В данной статье будет описан пример парсинга товаров из интернет-магазина на Python Grab.
Парсинг я делал через файлы, чтобы во время падения парсинга начинать все с места, на котором все обвалилось.
Основы по инсалляции Python и библиотеки Grab можно почитать в статье Python + Grab инсталляция и настройка >>
Парсинг информации с сайтов может использоваться для различных целей:
- Получение свежих новостей;
- Получение данных с конкурентов (в том числе мониторинг цен, новости, деловая активность конкурента из СМИ и деловых порталов и т.д.);
- Получение статистических данных с сайтов, у которых нет API.
Страница в интернете — это html код. Он состоит из тегов, которые заключены в скобки . Для удобного разбора и поиска интересующих данных используется специальный язык запросов XPath (XML Path Language). Т.к. html является подмножеством XML, то XPath можно использовать и для HTML. HTML имеет древовидную структуру, в которой таги — это узлы дерева. А XPath предоставляет простой способ для поиска тегов по их взаимному расположению в таком дереве и/или по значению атрибутов тегов.
Шаг 1. Создаем главный файл со ссылками на товары ‘oboi_productURL.txt’:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
from grab import Grab g = Grab() cataloglist=[] startURL='http://interyerus.ru/oboi/variant/detskaya/' cataloglist.append(startURL) #print('startURL:' + startURL) #print('cataloglist[0]:' + cataloglist[0]) flag = 0 while flag > -1: g.go(cataloglist[flag]) nextURL = g.xpath_list('//div[@class="pager"]/ul/li[@class="next"]/a/@href') if nextURL: cataloglist.append('http://interyerus.ru' + nextURL[0]) #print(cataloglist[flag]) flag = flag + 1 else: flag = -1 #print(cataloglist) #write to file all url with spalnya product f = open('oboi_URL.txt', 'w') for q in range(0, len(cataloglist),1): f.write( str(cataloglist[q]) + '\n' ) f.close() productlist = [] for j in range(0, len(cataloglist),1): g.go(cataloglist[j]) urllist = g.xpath_list('//div[@class="product column"]/a[@class="product--name nova text-center"]/@href') for k in range(0, len(urllist),1): productlist.append('http://interyerus.ru' + str(urllist[k]) ) #write all product spalnya f = open('oboi_productURL.txt', 'w') for q in range(0, len(productlist),1): f.write( str(productlist[q]) + '\n' ) f.close() |
Шаг 2. Создаем файл с данными по продуктам с ценами и характеристиками ‘oboi_product_with_price.txt’:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 |
from grab import Grab g = Grab() with open('oboi_productURL.txt') as f: urlFile= f.readlines() f.close f = open('oboi_product_with_price.txt', 'w') for i in range(0, len(urlFile),1): g.go(urlFile[i]) try: ProductParse = str(urlFile[i].rstrip('\n')) Name = g.xpath_text('//header[@class="card-heading"]/h1[@itemprop="name"]') Artikul = g.xpath_text('//header[@class="card-heading"]/span[@class="art"]') Description = g.xpath_text('//div[@itemprop="description"]') Price = g.xpath_text('//div[@class="card--price"]/div/span') #print(Price) #get main image ImageMainFull = 'http://interyerus.ru' + g.xpath_text('//div[@class="card--image"]/a[@class="j-pswp-card-gallery"]/@href') ImageBig = 'http://interyerus.ru' + g.xpath_text('//div[@class="card--image"]/a/img[@itemprop="image"]/@src') #++++++++++++++++++++++++++ #++++++++++++++++++++++++++ ProductParse = ProductParse + '|' + Name.encode('utf-8') + '|' + Artikul.encode('utf-8') + '|' + Price.encode('utf-8') + '|' + Description.encode('utf-8') + '|' + ImageMainFull.encode('utf-8') + '|' + ImageBig.encode('utf-8') #get interer image ImagesInterery = g.xpath_list('//div[@class="carousel-container"]/ul[@class="carousel j-pswp-images"]/li/a[@class="j-photos-carousel-item"]/@href') strImagesInterery = '' for l in range (0, len(ImagesInterery), 1): strImagesInterery = strImagesInterery + 'http://interyerus.ru' + str(ImagesInterery[l]) + ';' #++++++++++++++++++++++++++ #++++++++++++++++++++++++++ ProductParse = ProductParse + '|' + strImagesInterery #other color product type OtherColorProduct = g.xpath_list('//div[@id="colors-carousel"]/div/ul/li/a/@href') strOtherColorProduct = '' for l in range (0, len(OtherColorProduct), 1): strOtherColorProduct = strOtherColorProduct + 'http://interyerus.ru' + str(OtherColorProduct[l]) + ';' #++++++++++++++++++++++++++ #++++++++++++++++++++++++++ ProductParse = ProductParse + '|' + strOtherColorProduct #params Params = g.xpath_text('//section[@class="card--params m15"]/table/tbody/tr') #++++++++++++++++++++++++++ #++++++++++++++++++++++++++ ProductParse = ProductParse + '|' + Params.encode('utf-8') f.write( ProductParse + '\n' ) print('Number i = ' + str(i) + ': ' + str(urlFile[i].rstrip('\n'))) except Exception: print('ERROR ON Number i = ' + str(i) + ': ' + str(urlFile[i].rstrip('\n'))) f.write( 'ERROR ON Number i = ' + str(i) + ': ' + str(urlFile[i].rstrip('\n')) + '\n') except KeyboardInterrupt : print('ERROR ON Number i = ' + str(i) + ': ' + str(urlFile[i].rstrip('\n'))) f.write( 'ERROR ON Number i = ' + str(i) + ': ' + str(urlFile[i].rstrip('\n')) + '\n') f.close() |
Шаг 3. Из описания продуктов я вытаскивал все ссылки на картинки и записывал их в отдельный файл с картинками ‘list_full_img.txt’. Далее запуска код Python для скачивания картинок:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
import urllib ''' url = "http://interyerus.ru/f/product/PE-01-02-3.jpg" imgname = url[url.rindex('/')+1:] img = urllib.urlopen(url).read() out = open(imgname, "wb") out.write(img) out.close ''' with open('list_full_img.txt') as f: urlimg= f.readlines() f.close f = open('log_img_not_download.txt', 'w') for i in range(31495, len(urlimg), 1): imgurl = str(urlimg[i].rstrip('\n')) print('Image i = ' + str(i) + ': ' + imgurl) try: imgname = imgurl[imgurl.rindex('/')+1:] #print(imgname) img = urllib.urlopen(imgurl).read() out = open(imgname, "wb") out.write(img) out.close except Exception: print('ERROR ON Number i = ' + str(i) + ': ' + str(imgurl[i].rstrip('\n'))) f.write( 'ERROR ON Number i = ' + str(i) + ': ' + str(imgurl[i].rstrip('\n')) + '\n') except KeyboardInterrupt : print('ERROR ON Number i = ' + str(i) + ': ' + str(imgurl[i].rstrip('\n'))) f.write( 'ERROR ON Number i = ' + str(i) + ': ' + str(imgurl[i].rstrip('\n')) + '\n') f.close() |
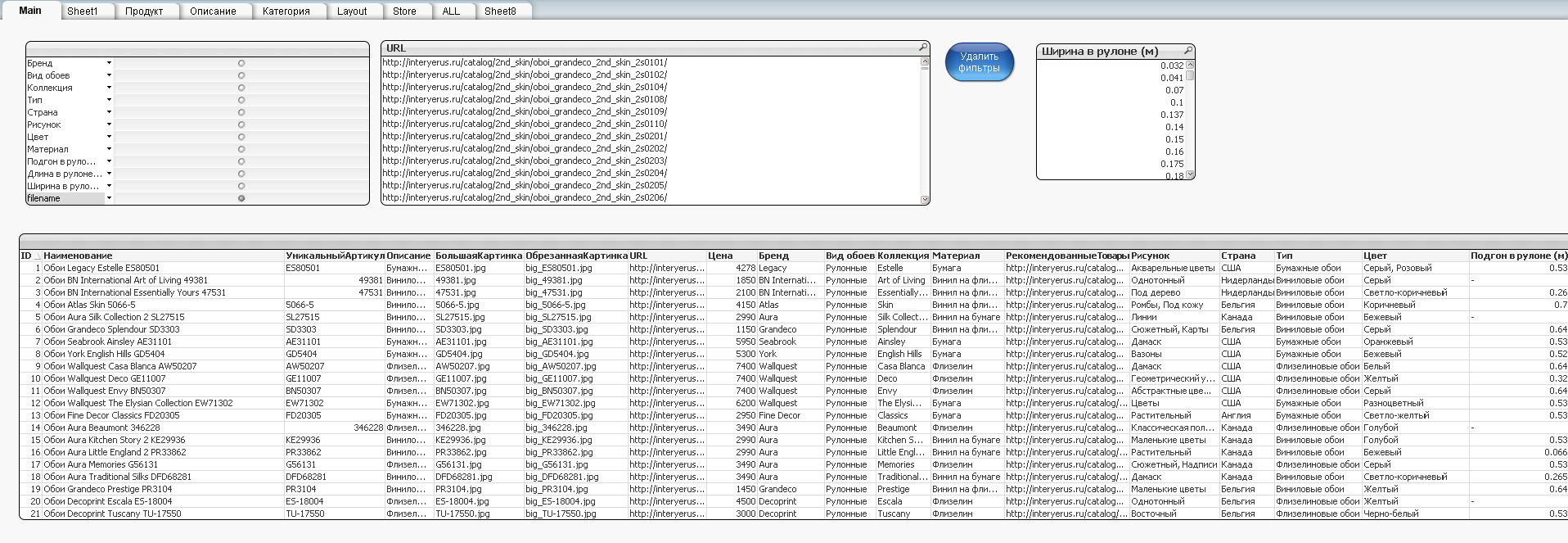
Шаг 4. Парсим информацию, полученную с сайтов, с помощью QlikView и вычленяем параметры продуктов:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 |
