<<< Вернуться в основной раздел «QlikView — краткий учебник»
Contents
- 1 Анализ Множеств (Set Analysis) в QlikView
- 2 Синтаксис анализа множеств (Set Analysis) в QlikView
- 2.1 Идентификаторы множества
- 2.2 Операторы множества
- 2.3 Модификаторы множества
- 2.3.1 Модификаторы множества с операторами множества
- 2.3.2 Модификаторы множества с помощью назначений с неявными операторами множества
- 2.3.3 Модификаторы множества с расширениями со знаком доллара
- 2.3.4 Модификаторы множества с расширенными поисками
- 2.3.5 Модификаторы множества с неявными определениями значений поля
- 2.4 Синтаксис для множеств
- 2.5 Использование переменных в Set Analysis
- 2.6 Использование функций в модификаторе Set Analysis (QlikView)
- 2.7 Видео-материалы по Set Analysis в QlikView
- 3 Где и в каких случаях используется Set Analysis в QlikView на практике?
- 4 Большая картинка по анализу множеств в QlikView (Set Analysis)
- 5 Примеры Set Analysis в QlikView
- 6 Сложные примеры по Set Analysis в QlikView
- 7 Литература по SET ANALYSIS
Анализ Множеств (Set Analysis) в QlikView
Анализ Множеств (Set Analysis) — одна из основ для построения сложных приложений QlikView. В этой статье рассматриваются инструменты управления Set Analysis.
Что такое множество в QlikView?
Представим, что наше приложение состоит из таблицы фактов и нескольких измерений (схема «Звезда»). Пусть все данные таблицы фактов разделены на два уровня с помощью измерения «Уровни данных»:
- 1 уровень «Первоначально загруженные данные» — это факты, которые были загружены из источников данных;
- 2 уровень «Обработанные данные» — это данные, которые были получены из первичных данных в ходе тех или иных вычислений.
Допустим, что нам нужно отобразить на графике «Выручка от продаж» («Выручка от продаж» — это элемент измерения «Статьи»), при этом данные необходимо получить с уровня «Первоначально загруженные данные». Т.е. фактически нам необходимо работать с ограниченным набором данных из таблицы фактов. Вот тут то нам и приходит на помощь такой инструмент, как множества.
Итак, множество — это ограниченный набор данных, который мы задаем с помощью специального синтаксиса.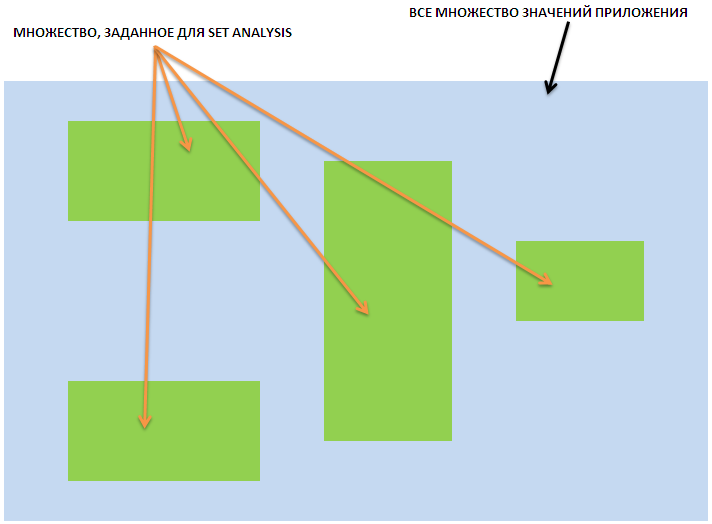
Анализ множеств (Set Analysis) позволяет обрабатывать ограниченный набор данных, на которые не влияют текущие выбранные данные (фильтры, которые мы применили к данным в нашем приложении).
Фактически, множества задают контекст в expression, в разрезе которого мы анализируем данные.

Синтаксис анализа множеств (Set Analysis) в QlikView
Множества описываются в QlikView при помощи фигурных скобок {}.
