1200,2800 Adidas,2400,2500,1800 Fila,900,600,1100 Converse,1100,200,700 Другие,2000,2800,1900 ]; |
Исходная таблица:

Диаграмма Bar:

Диаграмма Mekko:
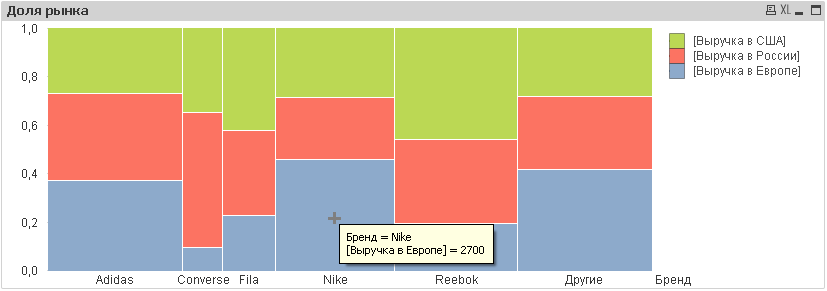
На диаграмме по оси X мы видим распределение всех брендов на каждом рынке, по оси Y видим распределение каждого бренда по рынкам. При этом мы можем визуально сравнивать площади квадратов, которые эквивалентны величинам выручки по брендам на каждом из рынков.
Вывод: в зависимости от целей анализа применяется тот или иной инструмент визуализации распределения данных. Диаграмма Bar визуализирует распределение данных по одной оси, а диаграмма Mekko визуализирует распределение данных по двум осям.
Кратко объясните как хранит данные QlikView внутри себя?
Хранение данных в QlikView
Хранение данных в приложениях QlikView организованно на двух уровнях. Первый уровень — это хранение отдельных списков значений. Второй уровень — сохраняет таблицы данных, состоящих из указателей (pointers).
Первый уровень хранения:
Существует ровно один список для каждого поля, который входит в документ. Т.е. если у Вас есть 25 полей в документе, то Вы будете иметь 25 списков. Списки заполняются во время перезагрузки данных. Следовательно, порядок значений отражает порядок загрузки данных.
Второй уровень хранения:
Второй уровень хранения в документе QlikView состоит из таблиц, которые содержат значения указателей (или NULL) в каждой ячейке. Эти значения указателей соответствуют «индексу» соответстующего значения в отдельных списках, расположенных на первом уровне хранения данных.
Пример расчета количества памяти для приложения QlikView
Рассмотрим ключевое поле, состоящее из потенциальных 550’000 различных значений в таблице фактов, которая содержит 100 миллионов строк данных.
Для расчета оперативной памяти, необходимой для этой области данных, мы должны рассмотреть хранение списка, а также таблицу хранения индексов (указателей).
Следует помнить, что это минимальные расчетные значения, т.к. существует, конечно, дополнительные потребности в RAM, которые QlikView может понадобиться для хранения данных.
Для данных списка, предположим, что каждое значение — это 10 байт символьного (текстового) представления.
Если мы умножим 10 байт на 550’000, то мы получим примерно 5,5 МБ. Это то значение оперативной памяти, которое требуется для сохранения списка, независимо от того, сколько раз это поле ссылается в логические таблицы.
Далее, мы должны вычислить RAM память для указателей (индексов), которая требуется для логических таблиц, включающие эти поля. Поскольку 550’000 уникальных значений могут быть представлены 20 битами (от 2 до 20 раз больше), то нам требуется 2.5 байта для каждой строки не пустых данных (non-null data).
Как уже упоминалось выше, у нас есть 100 миллионов строк данных в нашей таблице фактов. Умножим 100 миллионов строк на 2.5 байт — это 250 миллионов байт. То есть нам требуется приблизительно 250 МБ для сохранения указателей (pointers) для полей в логической таблице.
Итак, общий объем памяти, требуемый для одного поля в одной логической таблице, будет примерно равен 256 МБ. Поскольку это ключевое поле, по определению, оно существует более чем в одной логической таблице. Если мы исходим из таблицы измерения с одной строкой данных для каждого ключевого значения, то нам необходимо дополнительно 1.4 МБ для таблицы с измерениями для хранения указателей. Это добавляет около 258 МБ для этого отдельного поля, почти вся память из этого значения требуется для таблицы указателей.
Конечно, в документах с небольшими таблицами фактов (менее 1 млн строк), это не такая большая проблема. Но при работе с большими таблицами фактов, вы должны быть осведомлены о последствиях добавления и удаления полей.
Почему память так важна в QlikView?
Использование памяти — это только один аспект хорошей производительности QlikView документа. В 64-битной среде, RAM-память с одной стороны является безграничной.
Но даже 64-битные системы имеют ограниченный объем оперативной памяти, которая установлена, и большинство систем будут существовать с этим значением памяти довольно долго. Можно с уверенностью предположить, что данные пользователей, а в случае использования QlikView сервера — документов, продолжит расти.
Если предположить, что большой объем памяти не нужен, то для масштабирования может оказаться очень небольшой объем памяти.
Поэтому важно понимать, что ваши изначальные требования к RAM — будут являться той гранью, перейдя которую пользователи, как правило, начинают страдать.
В чем разница между Internal Table View и Source Table View?
Internal Table View (Отображение внутренних таблиц) — это вид по-умолчанию. Данный вид показывает, как QlikView сохраняет таблицы данных. Составные ключи формируются в таблицах, которые имеют более одного поля. Синтетические таблицы используются для соединения этих таблиц (которые имеют составные ключи). Этот вид является лучшим подходом к пониманию логики QlikView, а также обеспечивает понятное отображение, на котором каждая связь между таблицами имеет максимум один разъем между ними.
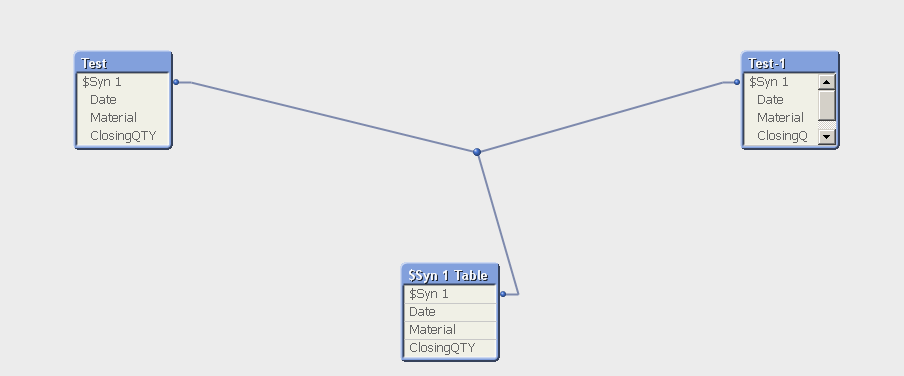
Source Table View (Отображение таблиц-источников) — это вид, который показывает как QlikView читает таблицы. Здесь нет синтетических полей или синтетических таблиц. Составные ключи представлены множественными соединительными линиями между таблицами.