SET ThousandSep=' '; SET DecimalSep=','; SET MoneyThousandSep=' '; SET MoneyDecimalSep=','; SET MoneyFormat='# ##0,00 ₽;-# ##0,00 ₽'; SET TimeFormat='h:mm:ss'; SET DateFormat='DD.MM.YYYY'; SET TimestampFormat='DD.MM.YYYY h:mm:ss[.fff]'; SET MonthNames='янв;фев;мар;апр;май;июн;июл;авг;сен;окт;ноя;дек'; SET DayNames='Пн;Вт;Ср;Чт;Пт;Сб;Вс'; SET LongMonthNames='Январь;Февраль;Март;Апрель;Май;Июнь;Июль;Август;Сентябрь;Октябрь;Ноябрь;Декабрь'; SET LongDayNames='понедельник;вторник;среда;четверг;пятница;суббота;воскресенье'; SET FirstWeekDay=0; SET BrokenWeeks=1; SET ReferenceDay=0; SET FirstMonthOfYear=1; SET CollationLocale='ru-RU'; let product_id = 50; Data: LOAD 'vseoboi' as filename, @1 as URL, @2 as Наименование, @3 as Артикул, trim(mid(@3, 5)) as АРТИКУЛ, replace(replace(replace(@4,'руб',''),'.',''),' ','') as Цена, @5 as Описание, replace(@6,'http://interyerus.ru/f/product/','') as БольшаяКартинка, replace(@7,'http://interyerus.ru/f/product/','') as ОбрезаннаяКартинка, @8 as ФотоИнтерьер, @9 as РекомендованныеТовары, @10 as Характеристики, replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(@10,'Вид обоев:','|Вид обоев:'),'Страна:','|Страна:'),'Материал:','|Материал:'),'Рисунок:','|Рисунок:'),'Цвет:','|Цвет:'),'Подгон в рулоне(м):','|Подгон в рулоне(м):'),'Ширина в рулоне(м):','|Ширина в рулоне(м):'),'Длина в рулоне(м):','|Длина в рулоне(м):'),'Тип:','|Тип:'),'Коллекция:','|Коллекция:') as РазмеченныеХарактеристики FROM [C:\test_program\Python27\Project\Парсинг категорий\ALL\oboi_vseoboi_price_v1.txt] (txt, utf8, no labels, delimiter is '|', msq) WHERE index(@1,'ERROR')=0; Concatenate Data: LOAD 'vseoboi' as filename, @1 as URL, @2 as Наименование, @3 as АртикулПоле, trim(mid(@3, 5)) as АРТИКУЛ, replace(replace(replace(@4,'руб',''),'.',''),' ','') as Цена, @5 as Описание, replace(@6,'http://interyerus.ru/f/product/','') as БольшаяКартинка, replace(@7,'http://interyerus.ru/f/product/','') as ОбрезаннаяКартинка, @8 as ФотоИнтерьер, @9 as РекомендованныеТовары, @10 as Характеристики, replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(@10,'Вид обоев:','|Вид обоев:'),'Страна:','|Страна:'),'Материал:','|Материал:'),'Рисунок:','|Рисунок:'),'Цвет:','|Цвет:'),'Подгон в рулоне(м):','|Подгон в рулоне(м):'),'Ширина в рулоне(м):','|Ширина в рулоне(м):'),'Длина в рулоне(м):','|Длина в рулоне(м):'),'Тип:','|Тип:'),'Коллекция:','|Коллекция:') as РазмеченныеХарактеристики FROM [C:\test_program\Python27\Project\Парсинг категорий\ALL\oboi_vseoboi_price_v2.txt] (txt, utf8, no labels, delimiter is '|', msq) WHERE index(@1,'ERROR')=0; NoConcatenate Temp: LOAD RowNo() as ID, URL, Наименование, АРТИКУЛ as УникальныйАртикул, АРТИКУЛ as artcode, Цена, Описание, БольшаяКартинка, ОбрезаннаяКартинка, ФотоИнтерьер, РекомендованныеТовары, Характеристики, РазмеченныеХарактеристики Resident Data Where not Exists(УникальныйАртикул, АРТИКУЛ); DROP Table Data; RENAME Table Temp to Data; Subfields: LOAD ID, SubField(РазмеченныеХарактеристики,'|') as subfieldcol //replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(SubField(РазмеченныеХарактеристики,'|'),'Вид обоев:',''),'Страна:',''),'Материал:',''),'Рисунок:',''),'Цвет:',''),'Подгон в рулоне(м):',''),'Ширина