Пример записи множества:
|
1 |
sum({<region= {'Ярославская область','Владимирская область'}, productgroup={'Ноутбуки','Телефоны','Планшеты'}>} Sales) |
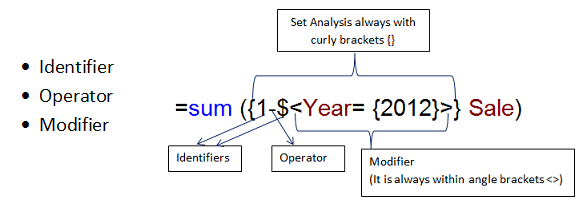

Далее описываются основные синтаксические элементы, которые используются для задания или модификации множества.
Идентификаторы множества
Знак 0 — описывает пустое множество.
Знак 1 — описывает полное множество всех записей в приложении.
Знак $ — представляет записи текущей выборки.
Рассмотрим выражения, которые можно формировать с помощью идентификаторов:
Выражение {$} указывает на текущую выборку.
Выражение {1-$} обозначает отрицание текущей выборки, т.е. множество, которое образуется путем исключения из всех значений приложения текущей выборки.
Выражение {$1} представляет предыдущую выборку, т.е. эквивалентно нажатию кнопки «Назад».
Выражение {$_1}, {$_2} … {$_N} представляет следующие выборки, т.е. на один, два … N шагов вперед, т.е. эквивалентно нажатию кнопки «Вперед». В уведомлениях Назад и Вперед может быть использовано любое целое без знака. Выражение {$_0} представляет текущую выборку.
Выражение {1} игнорируется текущая выборка (за множество данных берутся все строки приложения). Измерение не игнорируется.
Выражение {1} Total — игнорируется и текущая выборка, и измерение.
Выражение {MyBookMark} — множество содержит набор значений, которое образуется фильтрами, сохраненными в закладке «MyBookmark» приложения QlikView.
Group – Название группы, альтернативное состояние (Alternate State)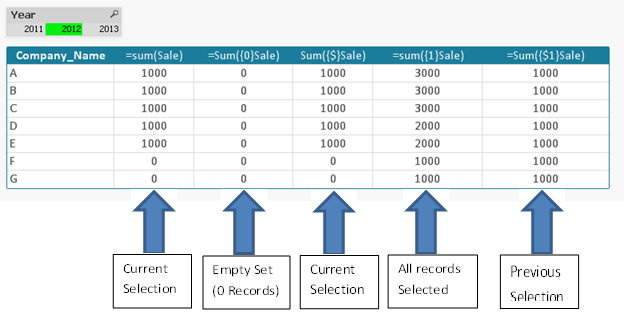
Операторы множества
Над множествами можно производить операции, которые описываются операторами. В результате применения операторов над операндами (множествами) образуется новое множество. В QlikView используются следующие типы операторов:
+ Union (Объединение). Оператор объединения множеств. Т.е. множество записей A + множество записей B = множество записей C.
— Exclusion (Исключение). Оператор вычитание одного множества записей из другого множества записей. Т.е. множество записей A — множество записей B = множество записей D.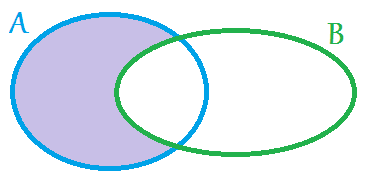
* Intersection (Пересечение). Оператор, который образует множество, которое принадлежит каждому множеству, над которым выполняется данная операция. Т.е. множество записей A * множество записей B = множество записей E.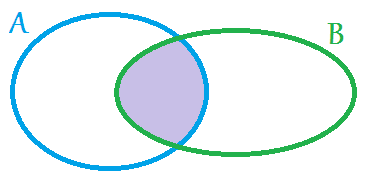
/ Symmetric difference XOR (Исключающее ИЛИ). Образуется множество, которое не содержит общих записей двух множеств. Т.е. множество записей A / множество записей B = множество записей F.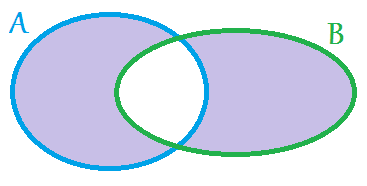
Примеры:
- Выражение {1-$} описывает все записи приложения, исключая текущую выборку.