В чем разница между элементами Pivot, Straight and Table box?
Таблицы являются наиболее простым способом представления данных. Существует три типа таблиц: table box, straight table и pivot table.
Table Box используется для отображения многомерных данных, например, для того, чтобы показать адресную книгу. В этой таблице нет расчетов (отсутствует exspressions).
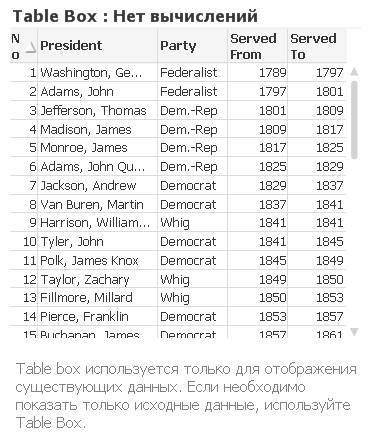
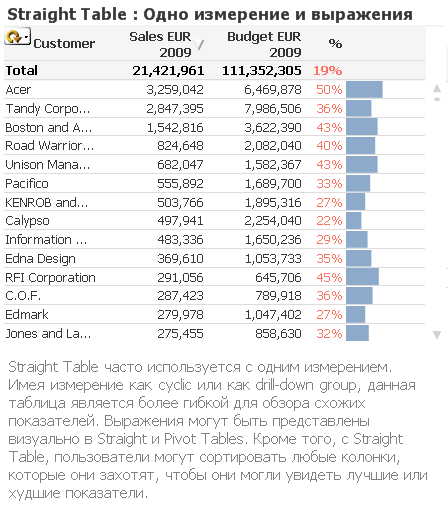
Straight Table используется, когда пользователю необходима сортировка. Straight Table часто используется с одним измерением с циклическими или drill-down возможностями, а также несколькими выражениями (expressions), чтобы пользователи могли видеть один и тот же набор метрик и сортировать их, как им это необходимо.
Pivot Table используется, когда необходима группировка измерений. Pivot Table также часто используется с промежуточными итогами.

Таблица сравнения элементов Table boxes, pivot tables and straight tables:
| Pivot Table | Straight Table | Table Box | |
| Тип объекта листа | Chart | Chart | Chart |
| Тип данных в таблице | Dimension + expression value (a) | Dimension + expression values | Field values (dimensions) |
| Можно ли делать выборки в поле? | Dimension values only | Dimension values only | Yes |
| Сортировка значений? | Limited to changing the settings for dimension values in Properties: Sort. | Yes, dimension + expression values | Yes |
| Быстрая сортировка в колонках? | No | Yes, dimension + expression values | Yes |
| Calculations/expressions? | Yes(a) | Yes | No |
| Группировка данных? | Yes | No | No |
| Частичные суммы? | Yes | No | No |
| Итоговые суммы? | Yes | Yes | No |
(a) Pivot Tables могут также быть использованы без каких-либо выражений для того, чтобы показать иерархию полей.
Table box — это объект листа, который показывает несколько полей одновременно. Содержание каждой строки логически связано (на отображение данных влияют взаимосвязи между таблицами). Колонки могут быть выбраны из различных внутренних таблиц, что позволяет пользователю создавать таблицы из любой возможной комбинации полей.
Chart (диаграмма) — это графическое представление числовых данных.
Pivot table (сводная таблица) и Straight table (прямая таблица) — это особые случаи диаграмм, которые отображают данных в виде таблицы и при этом пользователю доступны все свойства диаграммы. Можно менять различные представлениями существующего графика.
Pivot table — показывает измерения (dimensions) и выражения (expressions) в строках и колонках. Примером является cross table. Данные в pivot table могут быть сгруппированы. В pivot table можно показать частичные суммы.
В противоположность Pivot table, Straight table (прямая таблица) не может отображать промежуточные суммы или служить в качестве cross table (кросс-таблицы). С другой стороны, любой из ее столбцов могут быть отсортированы и каждая из ее строк содержит одну комбинацию измерение(-ия) + выражение(-ия).
Что такое cross table (кросс-таблица)?
Функция crosstable позволяет трансформировать таблицу источника данных в более компактный и более практичный вид, переводя несколько одинаковых по смыслу столбцов в один столбец. Иллюстрация работы функции приведена на картинке:

Пример кросс-таблицы:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
TempTable: LOAD * INLINE [ Sales Rep, Q1 2010, Q2 2010, Q3 2010, Q4 2010, Q1 2011, Q2 2011, Q3 2011, Q4 2011 Bill, 31062, 94237, 85468, 59382, 93600, 38213, 3446, 48289 Tommy, 68273, 89995, 63552, 83608, 39752, 9480, 81782, 63775 Ralph, 60338, 21474, 80148, 20073, 88084, 9055, 99437, 25050 Mary, 48154, 86928, 11929, 19278, 7894, 26565, 30937, 62003 Melissa, 49838, 18578, 50878, 98382, 46908, 73529, 55971, 8397 ]; CrossTable(Quarter, Sales) LOAD [Sales Rep], [Q1 2010], [Q2 2010], [Q3 2010], [Q4 2010], [Q1 2011], [Q2 2011], [Q3 2011], [Q4 2011] Resident TempTable; DROP Table TempTable; |
Результат выполнения функции, является следующая таблица:

Если у Вас есть два различных показателя для каждого месяца, например, количество и сумма, то нужно произвести загрузку данных в две кросс-таблицы:
|
1 2 3 4 5 6 7 |
Crosstable (Month, Sales) Load Product, [Sales Jan 2014] as [Jan 2014], [Sales Feb 2014] as [Feb 2014],… From … ; Crosstable (Month, Units) Load Product, [Units Jan 2014] as [Jan 2014], [Units Feb 2014] as [Feb 2014],… From … ; |
Способы подключения к различным источникам данных в QlikView?
Базовыми способами для подключения QlikView к базе данных, являются:
- Использование драйвера Object Linking and Embedding Database (OLE DB);
- Использование драйвера Open Database Connectivity (ODBC);
OLEDB — это набор низкоуровневый интерфейсов Component Object Model (COM), которые позволяют обращаться к данным, которые хранятся в разных источниках информации. С помощью OLEDB можно обращаться к следующим источникам данных:
- базы данных типа IMS DB2 (базы данных для mainframe);
- базы данных ORACLE, MS SQL SERVER, IBM DB2, MySQL;
- базы данных ACCESS, Paradox, FoxPro;
- файловая система NTFS или UNIX;
- системы электронной почты типа Exchange;
- индексно-последовательные файлы (текстовые файлы и электронные таблицы);
- многие другие данные…
Главное отличие от ODBC состоит в том, что ODBC была создана только для доступа к реляционным данным, а вот OLEDB может подключаться к любым данным.
OLEDB состоит из 3 компонентов:
- data consumers — потребители данных;
- data provides — провайдеры данных;
- service components — сервисные компоненты.
ODBC (Open Database Connectivity) — программный интерфейс API для доступа к базам данных (СУБД), которые поддерживают этот стандарт. Программный интерфейс разработан фирмой Microsoft. При использовании ODBC клиенту не обязательно знать с какой СУБД (Oracle, MS SQL, Access) он работает.
QlikView работает с 32-разрядными и 64-разрядными ODBC драйверами, поэтому очень важно соблюдать соответствие версий драйверов ODBC и программ. 32-разрядная версия QlikView совместима только с 32-разрядными драйверами ODBC. 64-битная версия совместима как с 32-разрядными, так и с 64-разрядными драйверами ODBC.
Для настройки OLE DB и ODBC в QlikView предусмотрен специальный инструмент настройки, вызвать который можно из Edit Script:

В QlikView имеется возможность загружать данные из следующих типов файлов:
- Delimited (csv, txt, tab, qvo, mem, skv, prn, log);
- Fixed (fix, dat);
- Dif (dif);
- Excel (xls, xlsx, xlw, xlsm);
- Html (html, htm, php);
- QlikView Data Files (qvd);
- QlikView Data Exchange Files (qvx);
- Xml (xml).

Бинарная загрузка данных:
- QlikView Documents (qvw).

Дополнительно присутствует настройка загрузки данных из Web Files и Field Data:
Что такое частичная перезагрузка (partial reloading)?
Частичная перезагрузка используется тогда, когда Вам необходимо добавить таблицу в модель без перезагрузки всех существующих таблиц (либо когда требуется заменить данные в одной существующей таблице).
Предположим, что в вашем файле QlikView есть 10 таблиц, в которых существуют миллионы записей. Если Вы хотите добавить одну новую таблицу, то Вам требуется добавить в скрипт соответствующий участок и затем перезагрузить существующие 10 таблиц, а также новую таблицу. Это займет очень много времени (если Ваша модель содержит сравнимое количество данных). В случае, если Вы хотите перезагрузить только новую таблицу, то следует использовать Partial Reload. Частичную загрузку можно произвести с помощью атрибута ADD или REPLACE в LOAD statement.
Пример написания:
|
1 2 3 4 5 6 |
ADD LOAD StudentName, City, EmpId FROM [C:\Name2.xls] (biff, embedded labels, table is Sheet1$); |
Запуск частичной загрузки осуществляется из меню:
Какие различные join доступны в QlikView?
Рассмотрим различные варианты join, которые используются в скриптах QlikView. Примем, что мы объединяем первую таблицу с помощью join со второй таблицей.
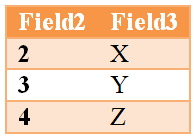
Таблица 1:
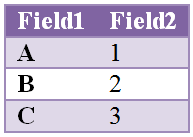
Таблица 2:
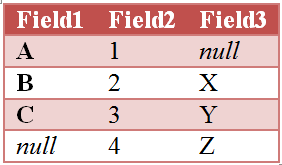
JOIN (OUTER JOIN): При таком способе соединения двух таблиц, в результирующую таблицу попадают все записи из первой и второй таблицы. При этом записи, у которых ключевые поля совпадают — будут объединены, а записи, у которых ключевые поля разные, будут иметь пропуски по не общим полям. При использовании JOIN по умолчанию применяется тип объединения таблиц OUTER JOIN.
|
1 2 3 4 5 6 7 8 9 10 11 |
MyTable: LOAD Field1, Field2 FROM myqvd1.qvd (qvd); OUTER JOIN (MyTable) LOAD Field2, Field3 FROM myqvd2.qvd (qvd); |
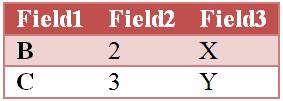
INNER JOIN: При данном способе объединения таблиц в результирующую таблицу попадут только те строки из первой и второй таблицы, у которых одинаково названные поля имеют идентичные значения (т.е. ключевые поля совпадают по значениям).
|
1 2 3 4 5 6 7 8 9 10 11 |
MyTable: LOAD Field1, Field2 FROM myqvd1.qvd (qvd); INNER JOIN (MyTable) LOAD Field2, Field3 FROM myqvd2.qvd (qvd); |
LEFT JOIN: При данном способе соединения таблиц, в результирующей таблице будут присутствовать все записи из первой таблицы и только те записи из второй таблицы, которые совпадают по общим полям с первой таблицей. Общие поля автоматически определяются по идентичным названиям.
|
1 2 3 4 5 6 7 8 9 10 11 |
MyTable: LOAD Field1, Field2 FROM myqvd1.qvd (qvd); LEFT JOIN (MyTable) LOAD Field2, Field3 FROM myqvd2.qvd (qvd); |
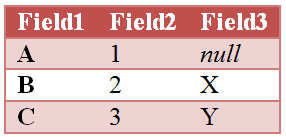
RIGHT JOIN: При данном способе соединения таблиц, в результирующей таблице будут присутствовать все записи из второй таблицы и только те записи из первой таблицы, которые совпадают по общим полям со второй таблицей. Общие поля автоматически определяются по идентичным названиям.
|
1 2 3 4 5 6 7 8 9 10 11 |
MyTable: LOAD Field1, Field2 FROM myqvd1.qvd (qvd); RIGHT JOIN (MyTable) LOAD Field2, Field3 FROM myqvd2.qvd (qvd); |