в рулоне(м):',''),'Длина в рулоне(м):',''),'Тип:',''),'Коллекция:',''),'Бренд:','') as Параметр Resident Data; NoConcatenate Subfields_new: LOAD ID, subfieldcol, replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(subfieldcol,'Вид обоев:',''),'Страна:',''),'Материал:',''),'Рисунок:',''),'Цвет:',''),'Подгон в рулоне(м):',''),'Ширина в рулоне(м):',''),'Длина в рулоне(м):',''),'Тип:',''),'Коллекция:',''),'Бренд:','') as Параметр Resident Subfields; DROP Table Subfields; NoConcatenate Subfields: LOAD *, if( index(subfieldcol,'Бренд:')>0,'Бренд', if( index(subfieldcol,'Коллекция:')>0,'Коллекция', if( index(subfieldcol,'Тип:')>0,'Тип', if( index(subfieldcol,'Длина в рулоне')>0,'Длина в рулоне (м)', if( index(subfieldcol,'Ширина в рулоне')>0,'Ширина в рулоне (м)', if( index(subfieldcol,'Подгон в рулоне')>0,'Подгон в рулоне (м)', if( index(subfieldcol,'Цвет:')>0,'Цвет', if( index(subfieldcol,'Рисунок:')>0,'Рисунок', if( index(subfieldcol,'Материал:')>0,'Материал', if( index(subfieldcol,'Страна:')>0,'Страна', if( index(subfieldcol,'Вид обоев:')>0,'Вид обоев','yyyyyyyyyyyyy' ) ) ) ) ) ) ) ) ) ) ) as ParamName Resident Subfields_new; DROP Table Subfields_new; Left Join(Data) LOAD ID, Trim(replace(replace(replace(replace(replace([Параметр],chr(39),''),'+',' '),'&',' '),'.',''),':','')) as [Бренд] Resident Subfields Where ParamName='Бренд'; Left Join(Data) LOAD ID, Trim(replace(replace(replace(replace(replace(replace(replace([Параметр],chr(39),''),'+',' '),'&',' '),'.',''),':',''),'_',' '),'?',' ')) as [Коллекция] Resident Subfields Where ParamName='Коллекция'; Left Join(Data) LOAD ID, Trim(replace(replace(replace(replace(replace([Параметр],chr(39),''),'+',' '),'&',' '),'.',''),':','')) as [Тип] Resident Subfields Where ParamName='Тип'; Left Join(Data) LOAD ID, Trim(Параметр) as [Длина в рулоне (м)] Resident Subfields Where ParamName='Длина в рулоне (м)'; Left Join(Data) LOAD ID, Trim(Параметр) as [Ширина в рулоне (м)] Resident Subfields Where ParamName='Ширина в рулоне (м)'; Left Join(Data) LOAD ID, Trim(Параметр) as [Подгон в рулоне (м)] Resident Subfields Where ParamName='Подгон в рулоне (м)'; Left Join(Data) LOAD ID, Trim(Параметр) as [Цвет] Resident Subfields Where ParamName='Цвет'; Left Join(Data) LOAD ID, Trim(Параметр) as [Рисунок] Resident Subfields Where ParamName='Рисунок'; Left Join(Data) LOAD ID, Trim(Параметр) as [Материал] Resident Subfields Where ParamName='Материал'; Left Join(Data) LOAD ID, Trim(Параметр) as [Страна] Resident Subfields Where ParamName='Страна'; Left Join(Data) LOAD ID, Trim(Параметр) as [Вид обоев] Resident Subfields Where ParamName='Вид обоев'; DROP Table Subfields; NoConcatenate Temp: LOAD [artcode], [ID], ID + $(product_id) as product_id, [URL], [БольшаяКартинка], [Бренд], [Вид обоев], [Длина в рулоне (м)], [Коллекция], [Материал], [Наименование], [ОбрезаннаяКартинка], [Описание], [Подгон в рулоне (м)], [РазмеченныеХарактеристики], [РекомендованныеТовары], [Рисунок], [Страна], if(isnull([Тип]),'ОБОИ',[Тип]) as [Тип], [УникальныйАртикул], [ФотоИнтерьер], [Характеристики], [Цвет], [Цена], [Ширина в рулоне (м)], if(isnull([Тип]),'ОБОИ',[Тип]) & ' ' & [Бренд] & ' ' & [Коллекция] & ' - Артикул: ' & [artcode] & ' ' & [Страна] as