- Выражение {$*MyBookMark} описывает множество, образованное текущей выборкой и закладкой «MyBookMark».
- Выражение {-($+MyBookMark)} описывает множество всех значений в приложении, исключая множество значений, образованное текущей выборкой и закладкой «MyBookMark».
Модификаторы множества
Множество может быть изменено дополнительной или переобозначенной выборкой. Подобное изменение может быть записано в выражении множества. Модификатор состоит из одного или нескольких имен полей, за каждым из которых следует выборка, которая должна быть составлена на основе поля и заключена в < и >. Например: <Year={2007,2008},Region={‘Владимирская область’}>.
Имена и значения полей могут цитироваться как обычно. Например: <[Регион продаж]={‘Московская область’, ‘Ленинградская область’}>.
Существует несколько способов определения выборки:
1) Первый случай (редко используется) — это выборка, основанная на выбранных значениях другого поля.
Например: <[Дата заказа] = [Дата поставки]>. Данный модификатор возьмет выбранные значения из [Дата поставки] и применит их в качестве выборки к [Дата заказа]. Если присутствует множество уникальных значений (больше пары сотен), то данная операция потребует ресурсов CPU, поэтому ее следует избегать.
2) Наиболее распространенным случаем является второй — выборка, основанная на списке значений полей, заключенном в фигурные скобки, значения разделены запятыми.
Например: <Year = {2007, 2008}>. Здесь фигурные скобки определяют множество элементов, в котором элементы могут быть либо значениями полей, либо поисками значений полей. Поиск всегда определяется использованием двойных кавычек. Например, <Ingredient = {‘*чеснок*’}> выберет все ингредиенты, где есть подстрока ‘чеснок’. Поиски чувствительны к регистру, а также выполняются для всех исключенных значений.
Пустые множества элементов, которые заданы явно, например <Product = {}>, или которые заданы неявно, например <Product = {‘Perpetuum Mobile’}>, означают, что продукция отсутствует, поэтому результатом будет множество записей, не связанных с каким-либо продуктом. Обратите внимание, что данное множество может быть достигнуто с помощью обычных выборок, кроме случаев, когда выборка сделана в другом поле.
3) При необходимости для принудительного исключения определенных значений поля требуется использовать знак ‘~’ (тильда) перед именем поля.
4) Модификатор множества может использоваться на идентификаторе множества или сам по себе. Он не может использоваться на выражении множества. При использовании на идентификаторе множества модификатор должен быть записан сразу после идентификатора множества. Например: {$<Year = {2007, 2008}>}. При использовании модификатора самого по себе он интерпретируется как изменение текущей выборки.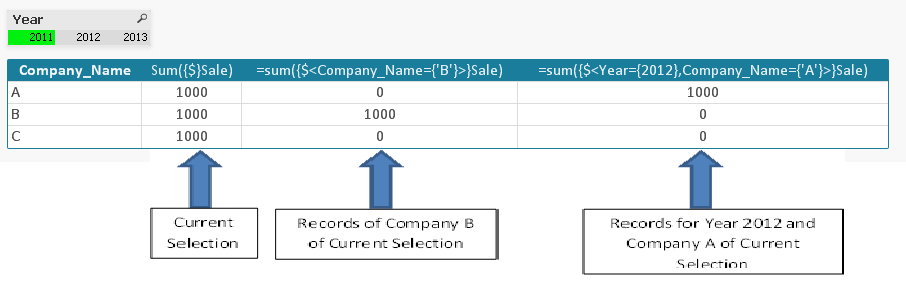
Примеры:
- sum({1<Region= {‘Владимирская область’} >} Sales) данное выражение возвращает продажи для региона ‘Владимирская область’, при этом текущая выборка игнорируется.
- sum({$1<Region = >} Sales) возвращает продажи для текущей выборки, при этом выборка по измерению ‘Region’ удаляется.
- sum({<Region = >} Sales) возвращает то же самое, что и в примере sum({$} Sales). Если в модификаторе отсутствует указанное множество, то используется знак $.
- sum({$<Year = {‘2013′,’2014′,’2015’}, Region = {‘Ярославская область’,’Владимирская область’,’Смоленская область’}>} Sales) возвращает продажи для текущей выборки, но с новыми выборками в по измерениям «Year» и «Region».