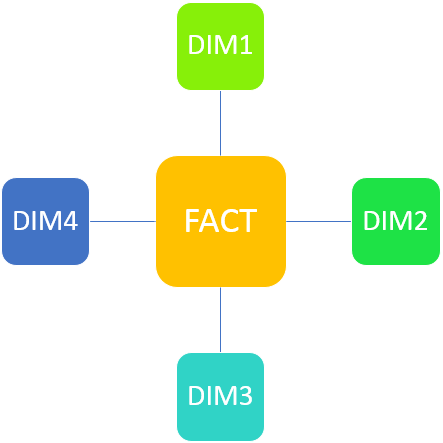
В чем разница между Star и Snoflake схемами?
Схема «Звезда»: в схеме «Звезда» таблица фактов находится в центре и подключена к таблицам с измерениями. Таблицы полностью соответствуют денормализованной структуре данных. Запросы к данным имеют очень хорошую производительность. Избыточность данных высока и занимает много места на диске.
Большим преимуществом данной схемы является то, что бизнес-пользователи могут легко понять взаимосвязи между таблицами, а соответственно и бизнес-логику модели.
Схема модели данных:
Пример из документа QlikView:
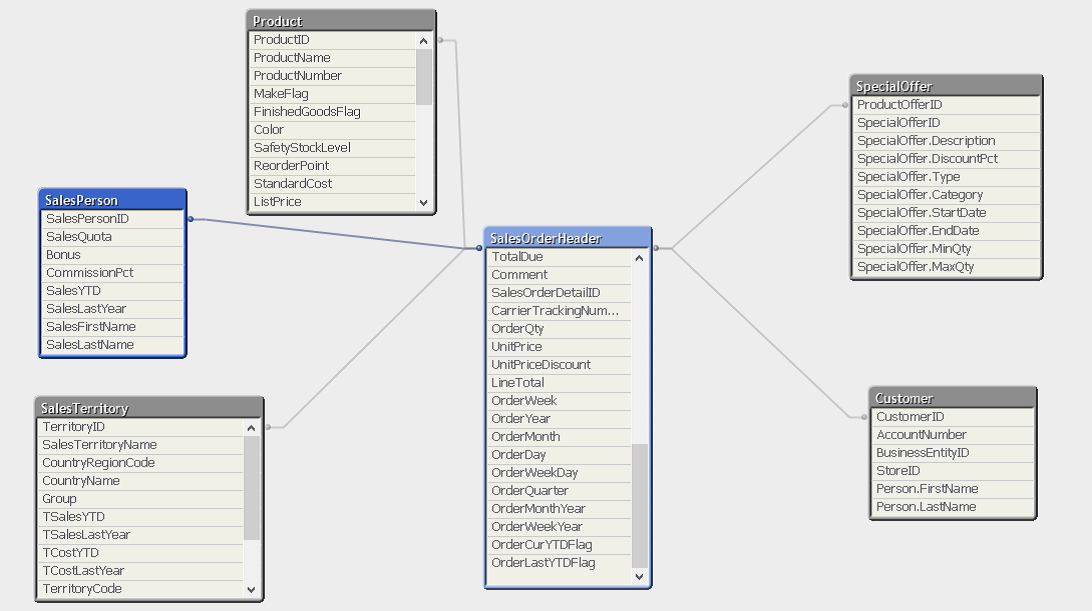
Схема «Снежинка»: это расширение схемы «Звезда», в которой таблицы измерений дополнительно соединены с другими измерениями. Таблицы представляют частично денормализованную структуру. Производительность запросов ниже, по сравнению с производительностью схемы «Звезда». Избыточность данных ниже, поэтому требуется меньшее количество памяти.
Особенностью схемы «снежинка» является то, что таблицы измерений могут быть соединены с таблицами измерений других иерархических уровней непосредственно, минуя таблицу фактов. Поэтому данную схему рекомендуется использовать при наличии иерархии измерений.
Схема модели данных:
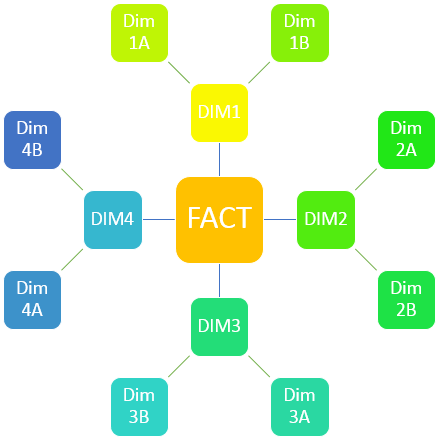
Пример из документа QlikView:

Как и для чего используются макросы (Macro) в QlikView?
Рассмотрим вызов макроса при помощи кнопки. Создадим объект листа “Button” и зайдем в свойства кнопки. На вкладке “Actions” добавляем тип события “External->Run Macro”
Для того, чтобы зайти в интерфейс написания макроса, необходимо нажать кнопку “Edit Module…”:
В QlikView доступны два вида языка, на которых можно написать макросы (VBScript и JScript):
Макросы, написанные на VBScript внутри приложения QlikView, могут быть вызваны в качестве триггера на определенные действия или события.
События приложения:
1. Макрос может быть запущен после открытия документа QlikView.
2. Макрос может быть запущен после перезапуска скрипта загрузки данных.
3. Макрос может быть запущен после запуска команды Reduce Data.
4. Макрос может быть запущен после установки выборки в любом поле приложения.
События листа:
5. Макрос может быть запущен после активации листа.
6. Макрос может быть запущен когда лист деактивируется.
События объектов листа:
7. Макрос может быть запущен после активации объекта листа.
8. Макрос может быть запущен, когда объект листа деактивируется.
События кнопки:
9. Объект листа «Кнопка» может ссылаться на макрос.
События поля:
10. Макрос может быть запущен после того, как сделана выборка в конкретном поле.
11. Макрос может быть запущен, когда выборка сделана в любом поле логически связанном с конкретным полем.
12. Макрос может быть запущен после того, как выборка была заблокирована в конкретном поле.
События переменных:
13. Макрос может быть запущен после того, как присвоено значение в указанную переменную.
14. Макрос может быть запущен, когда значение конкретной переменной, содержащей формулу, было изменено.
Что такое Peek, Previous, Apply map, Interval Match?
Функция Peek()
Peek: Функция, которая возвращает значение из поля в ходе загрузки данных. Можно сослаться на строку конкретного номера. Например, получить продажи из второй строки конкретной таблицы.
Синтаксис:
|
1 |
peek(fieldname [ , row [ , tablename ] ]) |
Возвращает содержимое поля fieldname. Номер записи задается с помощью row, имя таблицы tablename. Данные выбираются из ассоциативной базы данных QlikView (то есть необходимо, чтобы данные были загружены в QlikView).
Row должно быть целым числом. 0 — обозначает первую запись, 1 — вторую и т.д. Отрицательные числа указывают порядок с конца таблицы. -1 обозначает последнюю прочитанную запись. Если row не указано, то по умолчанию значение равно -1, т.е. берется последняя прочитанная запись.
Tablename — это метка таблицы, если tablename не указано, то берется текущая таблица.
Примеры:
- LET vSales = peek(‘Sales’); — возвращает последнее прочитанное значение из поля Sales.
- LET vSales = peek(‘Sales’, 2) — возвращает третье значение из поля Sales.
- LET vSales = peek(‘Sales’, -2) — возвращает второе значение с конца таблицы из поля Sales.
Замечание: Peek функция очень полезна при создании календаря.
Функция Previous()
Previous: Функция, которая возвращает более ранние записи.
Синтаксис:
|
1 |
previous(expression) |
Возвращает значение expression ранее загруженной записи, которая не была Для первой записи функция возвращает NULL.
Функцию previous можно использовать для того, чтобы получить доступ к более ранним записям. Данные выбираются из источника ввода напрямую, что также позволяет сослаться на поля, которые не были загружены в QlikView, т.е. даже если они не хранились в ассоциативной базе данных.
Сравнение функций peek и previous
- Функции Previous() и Peek() могут быть использованы, когда пользователю необходимо сравнить текущее значение и предыдущее значение поля, которые были загружены из исходного файла.
- Функция Peek() лучше подходит для тех задач, когда пользователю необходимо нацелиться на определенную строку в таблице.
Рассмотрим пример:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
[Таблица Чеков]: LOAD * INLINE [ ID Чека, Дата покупки, Сумма чека 1001, 01.06.2015, 1090 1002, 01.06.2015, 2150 1003, 01.06.2015, 190 1004, 01.06.2015, 1740 1005, 01.06.2015, 358 1006, 02.06.2015, 267 1007, 02.06.2015, 960 1008, 02.06.2015, 2100 1009, 02.06.2015, 670 1010, 02.06.2015, 1390 1011, 02.06.2015, 780 1012, 02.06.2015, 340 1013, 03.06.2015, 750 1014, 03.06.2015, 280 1015, 03.06.2015, 1100 1016, 03.06.2015, 690 1017, 04.06.2015, 870 1018, 04.06.2015, 1870 1019, 04.06.2015, 990 1020, 04.06.2015, 1320 ]; [Сумма покупок за день]: LOAD [ID Чека], [Дата покупки], [Сумма чека], [Сумма чека]/Previous([Сумма чека]) as [Previous], [Сумма чека]/Peek([Сумма чека],-2) as [Peek] Resident [Таблица Чеков] Order BY [ID Чека] ; DROP Table [Таблица Чеков]; |
Результирующая таблица:
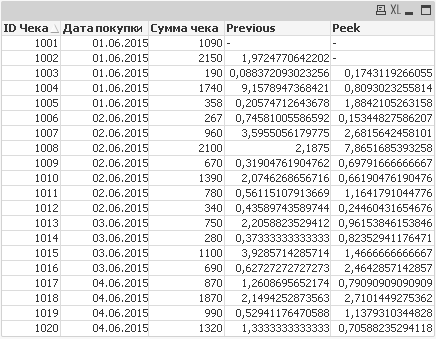
Получается, что Previous возвращает предыдущее загруженное значение, в то время, как Peek возвращает либо предыдущее значение, либо конкретно заданную строку. Причем если задать значение строки -2, то это будет означать, что берется -2 строка с конца таблицы в каждый момент времени.
Например, разберем работу функции Peek на 12 строке:

Функция ApplyMap
ApplyMap: Функция ApplyMap используется для сопоставления выражений с загруженной таблицей сопоставления.
Синтаксис имеет следующий вид:
|
1 |
applymap('mapname', expr [ , defaultexpr ] ) |
, где
mapname — имя таблицы сопоставления, созданной ранее с помощью операторов mapping load или mapping select. Это имя должно быть заключено в одинарные прямые Кавычки.
expr — выражение, результат которого должен быть сопоставлен.
defaultexpr — дополнительное выражение, используемое как значение сопоставления по умолчанию, если таблица сопоставления не содержит совпадающего значения для expr. Если значение по умолчанию не задано, то значение expr выводится как есть.
Пример: Пусть у нас есть таблица сопоставления map1
|
1 2 3 4 5 6 |
map1: mapping load * inline [ x, y 1, one 2, two 3, three ] ; |
Рассмотрим результат работы функции ApplyMap:
- ApplyMap (‘map1’, 2 ) выдает ‘ two’;
- ApplyMap (‘map1’, 4 ) выдает 4;
- ApplyMap (‘map1’, 5, ‘xxx’) выдает ‘xxx’;
- ApplyMap (‘map1’, 1, ‘xxx’) выдает ‘one’;
- ApplyMap (‘map1’, 5, null( ) ) выдает NULL;
- ApplyMap (‘map1’, 3, null( ) ) выдает ‘three’.
Функция IntervalMatch()
IntervalMatch: Префикс IntervalMatch для операторов load или select используется для связывания дискретных числовых значений с одним или несколькими числовыми интервалами. То есть, если у нас есть две таблицы, в одной находятся интервалы времени, а в другой время того или иного события, то функция IntervalMatch сможет помочь связать время события с временными интервалами.
Пример:
Пусть первая таблица содержит время начала и конца выполнения различных заказов. Во второй таблице заданы некоторые отдельные события:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
[Журнал сортировки]: LOAD * INLINE [ Начало, Окончание, Порядок 01:00, 03:35, A 02:30, 07:58, B 03:04, 10:27, C 07:23, 11:43, D ]; [Журнал событий]: LOAD * INLINE [ Время, Событие, Комментарии 00:00, 0, Начало смены 1 01:18, 1, Остановка линии 02:23, 2, Перезапуск линии 50% 04:15, 3, Скорость линии 100% 08:00, 4, Начало смены 2 11:43, 5, Конец выполненния ]; |
После запуска скрипта, в QlikView образовались две таблицы:

Добавляем функцию IntervalMatch к существующему скрипту:
|
1 2 |
[Таблица соединения]: Intervalmatch ([Время]) LOAD [Начало],[Окончание] Resident [Журнал сортировки]; |
После запуска скрипта, создается [Таблица соединения] интервалов и времени событий. При этом для связи с таблицей [Журнал сортировки] будет создан синтетический ключ:
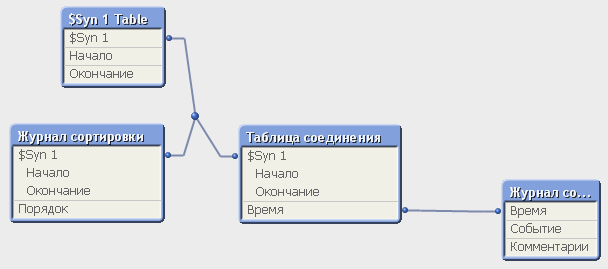
Для того, чтобы избавиться от синтетического ключа, необходимо преобразовать скрипт загрузки с помощью генерации составного ключа. Это делать не обязательно. В данном случае синтетический ключ правильно функционирует. Но для общего развития, я приведу пример, как можно избавиться от синтетического ключа.
Применим функцию AutoNumberHash128:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
[Журнал сортировки]: LOAD * INLINE [ Начало, Окончание, Порядок 01:00, 03:35, A 02:30, 07:58, B 03:04, 10:27, C 07:23, 11:43, D ]; INNER JOIN LOAD DISTINCT [Начало], [Окончание], AutoNumberHash128([Начало],[Окончание]) as [Интервал времени] Resident [Журнал сортировки]; [Журнал событий]: LOAD * INLINE [ Время, Событие, Комментарии 00:00, 0, Начало смены 1 01:18, 1, Остановка линии 02:23, 2, Перезапуск линии 50% 04:15, 3, Скорость линии 100% 08:00, 4, Начало смены 2 11:43, 5, Конец выполненния ]; [Таблица соединения]: Intervalmatch ([Время]) LOAD [Начало] as [Начало интервала],[Окончание] as [Окончание интервала] Resident [Журнал сортировки]; INNER JOIN LOAD DISTINCT [Начало интервала], [Окончание интервала], AutoNumberHash128([Начало интервала],[Окончание интервала]) as [Интервал времени] Resident [Таблица соединения]; |
В итоге мы получим довольно простую связку между двумя таблицами:
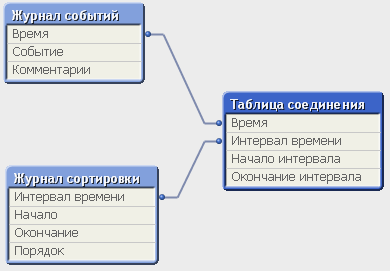
Содержание таблиц будет следующим:
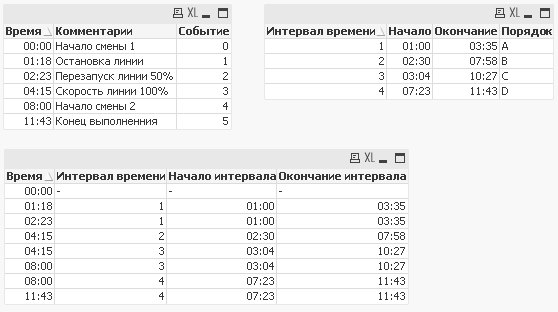
При использовании оператора IntervalMatch обратите внимание на следующие моменты:
- До оператора IntervalMatch поле, которое содержит дискретные значения данных ([Время] в приведенных выше примерах), уже должно быть считано в QlikView. Оператор IntervalMatch сам не считывает это поле из таблицы базы данных!
- Таблица, считанная с помощью оператора IntervalMatch load или select , должна содержать ровно два столбца (Начало и Окончание в примере, приведенном выше). Для установки связи с другими полями необходимо выполнить считывание из поля интервала, а также других дополнительных полей с помощью отдельного оператора load или select (первый оператор select в указанном выше примере).
- Интервалы всегда закрытые, т.е. конечные точки включены в интервал. Нечисловые пределы выводят игнорируемый интервал (неопределенный), а интервалы со значением NULL расширяют интервалы до неопределенных значений (неограниченные интервалы).
- Интервалы могут накладываться друг на друга, а дискретные значения будут связаны со всеми соответствующими интервалами.
Какие пути оптимизации дашбордов (dashboards) существуют в QlikView?
1. Насколько велики Ваши графики (charts)?
Если у Вас есть детальные straight table, которые содержат сотни тысяч или миллионов строк, Вы можете добавить условие в расчеты, которые будут требовать от пользователей сделать выборки данных (применить фильтры) для того, чтобы ограничить количество строк в расчете.
Условие задается в формате: Count(ProductCategory)<1000. Когда категория товаров не ограничена в существующем фильтре, то график не будет загружаться. При этом будет отображаться запись: «Невозможно отобразить (>1000 строк)».
2. Присутствуют ли в модели синтетические ключи?
QlikVIew при обработке синтетических ключей теряет в производительности. Желательно избавляться от синтетических ключей, создавая комбинированные (составные) ключи.
3. Сколько IF условий содержатся в ваших графиках (в выражениях)?
QlikView работает быстро, т.к. загружает все данные в RAM память. При использовании в диаграммах условий IF, падает производительность. Для улучшения производительности приложений, используйте Set Analysis. Также можно для выражений, у которых имеются if условия, добавлять condition с помощью функции GetFieldSelections(Field1)=’Value’. Этот подход включает выражение только, когда условие выполняется.
4. Насколько велико приложение QlikView?
При большом приложении требуется большой объем оперативной памяти. При необходимости необходимо сокращать размер модели.
Базовая формула, которая может быть использована для определения объема RAM памяти, которое необходимо для приложения:
Для каждого QVW файла
((Size of Disk) * 4) + (Size of Disk * 4) * 0,05 * (Number of Concurrent Users)
Пример расчета:
- Размер источника данных = 50GB
- Степень сжатия = 90%
- Размер файла = 4 для множителя
- Коэффициент пользователя = 5%
- Одновременно работающие пользователи = 50
*Обратите внимание, что Concurrent Users — это одновременно работающие пользователи, а не общее число пользователей.
Размер на диске для приложения QlikView: (50GB * (1-0.9)) = 5GB
RAM = (5GB * 4) + (5GB * 4) * 0.05 * 50 = 70GB для 50 одновременно работающих пользователей
5. Можно использовать инструмент Qlikview Governance Dashboard для оптимизации работы Dashboard.
QlikView Governance Dashboard помогает ИТ-специалистам оптимизировать работу QlikView.
6. Оптимизация работы QlikView может быть проведена на трех уровнях.
Уровни оптимизации работы QlikView:
- Уровень сервера;
- Уровень Скрипта загрузки;
- Дизайн приложения.
На уровне сервера: Вы можете выполнить оптимизацию с помощью балансировки загрузки. Большой файл QVW ломается на более мелкие файлы (техника “document chain”) и используются техники большего сжатия данных.
Кластеризация осуществляется на стороне Publisher.
На уровне скрипта загрузки: Вы можете удалить синтетические ключи, удалить временные таблицы, оптимизировать сложные выражения в диаграммах. Большие выражения или вычисления существенно снижают работу.
На уровне дизайна: Вы можете использовать автоматическую минимизацию диаграммы. Это позволяет снизить использование памяти.
Что такое Slowly Changing Dimensions (SCD)?
При создании приложений QlikView каждый иногда сталкивается с проблемой моделирования данных, в которых атрибуты измерений меняются с течением времени. Примером данных изменений может являться переход продавца из одного департамента в другой, или когда продукт переходит из одной категории товаров в другую категорию. Данная проблема называется — медленно меняющиеся измерения (Slowly Changing Dimensions, SCD). Данная задача возникает для любого инструмента Business Intelligence (BI). Создание приложения со статическими измерениями является достаточно простой задачей, но когда в каком-то измерении случаются изменения, то необходимо продумать, как спроектировать модель данных.
Прежде всего, изменяемый атрибут должен быть записан таким образом, чтобы исторические данные сохранялись. Если старое значение заменяется новым, то спасти ситуацию нет возможности:

В таком случае, новое значение атрибута будет использоваться также для старых транзакций, поэтому число продаж в некоторых случаях будет ошибочно отнесено к другому отделу. Однако, если изменения были записаны в другом виде, то QlikView может отображать изменения правильно. Как правило, исторические данные хранятся и изменяются путем добавления новых записей в базу данных для каждой новой ситуации с датой изменения, которая как раз и определяет начало и окончание срока действия.
Например для продавца, Вы можете построить схему из четырех таблиц, которые необходимо правильно соединить между собой: таблица транзакций, Таблица продавцов, таблица департаментов, таблица динамической связки продавцов и департаментов. Чтобы правильно связать таблицы, необходимо связать дату транзации и интервал в таблице динамической связки продавцов и департаментов.
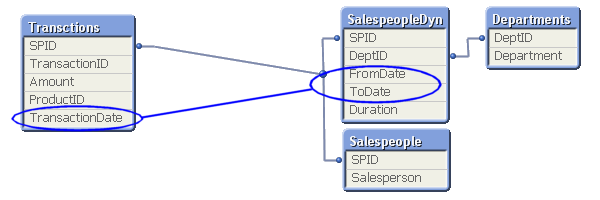
Данное решение возможно с помощью функции IntervalMatch. В ходе данного подхода создается связующая таблица (мостик, между двумя таблицами). Дополнительно, ID продавца должен существовать только в таблицах измерений и, следовательно, должен быть удален из таблицы транзакций.
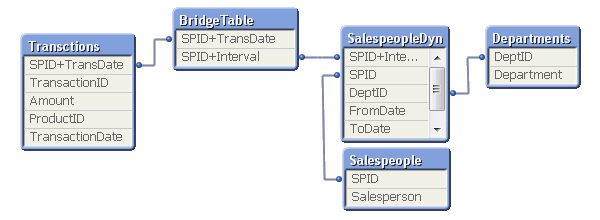
В большинстве случаев, медленно меняющиеся измерения, такие как продавцы, продукты, клиенты и т.д., могут принадлежать только одному отделу/категории продукции/региону/т.д. одновременно. Другими словами, отношения между продавцм и временными интервалами многие-к-одному. Если это так, то Вы можете хранить interval key прямо в таблице транзакций, чтобы упростить модель данных, например применив Join таблицы BridgeTable в таблицу с транзакциями Transctions.
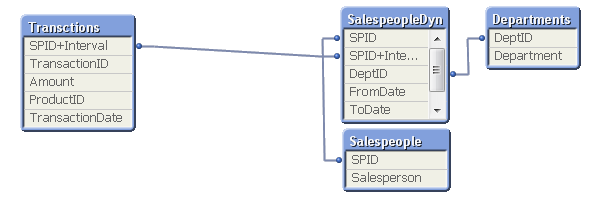
Внимание! Перед тем, как делать join, необходимо проверить, чтобы сотрудник не принадлежал к одному и тому же подразделению.
В чем разница между Pick и Match?
Функция Pick()
Синтаксис:
|
1 |
pick(n, expr1 [, expr2 ,..., exprN]) |
Возвращает значение n-го выражения в списке значений, где n — целое число от 1 до N. N — количество указанных значений. Работает схоже с функцией INDEX в Excel. Можно прописывать либо формулы, либо строки, либо числовые значения.
Пример:
|
1 |
LET vTextVariable = pick( 2,'A','B',3,'D','F',6); |
В данном примере vTextVariable значений будет иметь значение ‘B’.
|
1 |
Pick(2, SUM(1+1), SUM(2+2)) |
Данное выражение вернет значение 4 (результат применения функции SUM(2+2)=4).
Где функция Pick() используется:
- В случае, если необходимо избежать вложенных IF заявлений;
- Выражения динамического Set Analysis.
Функция Match()
Синтаксис:
|
1 |
match( str, expr1 [ , expr2 ,..., exprN ] ) |
Функция Match выполняет сравнение строки со значениями в списке с учетом регистра, возвращает целочисленное значение. Т.е. по сравнению с функцией pick, функция match производит обратное действие.
Пример:
|
1 |
match( Month, 'Янв','Фев','Мар') |
- возвращает 2, если Month = Фев;
- возвращает 0, если Month = ‘Апр’ или ‘янв’.
Функции Pick и Match можно использовать совместно, например:
Комбинация функций Pick() и Match() может быть использована как оператор управления Switch Case (т.е. задать сценарий вычисления в зависимости от значения той или иной переменной).
|
1 2 3 4 5 6 7 |
pick( match(KPI_Stock_PTF, 'String_1' ,'String_2', ... ,'String_N'), sum_expression_1, sum_expression_2, ... , sum_expression_N ) |
Что такое нечеткий поиск (fuzzy search)?
Нечеткий поиск выполняется так же, как и стандартный, за исключением того факта, что при нечетком поиске выполняется сравнение и сортировка всех значений полей по степени соответствия строке поиска. Нечеткий поиск особенно полезен в ситуациях, когда на результат поиска могут повлиять орфографические ошибки. Он также позволяет найти несколько схожих между собой значений. При выполнении нечеткого поиска перед строкой поиска отображается символ «~» тильда. Если текстовый поиск начинается со знака тильды «~», то окно текстового поиска будет работать в режиме нечеткого поиска.
При вводе все значения будут отсортированы по степени сходства со строкой поиска, наиболее сходные значения будут отображаться вверху списка. При нажатии клавиши Enter будет выбрано первое значение в списке.

<<< Вернуться в основной раздел «QlikView — краткий учебник»