СгенНаименование, 'В интернет-магазине ОБОИ DELUX Вы можете по лучшей цене купить ' & [Тип] & ' ' & [Бренд] & ' ' & [Коллекция] & ' - Артикул: ' & [artcode] & '. Коллекция ' &[Коллекция]& ' от бренда ' &[Бренд]& ', страна ' &[Страна]& '. Материал ' &[Материал]& '. Подробную таблицу с характеристиками смотрите ниже. По любым вопросам обращайтесь к консультанту на сайте или звоните нам по телефону - мы с радостью Вам поможем подобрать лучшие обои в рамках Вашего бюджета! :)' as [DESCRIPTION_PRODUCT], 'Флизелиновые обои, Виниловые обои, Детские обои, Обои настенные, Текстильные обои, Коллекции обоев, Элитные обои, Дизайнерские обои, Эксклюзивные обои, Доставка, Обои, Флизелин, Бумага, винил на флизелине' as Keywords Resident Data; DROP Table Data; RENAME Table Temp to Data; NoConcatenate TEMP: LOAD ID, SubField(ФотоИнтерьер,';') as ФотоИнтерьер2 Resident Data; NoConcatenate ФотоИнтерьер: LOAD ID, ФотоИнтерьер2 Resident TEMP Where ФотоИнтерьер2 <> ''; DROP Table TEMP; //Цвет NoConcatenate TEMP: LOAD ID, Trim(SubField(Цвет,',')) as ЦветРаздельно Resident Data; NoConcatenate ColorTbl: LOAD ID, ЦветРаздельно Resident TEMP Where ЦветРаздельно <> ''; DROP Table TEMP; //Рисунок NoConcatenate TEMP: LOAD ID, Trim(SubField(Рисунок,',')) as РисунокРаздельно Resident Data; NoConcatenate RisunokTbl: LOAD ID, РисунокРаздельно Resident TEMP Where РисунокРаздельно <> ''; DROP Table TEMP; |
И еще один участок кода для генерации SQL-кода для заливки информации на платформу OpenCart (бесплатный движок для интернет-магазина), также написано на QlikView:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
//oc_product.sql oc_product: LOAD ID, 'INSERT INTO `oc_product` (`product_id`, `model`, `sku`, `upc`, `ean`, `jan`, `isbn`, `mpn`, `location`, `quantity`, `stock_status_id`, `image`, `manufacturer_id`, `shipping`, `price`, `points`, `tax_class_id`, `date_available`, `weight`, `weight_class_id`, `length`, `width`, `height`, `length_class_id`, `subtract`, `minimum`, `sort_order`, `status`, `viewed`, `date_added`, `date_modified`, `oct_product_stickers`) VALUES (' &chr(39)& product_id &chr(39)& ','&chr(39)&[Тип]&chr(39)&','&chr(39)&[artcode]&chr(39)&','''', '''', '''', '''', '''',''Москва'',''245'',''5'',''catalog/main/'&[ОбрезаннаяКартинка]&chr(39)&','''',''1'','&chr(39)&[Цена]&chr(39)&',''0'', ''0'', ''2017-01-29'', ''0.00000000'', ''1'','&chr(39)&[Длина в рулоне (м)]&chr(39)&','&chr(39)&[Ширина в рулоне (м)]&chr(39)&','&chr(39)&[Подгон в рулоне (м)]&chr(39)&',''1'', ''1'', ''1'', ''1'', ''1'', ''0'', ''2017-01-29 17:50:53'', ''2017-01-29 23:02:00'', '''');' as SQL_oc_product Resident Data; //oc_product_description.sql oc_product_description: LOAD ID, 'INSERT INTO `oc_product_description` (`product_id`, `language_id`, `name`, `description`, `tag`, `meta_title`, `meta_description`, `meta_keyword`) VALUES ('&chr(39)&product_id&chr(39)&', ''1'', '&chr(39)&СгенНаименование&chr(39)&', ''<p>'&[DESCRIPTION_PRODUCT]&'</p>'', '&chr(39)&Keywords&chr(39)&', '&chr(39)&СгенНаименование&chr(39)&', '&chr(39)&[DESCRIPTION_PRODUCT]&chr(39)&', '&chr(39)&Keywords&chr(39)&');' as SQL_description Resident Data; //oc_product_to_category oc_product_to_category: LOAD ID, 'INSERT