- sum({$<~Ingredient = {‘*чеснок*’}>} Sales) возвращает продажи для текущей выборки, но с принудительным исключением все ингредиентов, содержащих подстроку ‘чеснок’.
- sum({$<Year = {‘201*’,’199*’}>} Sales) возвращает продажи для текущей выборки, но по измерению Year берутся все года, которые начинаются на ‘201*’ и на ‘199*’, т.е. в измерении ‘Year’ выбраны диапазоны 1990-1999 и 2010-2019 (все года, которые больше текущего, могут содержать прогнозные данные, если Ваша модель это предполагает).
- sum($<Year = {‘>$2001<2007’}>} Sales) данный пример возвращает продажи для текущей выборки, но года берутся в диапазоне ‘больше 2001 года’ и ‘меньше 2007 года’.
Внимание: <Region = > не эквивалентно выражению <Region = {}>, т.к. в первом случае фильтры будут сброшены (выборка по региону будет сброшена), а во втором случае выражение будет интерпретироваться как ‘взять все записи, у которых Region является пустым полем (регион отсутствует)’.
Модификаторы множества с операторами множества
Выборка в поле может быть определена с помощью операторов множества при работе с различными множествами элементов.
Например, модификатор <Year = {’20*’, 1997} — {2000}> выберет все года, начиная с «20» в дополнение к «1997», кроме«2000».
Модификаторы множества с помощью назначений с неявными операторами множества
Необходимо образовать выборку на текущей выборке и добавить несколько значений.
Например, выражение <Year = Year + {2007, 2008}> можно получить с помощью выражения <Year += {2007, 2008}>. Т.е. оператор назначения неявно определяет объединение. Также неявные «пересечения», «исключения» и «Исключающее ИЛИ» могут быть определены с помощью “*=”, “–=” и “/=”.
Модификаторы множества с расширениями со знаком доллара
В выражениях множества могут использоваться переменные и другие множества со знаком доллара.
Примеры:
- sum({$<Year = {$(#vLastYear)}>} Sales) возвращает продажи для предыдущего года в отношении текущей выборки. Здесь переменная vLastYear, содержащая соответствующий год, используется в множестве со знаком доллара.
- sum({$<Year = {$(#=Only(Year)-1)}>} Sales) возвращает продажи для предыдущего года в отношении текущей выборки. Здесь множество со знаком доллара используется для расчета предыдущего года.
Модификаторы множества с расширенными поисками
Для определения множеств могут использоваться расширенные поиски с помощью подстановочных знаков и агрегирований.
Примеры:
- sum({$–1<Product = {‘*Internal*’, ‘*Domestic*’}>} Sales) возвращает продажи для текущей выборки, за исключением продуктов с подстрокой «Internal» или «Domestic» в имени продукта.
- sum({$<Customer = {‘=Sum({1<Year = {2015}>} Sales ) > 1000000’}>} Sales) возвращает продажи для текущей выборки, но с новой выборкой в поле «Customer»: только клиенты с общими продажами более 1000000 за 2015 год.
Модификаторы множества с неявными определениями значений поля
Существует дополнительный способ определения множества значений поля, используя вложенное определение множества.
В подобных случаях должны использоваться функции элемента P() и E(), представляющие множество элементов возможных значений и исключенные значения поля, соответственно. В скобках можно указать одно выражение множества и одно поле.
Например: P({1} Customer). Эти функции не могут использоваться в других выражениях.
Примеры:
- sum({$<Customer = P({1<Product={‘Shoe’}>} Customer)>} Sales) возвращает продажи для текущей выборки, но только тех клиентов, которые когда-то покупали продукт «Shoe». Здесь функция элемента P( ) возвращает список возможных клиентов, подразумеваемых выборкой «Shoe» в поле Product.
- sum({$<Customer = P({1<Product={‘Shoe’}>})>} Sales) то же, что и в примере выше. Если в функции элемента поле опущено, функция вернет возможные значения для поля, указанного во внешнем назначении.
- sum({$<Customer = P({1<Product={‘Shoe’}>} Supplier)>} Sales) возвращает продажи для текущей выборки, но только клиентов, поставлявших когда-либо продукт «Shoe». Здесь функция элемента P( ) возвращает список возможных поставщиков, подразумеваемых выборкой «Shoe» в поле Продукция. Список поставщиков затем используется в качестве выборки в поле Клиент.
- sum({$<Customer = E({1<Product={‘Shoe’}>})>} Sales) возвращает продажи для текущей выборки, но только клиентов, никогда не покупавших продукт «Shoe». Здесь функция элемента E( ) возвращает список клиентов, исключенных выборкой «Shoe» в поле Продукция.
Синтаксис для множеств
Полный синтаксис (не включая дополнительное использование стандартных скобок для определения последовательности) выглядит следующим образом:
- set_expression ::= {set_entity {set_operator set_entity}}
- set_entity ::= set_identifier [set_modifier]
- set_identifier ::= 1 | $ | $N | $_N | bookmark_id | bookmark_name
- set_operator ::= + | — | * | /
- set_modifier ::= <field_selection {,field_selection}>
- field_selection ::= field_name [ = | += | ¬–= | *= | /= ] element_set_expression
- element_set_expression ::= element_set {set_operator element_set}
- element_set ::= [field_name] | {element_list} | element_function
- element_list ::= element {, element}
- element_function ::= (P|E) ([set_expression] [field_name])
- element ::= field_value| «search_mask»
Использование переменных в Set Analysis
Зададим переменные в скрипте загрузки данных:
|
1 2 3 |
SET vYearMin = 2004; SET vYearMax = 2014; SET vYearCurr = 2015; |
В диаграммах можно задать следующие формулы с применением Set Analysis:
|
1 |
=SUM({$ <Год = {'>=$(vYearMin)<=$(vYearMax)'}>} Продажи) |
Данное выражение вычисляет продажи, которые соответствуют текущей выборке, при этом значение измерения Год будет задано в интервале от vYearMin до vYearMax (т.е. от 2004 года до 2014 года включительно).
|
1 |
=SUM({$ <Год = {'$(vYearCurr)'}>} Продажи) |
Данное выражение вычисляет продажи, которые соответствуют текущей выборке, при этом значение измерения Год равно vYearCurr (т.е. 2015).
Использование функций в модификаторе Set Analysis (QlikView)
|
1 |
sum( {$<Year = {$(=Only(Year)-1)}>} Sales ) |
Данное выражение возвращает число продаж за предыдущий год по отношению к выбранному году. Год должен быть выбран в единственном числе, иначе выражение не рассчитается.
Видео-материалы по Set Analysis в QlikView
Где и в каких случаях используется Set Analysis в QlikView на практике?