INTO `oc_product_to_category` (`product_id`, `category_id`) VALUES ('&chr(39)&product_id&chr(39)&', ''59'');' as SQL_product_to_category Resident Data; //oc_product_to_layout oc_product_to_layout: LOAD ID, 'INSERT INTO `oc_product_to_layout` (`product_id`, `store_id`, `layout_id`) VALUES ('&chr(39)&product_id&chr(39)&', ''0'', ''2'');' as SQL_oc_product_to_layout Resident Data; //oc_product_to_store oc_product_to_store: LOAD ID, 'INSERT INTO `oc_product_to_store` (`product_id`, `store_id`) VALUES ('&chr(39)&product_id&chr(39)&', ''0'');' as SQL_oc_product_to_store Resident Data; |
Получаем некую аналитическую модель по продукции для заливки на любые платформы интернет-магазинов таких как OpenCart, Bitrix и т.д.
Еще один пример парсинга сайта на Python с библиотекой Grab()
Ниже приведен пример получения списка продуктов (парсим их из каталога сайта и пишем в файл). По идее нужно дополнительно написать парсер для страницы с продуктом. Этого сделать не успел, поэтому сохраняю тут код недоделанный:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 |
from grab import Grab g = Grab() cataloglist1=[] startURL='https://www.zzz24.com/' flag = 0 g.go(startURL) nextURL = g.xpath_list('//div[@class="tab-pane active"]/a/@href') #print(cataloglist1) for i in range(0, len(nextURL), 1): cataloglist1.append(nextURL[i]) #================================================== #-------------------------------------------------- #================================================== cataloglist2=[] for j in range(0, len(cataloglist1), 1): g.go(cataloglist1[j]) nextURL = g.xpath_list('//div[@class="tab-pane active"]/a/@href') for i in range(0, len(nextURL), 1): cataloglist2.append(nextURL[i]) #================================================== #-------------------------------------------------- #================================================== cataloglist3=[] for j in range(0, len(cataloglist2), 1): g.go(cataloglist2[j]) nextURL = g.xpath_list('//div[@class="tab-pane active"]/a/@href') for i in range(0, len(nextURL), 1): cataloglist3.append(nextURL[i]) #================================================== #-------------------------------------------------- #================================================== f = open('cataloglist1_URL.txt', 'w') for q in range(0, len(cataloglist1), 1): f.write( str(cataloglist1[q]) + '\n' ) f.close() f = open('cataloglist2_URL.txt', 'w') for q in range(0, len(cataloglist2), 1): f.write( str(cataloglist2[q]) + '\n' ) f.close() f = open('cataloglist3_URL.txt', 'w') for q in range(0, len(cataloglist3), 1): f.write( str(cataloglist3[q]) + '\n' ) f.close() #================================================== #-------------------------------------------------- #================================================== productlist=[] for j in range(0, len(cataloglist3), 1): print('\n') print(cataloglist3[j]) g.go(cataloglist3[j]) nextURL = g.xpath_list('//div[@class="tab-pane active"]/div/div/div/a/@href') for i in range(0, len(nextURL), 1): productlist.append(nextURL[i]) print(productlist) #write to file all url with spalnya product f = open('productURL.txt', 'w') for q in range(0, len(productlist), 1): f.write( str(productlist[q]) + '\n' ) f.close() |