Анализ множеств (Set Analysis) очень часто требуется при работе с визуализацией данных. Если в скриптах можно использовать те же выражения «where», то при проектировании диаграмм крайне необходимо понимание как задается и используется множество. Ниже приведен краткий пример настройки круговой диаграммы с отображением доли выручки от продаж по продуктам: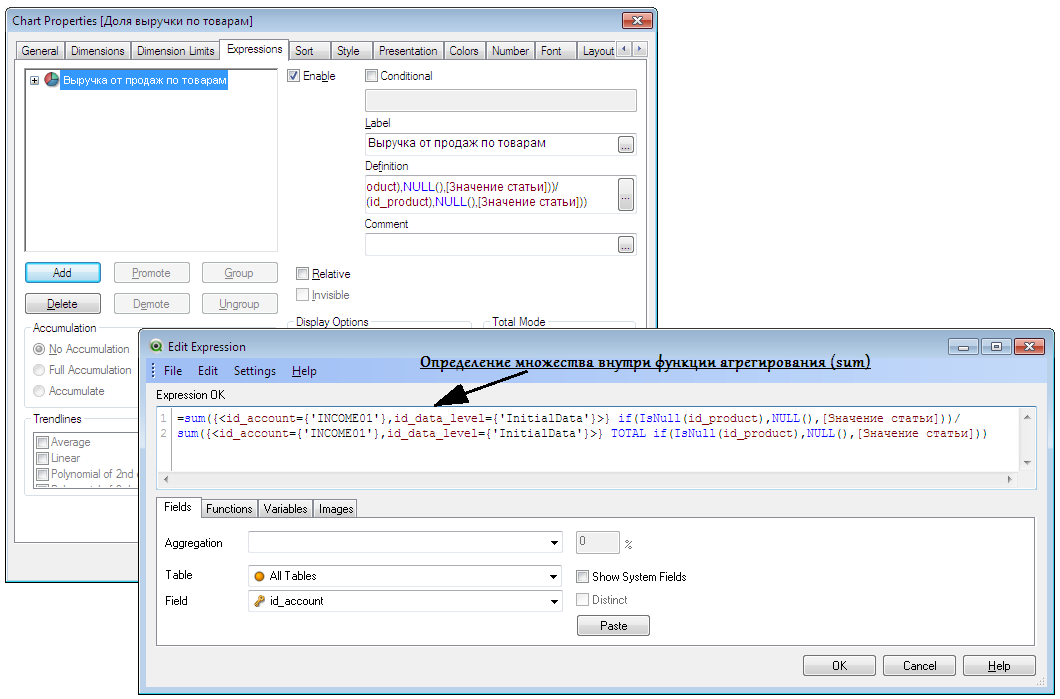
Большая картинка по анализу множеств в QlikView (Set Analysis)

Примеры Set Analysis в QlikView
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
Count ({$<[Academic Year] = {'2011/2'} > }DISTINCT [Visitors Count]) Count({$<[Academic Year]={'2011/2'}>}DISTINCT [Visitors Count])/Count( total{$<[Year Code]={'2011/2'},[Service Type] = , [Visit Category] = ,[Visit Subject] = , [Academic Year]= , Month = , MonthYear= >} DISTINCT [All Students Count]) Count (DISTINCT [Visitors Count]) Count (DISTINCT [Visitors Count])/Count ( {$< [Year Code] ={"=$(vTest)" }, [Academic Year] = , [Service Type] = , [Visit Category] = , [Visit Subject] = , Month= , MonthYear= >}DISTINCT([All Students Count])) Count({<[Visitors Count]=P({<[Service Type]={'ASC'}>}[Visitors Count])>*<[Visitors Count]=P({<[Service Type]={'UniDesk'}>}[Visitors Count])>} distinct [VisitorsCount]) Count({<[Visitors Count]=P({<[Service Type]={'ASC'}>}[Visitors Count])>*< [Visitors Count]=P({<[Service Type]={'UniDesk'}>}[Visitors Count])>} distinct [Visitors Count])/ Count ( {$< [Year Code] ={"=$(vTest)" }, [Academic Year] = , [Service Type] = , [Visit Category] = , [Visit Subject] = , Month= , MonthYear= >} DISTINCT([All Students Count])) count({<[Visit Subject]=[Visit Subject]-[Associate Visit Subject], [Academic Year]= {"$(vMarketTest)"}>}distinct([Associate Student])) |
Сложные примеры по Set Analysis в QlikView
|
1 2 3 4 5 6 7 |
=sum({<Дата={"<=$(=Today())"}>} [Количество]) =sum({<Дата={">=$(=Date('$(пПериод1)'))"}>*<Дата={"<=$(=Date('$(пПериод2)'))"}>} [Количество]) =sum({<Дата=[АльтернативноеСостояние0]::Дата>+<Дата=[АльтернативноеСостояние1]::Дата>+<Дата=[АльтернативноеСостояние2]::Дата>+<Дата=[АльтернативноеСостояние3]::Дата>} [Количество]) =sum({<Дата={">=$(=Date('$(пПериод1)'))"}>*<Дата={"<=$(=Date('$(пПериод2)'))"}>*<[Клиент ID]={$(=Concat({$} DISTINCT chr(39)&[КлиентПоКаналуПродаж ID]&chr(39),','))}>} [Сумма]) |
Литература по SET ANALYSIS
- Анализ множеств в QlikView — описание (Set Analysis).pdf
- Обучающая презенташка — QlikView Set Analysis.pdf
<<< Вернуться в основной раздел «QlikView — краткий учебник»